Создание гистограмм, графиков и диаграмм с областями в PowerPoint :: think-cell
- 7.1
- Гистограмма и гистограмма с накоплением
- 7.2
- Диаграмма с группировкой
- 7.3
- 100%–диаграмма
- 7.4
- График
- 7.5
- Пределы погрешностей
- 7.6
- Диаграмма с областями 100%-диаграмма с областями
- 7.7
- Смешанная диаграмма
7.1 Гистограмма и гистограмма с накоплением
| Значок в меню «Элементы»: |
В think-cell нет отличия между простыми гистограммами и гистограммами с накоплением. Если вы хотите создать простую гистограмму, введите только один ряд (одну строку) данных в таблице. Чтобы быстро ознакомиться с гистограммами, изучите пример в главе Введение в создание диаграмм.
Линейчатые диаграммы в think-cell — это просто повернутые гистограммы, которые можно использовать точно так же. Кроме того, вы можете создавать диаграммы-бабочки
Инструкции по созданию диаграммы с накоплением и группировкой см. в разделе Диаграмма с группировкой.
Чтобы изменить ширину столбца, выберите сегмент и перетащите один из маркеров к половине высоты столбца.
В подсказке отображается полученный во время перетаскивания промежуток. Чем шире столбец, тем меньше промежуток и наоборот, так как ширина диаграммы не меняется при изменении ширины столбцов. Ширина промежутка отображается как процент от ширины столбца, то есть 50 % означает, что ширина каждого промежутка равна половине ширине столбца.
Изменение ширины одного столбца приведет к изменению ширины всех других столбцов.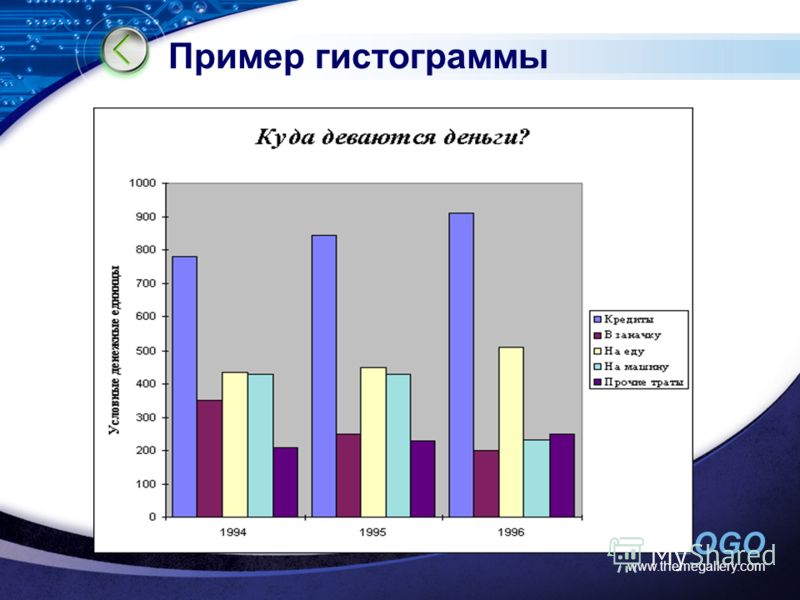 Ширина всех столбцов всегда одинакова. Сведения о диаграмме с различной шириной столбцов, которая зависит от данных, см. в разделе Диаграмма Mekko. Сведения о том, как сделать отдельные промежутки шире, см. в разделе Промежуток между категориями.
Ширина всех столбцов всегда одинакова. Сведения о диаграмме с различной шириной столбцов, которая зависит от данных, см. в разделе Диаграмма Mekko. Сведения о том, как сделать отдельные промежутки шире, см. в разделе Промежуток между категориями.
7.2 Диаграмма с группировкой
| Значок в меню «Элементы»: |
Диаграмма с группировкой — это вариант гистограммы с накоплением, в которой сегменты расположены рядом друг с другом.
Диаграмму с группировкой можно объединить с графиком, выбрав сегмент с рядом и выбрав параметр График в элементе управления типом диаграммы этого ряда.
Чтобы разместить группы сегментов рядом, можно создать диаграмму с накоплением и группировкой.
Чтобы создать диаграмму с накоплением и группировкой, выполните следующие действия.
- Вставьте диаграмму с накоплением.
- Выберите сегмент и перетащите маркер ширины столбца на половину высоты столбца, пока в подсказке не появится строка «Промежуток 0 %».
- Нажмите на базовую линию, где требуется вставить промежуток, и перетащите стрелку вправо, пока в подсказке не появится строка «Промежуток категории 1». Эти действия необходимо повторить для всех кластеров.
Если число столбиков в кластере четное, метку нельзя выровнять по центру для всего кластера. В этом случае используйте текстовое поле PowerPoint в качестве метки.
7.3 100%–диаграмма
| Значок в меню «Элементы»: |
100%-диаграмма — это вариант гистограммы с накоплением, в которой все столбцы обычно дополняются до одинаковой высоты (например, до 100 %). Метки 100%-диаграммы поддерживают свойство содержимого метки, которое позволяет выбрать, будут ли отображаться абсолютные значения, проценты или и то, и другое (Содержимое меток).
С помощью think-cell можно создавать 100%-диаграммы, значения столбцов которой необязательно равно 100 %.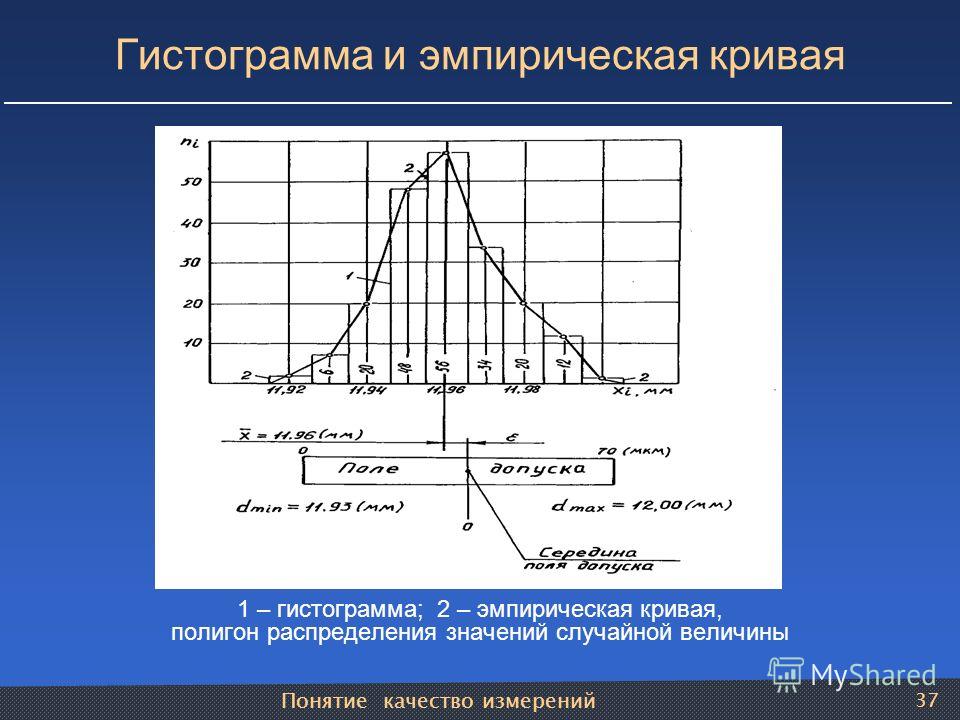
7.4 График
| Значок в меню «Элементы»: |
График использует линии для соединения точек данных, которые относятся к одному ряду данных. Внешний вид графика определяют элементы управления схемой линий, типом линии и фигурой маркера на перемещаемой панели инструментов. Дополнительные сведения об этих элементах управления см. в разделе Форматирование и стили. Метки для точек данных по умолчанию не отображаются, но их можно включить с помощью кнопки Добавить метку точки в контекстном меню графика.
Если значения категории графика — это строго увеличивающиеся числа или даты и их можно интерпретировать таким образом в соответствии с форматом числа метки оси, тогда ось X автоматически изменится на ось значений (см. раздел Ось значений). Если используются даты, формат даты можно изменить, выбрав все метки категорий (см. раздел Множественный выбор) и введя формат в элементе управления (см. раздел Коды форматов дат). Чтобы отобразить больше меток, чем помещается по горизонтали, можно использовать поворот меток (см. раздел Поворот метки).
Горизонтальная ось может переключиться с режима категории на режим значений, только если выполняются следующие условия.
- Все ячейки категорий в таблице содержат числа, а в качестве формата ячеек Excel выбрано значение Общий или Число либо все ячейки категорий в таблице содержат даты, а в качестве формата ячеек Excel выбрано значение Дата.
- Числа или даты в ячейках категорий строго увеличиваются слева направо.
-
Для оси Y не включен параметр Клетки между категориями (см. раздел Размещение оси значений). Если только это требование мешает перейти в режим оси значений, вы можете использовать параметр Сделать осью значений в контекстном меню оси, чтобы включить параметр Клетки на категориях и тем самым включить режим оси значений.
На графике также может отображаться вторая вертикальная ось значений. Дополнительные сведения см. в разделе Вторая ось.
Если выбран параметр Использовать функцию «Заполнять сверху» Excel (см. раздел Цветовая схема), цвет заливки в параметрах форматирования Excel используется следующим образом.
- Цвет заливки ячейки, содержащей имя ряда, определяет цвет линии.
- Цвет заливки ячейки каждой точки данных определяет цвет этой точки данных.
7.4.1 Сглаженные линии
Если вы хотите, чтобы линии на графике были сглажены, включите этот параметр. Сначала нажмите правой кнопкой мыши на нужную линию, а затем нажмите кнопку Преобразовать в гладкий график.
7.4.2 Интерполяция
На графиках, диаграммах с областями и 100%-диаграммах кнопку Интерполировать можно использовать для отображения диаграммы с линейной интерполяцией всех отсутствующих в ряду данных значений. На графиках интерполяцию можно включить и отключить для отдельных рядов на диаграмме. На диаграммах с областями ее можно использовать только для всей диаграммы, так как ряды расположены друг над другом.
7.5 Пределы погрешностей
Пределы погрешностей можно использовать для обозначения отклонений на графиках и диаграммах с накоплением. С помощью пределов погрешностей можно создать следующую диаграмму.
- Создайте график с тремя рядами данных. Первый ряд обозначает верхнее отклонение, второй ряд — среднее отклонение, а третий ряд — нижнее отклонение.
- Щелкните правой кнопкой мыши центральную линию и выберите Добавить пределы погрешностей в контекстном меню.
- Удалите метки для верхнего и нижнего ряда.
Выберите один из пределов погрешностей, чтобы изменить фигуру и цвет маркера для верхнего и нижнего отклонения, а также тип линии для всех пределов погрешностей. Вы также можете выбрать отдельный маркер предела погрешностей, чтобы изменить только его свойства.
При выборе предела погрешностей на каждом его конце появляется маркер. Их можно перетащить, чтобы выбрать, какие линии должны охватывать пределы погрешностей. Вы также можете отобразить интервалы вместо отклонений вокруг центрального значения, если предел погрешностей будет охватывать только две смежные линии.
Их можно перетащить, чтобы выбрать, какие линии должны охватывать пределы погрешностей. Вы также можете отобразить интервалы вместо отклонений вокруг центрального значения, если предел погрешностей будет охватывать только две смежные линии.
7.6 Диаграмма с областями 100%-диаграмма с областями
7.6.1 Диаграмма с областями
| Значок в меню «Элементы»: |
Диаграмма с областями можно представить графиком с накоплением, в котором точки данных представляют сумму значений категорий, а не отдельные значения. Внешний вид диаграмм с областями настраивается с помощью элемента управления цветовой схемой. Метки для точек данных по умолчанию не отображаются, но их можно включить с помощью кнопки Добавить метку точки в контекстном меню диаграммы с областями. Кнопку Добавить итоги в контекстном меню диаграммы с областями можно использовать для отображения меток с итоговыми значениями. Вы можете включить линейную интерполяцию, нажав кнопку Интерполировать (см. раздел Интерполяция).
Если выбран параметр Использовать функцию «Заполнять сверху» Excel (см. раздел Цветовая схема), цвет заливки Excel для ячейки метки ряда определяет цвет заливки области этого ряда.
7.6.2 100%-диаграмма с областями
| Значок в меню «Элементы»: |
100%-диаграмма с областями — это вариант диаграммы с областями, в которой сумма всех значений в категории обычно представляет 100 %. Если сумма значений в категории отличается от 100 %, то диаграмма будет отображаться соответствующим образом. Дополнительные сведения об указании значении данных см. в разделе Абсолютные и относительные значения. В метках 100%-диаграммы с областями могут отображаться абсолютные значения, проценты или и то, и другое (Содержимое меток). Вы можете включить линейную интерполяцию, нажав кнопку Интерполировать (см. раздел Интерполяция).
7.7 Смешанная диаграмма
| Значок в меню «Элементы»: |
Смешанная диаграмма объединяет сегменты графика и гистограммы на одной диаграмме. В разделах График и Гистограмма и гистограмма с накоплением подробно описывается использование таких сегментов.
Чтобы преобразовать ряд сегментов, просто выделите линию и выберите параметр Сегменты стека в элементе управления типом диаграммы (см. раздел Тип диаграммы). Чтобы преобразовать сегменты в линию, просто выделите сегмент ряда и выберите параметр Линия в элементе управления типом диаграммы. У источников данных графиков, диаграмм с накоплением и смешанных диаграмм одинаковый формат.
Эту функцию можно использовать в гистограммах с накоплением и группировкой, а также в графиках.
Гистограммы—ArcMap | Документация
Доступно с лицензией Geostatistical Analyst.
Инструмент Гистограмма (Histogram) предоставляет одномерное (с одной переменной) описание данных. В диалоговом окне инструмента отображается частотное распределение интересующего набора данных и вычисляется суммарная статистика.
Частотное распределение
Частотное распределение представляет собой столбчатую диаграмму для отображения частотности попадания наблюдаемых значений в определенные интервалы или классы. Можно указать ряд классов с одинаковой шириной, которые будут использоваться в гистограмме. Относительная пропорция данных, которая распределяется по каждому классу, выражается высотой каждого столбца. Например, в гистограмме ниже показано частотное распределение (10 классов) для набора данных.
Пример диалогового окна Гистограмма (Histogram)Суммарная статистика
Важные объекты распределения могут быть суммированы с помощью различных статистик, которые характеризуют их местоположение, распределение и форму.
Показатели расположения
Показатели расположения дают представление о том, где находятся центр и другие части распределения.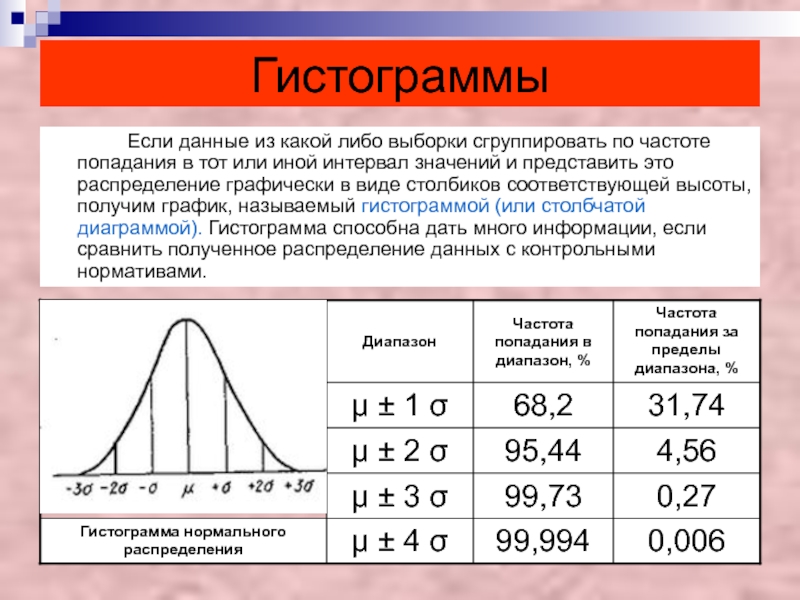
- Среднее значение — это среднее арифметическое данных. Среднее представляет собой один из показателей центра распределения.
- Значение медианы соответствует кумулятивной пропорции 0,5. Если данные организованы в порядке возрастания, 50 процентов значений будут находиться ниже медианы, а другие 50 процентов — выше медианы. Медиана предоставляет еще один показатель центра распределения.
- Первая и третья квартили соответствуют кумулятивной пропорции 0,25 и 0,75. Если данные организованы в порядке возрастания, 25 процентов значений будут находиться ниже первой квартили, а еще 25 процентов — выше третьей квартили. Первая и третья квартили являются особыми случаями квантилей. Квантили вычисляются следующим образом:
где i — упорядоченное i-тое значение данных.quantile = (i - 0.5) / N
Показатели разброса
Разброс точек вокруг среднего значения — еще одна характеристика отображаемого частотного распределения.
- Дисперсия данных представляет собой среднеквадратическое отклонение всех значений от среднего. Поскольку в нее включаются квадраты разностей, вычисляемая дисперсия чувствительна к необычно высоким или низким значениям. Дисперсия оценивается суммированием квадратических отклонений от среднего и делением суммы на (N-1).
- Стандартное отклонение представляет собой квадратный корень из дисперсии и описывает разброс данных вокруг среднего. Чем меньше дисперсия и стандартное отклонение, тем гуще сконцентрирован кластер измерений вокруг среднего значения.
На диаграмме ниже показаны два распределения с различными стандартными отклонениями. Частотное распределение, представленное черной линией, более переменчиво (с широким разбросом), чем частотное распределение, представленное красной линией. Дисперсия и стандартное отклонение для черного частотного распределения больше, чем для красного.
Показатели диаграммы разбросаПоказатели формы
Частотное распределение также характеризуется формой.
Коэффициент асимметрии — это показатель симметрии распределения. Для симметричных распределений коэффициент асимметрии равен нулю. Если у распределения есть длинный правый хвост больших значений, то у него положительная асимметрия, а если длинный левый хвост малых значений — то отрицательная. Среднее значение для распределений с положительной асимметрией больше, чем медиана, а для распределений с отрицательной асимметрией — наоборот. На рисунке ниже показано распределение с положительной асимметрией.Пример распределения с положительной асимметрией
Эксцесс основан на размере хвостов распределения и представляет собой показатель вероятности того, что распределение будет создавать выпадающие значения. Эксцесс нормального распределения равен трем. Распределения с относительно толстыми хвостами называются островершинными (лептокуртическими), и у них эксцесс больше трех. Распределения с относительно тонкими хвостами называются плосковершинными (платикуртическими), и у них эксцесс меньше трех. На следующей диаграмме нормальное распределение показано красным цветом, а островершинное (с толстыми хвостом) — черным.
Пример нормального распределенияПримеры
С помощью инструмента Гистограмма (Histogram) можно исследовать форму распределения путем прямого наблюдения. Просматривая статистику среднего значения и медианы, можно определить расположение центра распределения. На рисунке внизу обратите внимание на колоколообразное распределение, и так как значения среднего арифметического и медианы близки, это распределение близко к нормальному. Также можно выделить экстремальные значения в хвосте гистограммы и увидеть, как они расположены в пространстве на отображаемой карте.
Пример колоколообразной гистограммы
Если асимметрия данных слишком большая, можно протестировать эффекты трансформации на данных. На этом рисунке показано распределение с асимметрией перед применением преобразования.Пример гистограммы с асимметрией
К асимметричным данным применяется логарифмическое преобразование, и в этом случае преобразование приближает распределение к нормальному. Пример гистограммы логарифмического преобразования
Пример гистограммы логарифмического преобразования
Более подробно о преобразованиях, доступных в инструменте Гистограмма (Histogram), см. в разделе Преобразования по методу Box-Cox, арксинуса- и логарифмические.
Создание и использование гистограмм—ArcGIS Insights
Гистограммы агрегируют числовые данные по группам с равными интервалами, которые называют бинами, и отображают частоту встречаемости значений в каждом из бинов. Гистограмма создается с помощью числового поля или поля доля/отношение.
Гистограммы помогают получить ответ на такой вопрос: каково распределение числовых значений и частота их появлений в наборе данных? Есть ли выбросы?
Пример
Негосударственная организация в области здравоохранения изучает показатели подросткового ожирения в США. Гистограмма частоты случаев ожирения у подростков может использоваться для того, чтобы определить, как распределены показатели ожирения по штатам, в том числе наиболее высокие и низкие показатели частоты ожирения и их общий уровень.
На приведенной выше гистограмме показано нормальное распределение, при котором наиболее часто встречающиеся показатели находятся в диапазоне 10-14 процентов.
Увеличивая и уменьшая число бинов, вы можете повлиять на характер анализа своих данных. Хотя сами данные и не изменяются, может измениться их вид. Чтобы правильно истолковать закономерности в данных, важно выбрать подходящее число бинов. Слишком маленькое число бинов может скрыть какие-то закономерности, а слишком большое – преувеличить значение небольших, допустимых изменений данных. Ниже представлен пример подходящего числа бинов данных. Каждый бин содержит примерно один процент данных, и данные можно рассмотреть в более крупном масштабе, что позволит выявить закономерности, невидимые при использовании шести бинов. В данном случае налицо нормальное распределение значений с незначительным, сдвигом влево.
Создание гистограммы
Для создания гистограммы выполните следующие шаги:
- Выберите числовое поле или поле доли/отношения .

- Для создания гистограммы выполните следующие шаги:
- Перетащите выбранные поля в новую карточку.
- Наведите курсор над областью размещения Диаграмма.
- Поместите выбранные поля на Гистограмму.
Подсказка:
Также можно построить диаграммы с помощью меню Диаграмма над панелью данных или кнопки Тип визуализации на существующей карточке. В меню Диаграммы будут доступны только диаграммы, которые применимы к имеющейся выборке данных. В меню Тип визуализации будут только подходящие варианты визуализаций (карты, диаграммы или таблицы).
Гистограмму также можно создать с помощью Просмотр гистограммы; для этого используйте кнопку Действие на вкладке Найти ответы > Распределение
Примечания по использованию
Гистограммы обозначаются отдельными символами. Вы можете использовать кнопку Легенда , чтобы изменить цвет символа и цвет контура, который будет применен ко всем бинам.
Когда гистограмма будет создана, Insights автоматически вычисляет приблизительное количество бинов для отображения ваших данных. Вы можете изменить количество бинов при помощи бегунка вдоль оси Х или щёлкнув на числе бинов и введя новое значение.
Для отображения среднего, медианного и нормального распределения данных используйте кнопку Статистика диаграммы . Кривая нормального распределения представляет ожидаемое распределение случайного поднабора непрерывных данных, где самая высокая частота значений центрируется вокруг среднего и частота значений уменьшается по мере увеличения или уменьшения значений по мере удаления от среднего. Кривая нормального распределения полезна при выявлении наличия провалов и выбросов в данных.
Эти статистики на обороте карточек включают среднее, медиану, дисперсию, стандартное квадратичное отклонение, эксцесс и сдвиг (упрощенный). Следующая таблица содержит описание асимметрии и эксцесса:
| Статистика | Описание |
|---|---|
Асимметрия | Скошенность определяет симметрично ли распределение данных. Значения асимметрии могут быть нулевыми, отрицательными или положительными:
|
Эксцесс | Эксцесс описывает форму плотности распределения и определяет вероятность выбросов при данном распределении. Распределения с относительно тяжёлыми хвостами называются островершинными (лептокуртическими), и у них эксцесс больше нуля. Распределения с относительно тонкими хвостами называются плосковершинными (платикуртическими), и у них эксцесс меньше нуля. Эксцесс нормального распределения равен трём, а в случае использования упрощённого эксцесса – нулю (это вычисляется по той же формуле, что и эксцесс, минус три). Значения упрощённого эксцесса могут быть нулевыми, отрицательными или положительными:
|
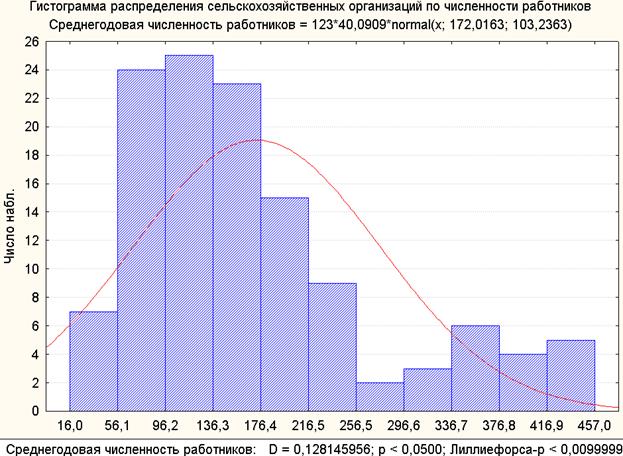 Мера скошенности определяет где лежит большинство значений в распределении – левее или правее среднего. Асимметрия нормального распределения равна нулю и показывает одинаковый объем данных по обе стороны от среднего.
Мера скошенности определяет где лежит большинство значений в распределении – левее или правее среднего. Асимметрия нормального распределения равна нулю и показывает одинаковый объем данных по обе стороны от среднего.Используйте кнопку Тип визуализации для прямого переключения между гистограммой и градуированными символами на карте или суммарной таблицей.
Отзыв по этому разделу?
Гистограмма
Гистограмма отображает данные, собранные объектом Данные гистограммы (на одной гистограмме могут одновременно отображаться данные сразу нескольких таких объектов). Ось X всегда масштабируется таким образом, чтобы вместить все данные. Масштаб по оси Y также выбирается автоматически, таким образом, чтобы высота самого высокого столбца была равна высоте области диаграммы.
При необходимости на гистограмме могут быть отображены функция плотности вероятности, функция распределения и линия среднего значения.
Функция плотности вероятности отображается в виде набора вертикальных столбцов, каждый из которых соответствует определенному интервалу. Высота столбца пропорциональна плотности (или количеству) значений, попавших в этот интервал.
Если объектом сбора данных гистограммы вычисляются процентили, и заданы значения как нижнего, так и верхнего доверительного интервалов, то столбцы, содержащие “рисковые значения” (значения, удовлетворяющие уравнению Интегральная функция распределения(значение) 100 – верхний процентиль) будут отрисовываться заданными цветами.
Имя – Имя гистограммы. По этому имени гистограмма будет доступна из кода.
Исключить – Если опция выбрана, то гистограмма будет исключена из модели.
Отображается на верхнем агенте – Если опция выбрана, то гистограмма будет видна на презентации типа агента, в который будет вложен данный агент.
Отображать плотность вер-ти – Если опция выбрана, то на гистограмме будет отображаться плотность вероятности.
Отображать ф-ю распределения
– Если опция выбрана, то на гистограмме будет отображаться функция распределения.
Отображать среднее – Если опция выбрана, то на гистограмме будет нарисована вертикальная линия, соответствующая среднему значению.
– С помощью этой кнопки вы можете добавить новый объект данных гистограммы на гистограмму. Щелкнув по ней, вы откроете новую секцию свойств, в которой вы должны будете задать свойства нового объекта данных:
Заголовок – Заголовок этого объекта данных, который будет отображаться в легенде гистограммы.
Данные – Имя этого объекта данных гистограммы.
Цвет плотности вер-ти – [Виден, если установлен флажок Отображать плотность вер-ти] Цвет, которым на гистограмме будет отображаться плотность вероятности.
Цвет линии ф. распред. – [Виден, если установлен флажок Отображать ф-ю распределения] Цвет, которым на гистограмме будет отображаться интегральная функция распределения.
Цвет линии среднего – [Виден, если установлен флажок Отображать среднее] Цвет, которым на гистограмме будет отображаться линия среднего значения.
Толщина линии ф-ии распред. и среднего – [Виден, если установлен флажок Отображать ф-ю распределения или Отображать среднее] Толщина линии интегральной функции распределения и линии среднего значения.
Цвет нижнего % – Цвет, которым будет отображаться плотность вероятности слева от нижнего процентиля.
Цвет верхнего %
– Цвет, которым будет отображаться плотность вероятности справа от верхнего процентиля.
Чтобы удалить объект данных с гистограммы, щелкните мышью по кнопке внизу этой секции свойств. Используйте кнопки и , чтобы изменять порядок расположения элементов данных.
Обновлять данные автоматически — Если опция выбрана, то гистограмма будет производить обновление значений отображаемых на ней объектов данных с периодичностью, указанной в поле Период. Так же здесь вы можете выбрать, хотите ли вы Использовать модельное время, чтобы задать Время первого обновления, или вы хотите Использовать календарные даты, чтобы задать Дату обновления.
Не обновлять данные автоматически — Если опция выбрана, то гистограмма не будет самостоятельно производить обновление значений отображаемых на ней объектов данных.
Относительная ширина столбцов – С помощью данного бегунка вы можете задавать суммарную ширину оснований столбцов (в процентах, относительно соответствующей размерности гистограммы, 100% — максимум, 50% — половина и т.д.).
Метки по оси Y – С помощью данного выпадающего списка вы можете задать расположение меток, отображаемых для оси Y, относительно области гистограммы (Слева или Справа). Если вы не хотите, чтобы у оси Y отображались метки, выберите из списка Нет.
Цвет фона – Фоновый цвет диаграммы.
Цвет границы – Цвет, которым будет отображаться граница диаграммы.
Цвет меток
– Цвет, которым будут отображаться метки по оси Y. Если вы не хотите, чтобы метки были видны, выберите
Нет цвета.
Если вы не хотите, чтобы метки были видны, выберите
Нет цвета.
Цвет сетки – Цвет, которым будет отображаться сетка гистограммы. Если вы не хотите, чтобы сетка была видна, выберите Нет заливки.
Уровень – Уровень, на котором расположена эта гистограмма.
X – X-координата верхнего левого угла диаграммы.
Y – Y-координата верхнего левого угла диаграммы.
Ширина – Ширина диаграммы (в пикселах).
Высота – Высота диаграммы (в пикселах).
Легенда – Если опция выбрана, то у данной гистограммы будет отображаться легенда. Вы можете управлять местоположением легенды относительно области диаграммы с помощью группы кнопок Расположение. Размер области, выделенной под легенду, задается с помощью элемента управления Ширина (или Высота, в зависимости от того, какое задано Расположение легенды). Также вы можете изменить Цвет текста легенды.
Свойства, расположенные в секции Область диаграммы, задают визуальные свойства области диаграммы:
Смещение по оси X – Смещение области диаграммы по оси X относительно левой границы всей области, выделенной в графическом редакторе под диаграмму.
Смещение по оси Y
– Смещение области диаграммы по оси Y относительно верхней границы всей области, выделенной в графическом редакторе под диаграмму.
Ширина – Ширина области диаграммы (в пикселах).
Высота – Высота области диаграммы (в пикселах).
Цвет фона – Фоновый цвет области диаграммы.
Цвет границы – Цвет, которым будет отображаться граница области диаграммы.
Видимость – Видимость диаграммы. Диаграмма будет видна, если заданное здесь выражение будет истинно (true), в противном случае диаграмма отображаться не будет.
Количество – Количество экземпляров данной диаграммы. Если вы оставите это поле пустым, то будет создана только одна такая диаграмма.
Действие при изменении выделения
– Код, который будет выполняться, когда пользователь выделит на диаграмме какой-то один (или несколько) элемент(ов) данных. Код будет вызываться как в том случае, если пользователь выделит элементы, щелкнув мышью по их заголовкам в легенде, так и в
том случае, если он выделит их программно путем вызова метода
selectItem().
Вы можете использовать в этом коде две переменные:
int[] selectedIndices
— номера выделенных в текущий момент элементов данных.
boolean programmatically
— определяет, были ли элементы выделены программно (true) или нет (false).
Отображать имя – Если опция выбрана, то имя фигуры будет отображаться в графическом редакторе.
Гистограмма с переменной шириной столбцов
Имеем, в качестве примера, вот такую табличку с информацией по количеству сотрудников и стоимостью четырех известных IT-компаний:
Задача: необходимо наглядно отобразить оба параметра для сравнения по всем компаниям.
Можно попытаться построить типичную в таких случаях пузырьковую (точечную) диаграмму. Можно попробовать поиграть с трехмерными диаграммами или торнадо. А можно немного «пошаманить» и сделать плоскую гистограмму со столбцами переменной ширины.
Этап 1. Подготовка данных
Половина успеха при построении любых нестандартных типов диаграмм в Excel, заключается в правильной подготовке таблицы с данными для диаграммы. В нашем случае, исходную табличку придется ощутимо переделать и превратить в нечто похожее на:
Давайте разберем все изменения, которые были сделаны.
- Каждая компания превратилась из строки в столбец.
-
По каждой компании должен быть блок из 5 ячеек, где первая и последняя ячейки с нулями, а три центральных содержат одинаковые значения — стоимость каждой компании.
- Добавлены вспомогательные столбцы Пустышка и Подписи, в которых напротив центральных значений каждого блока размещены стоимости и названия компаний. Эти колонки понадобятся нам чуть позже для правильного размещения подписей к столбикам.
- Первый (неподписанный) столбец представляет из себя чуть более хитрую штуку. Не залитые голубым цветом в нем ячейки — это количества сотрудников по каждой компании (92, 126, 54, 380), но взятые последовательно с нарастающим итогом. Т.е. для Apple это 92, для Microsoft уже 92+126=218, для Google 92+126+54=272 и т.д. Голубые же ячейки будут впоследствии, своего рода, «переходниками» и содержат среднее арифметическое соседних ячеек, т.е. для Apple это (0+92)/2=46, для Microsoft (92+218)/2=155 и т.д.
Этап 2. Строим диаграмму
Выделим в нашей таблице все столбцы кроме последних двух и на вкладке Вставка (Insert) выберем для построения вариант диаграммы С областями с накоплением (Stacked Area):
На выходе должно получиться что-то похожее:
Основная проблема в том, что Excel на автомате интерпретирует подписи к оси X не как числа, а как текст — интервалы между подписями не соответствуют математической разнице между числами, да и сами подписи повторяются. Именно поэтому наша диаграмма еще не похожа на желаемую, но это, на самом деле, легко исправить. Щелкните правой кнопкой мыши по горизонтальной оси и выберите в контекстном меню команду Формат оси (Axis Format). В открывшемся окне переключите Тип оси с Автовыбора на Ось дат (Date Axis) и все сразу изменится!
Именно поэтому наша диаграмма еще не похожа на желаемую, но это, на самом деле, легко исправить. Щелкните правой кнопкой мыши по горизонтальной оси и выберите в контекстном меню команду Формат оси (Axis Format). В открывшемся окне переключите Тип оси с Автовыбора на Ось дат (Date Axis) и все сразу изменится!
В этом же окне можно настроить шаг делений по горизонтальной оси — для нашего примера я поменял параметр Единицы измерения с месяцев на дни и задал значение 50.
Этап 3. Добавляем подписи
Теперь неплохо бы добавить в нашу диаграмму подписи с названиями компаний. Скопируйте столбец Пустышка (выделить диапазон G11:G25 и нажать Ctrl+C), выделите диаграмму и вставьте скопированные данные прямо в нее (нажать Ctrl+V) — к нашей диаграмме должен добавиться новый ряд, выглядящий как крыши домов над нашими прямоугольниками:
Теперь щелкните правой кнопкой мыши по любой «крыше» и выберите команду Изменить тип диаграммы для ряда (Change series chart type). В открывшемся окне измените тип диаграммы для добавленного ряда на обычный график с маркерами:
Затем щелкните правой кнопкой мыши по графику и выберите Добавить подписи данных (Add Data Labels). Excel подпишет значения стоимости компании на каждом «пике».
Дальнейший ход действий зависит от того, какая у вас версия Excel. Если у вас последние Excel 2013 или 2016, то все будет проще. Щелкните правой кнопкой мыши по подписям, выберите команду Формат подписей (Format Data Labels) и затем включите флажок Значения из ячеек (Values from cells). Останется выделить данные из последнего столбца в нашей таблице, чтобы они попали на диаграмму в подписи к столбикам вместо чисел:
Если же у вас более древние версии Excel, то придется либо изменять подписи вручную (несколько одиночных щелчков по подписи, пока не начнет мигать курсор, а потом вбить название компании), либо использовать специальную бесплатную надстройку XYChartLabeler (дай бог здоровьичка Rob Bovey — ее автору, спасшему много-много моих нервных клеток и времени). (-1/3), где
(-1/3), где IQR межквартильный размах X.
'integers'
Целочисленное правило полезно с целочисленными данными, когда это создает интервал для каждого целого числа. Это использует ширину интервала 1 и помещает границы интервала на полпути между целыми числами. Чтобы постараться не случайно создавать слишком много интервалов, можно использовать это правило, чтобы создать предел 65 536 интервалов (216). Если область значений данных больше 65536, то целочисленное правило использует более широкие интервалы вместо этого.
Примечание
'integers' не поддерживает данные о длительности или datetime.
'sturges'
Правило Стерджеса популярно из-за его простоты. Это выбирает количество интервалов, чтобы быть ceil(1 + log2(numel(X))).
'sqrt'
Правило Квадратного корня широко использовано в других пакетах программного обеспечения. Это выбирает количество интервалов, чтобы быть ceil(sqrt(numel(X))).
histogram не всегда выбирает количество интервалов с помощью этих точных формул. Иногда количество интервалов настроено немного так, чтобы границы интервала упали на «хорошие» числа.
Для данных о datetime метод интервала может быть одним из этих модулей времени:
'second' | 'month' |
'minute' | 'quarter' |
'hour' | 'year' |
'day' | 'decade' |
'week' | 'century' |
Для данных о длительности метод интервала может быть одним из этих модулей времени:
'second' | 'day' |
'minute' | 'year' |
'hour' |
Если вы задаете BinMethod с datetime или данными о длительности, затем histogram может использовать максимум 65 536 интервалов (или 216). Если заданная длительность интервала требует большего количества интервалов, то histogram использует большую ширину интервала, соответствующую максимальному количеству интервалов.
Эта опция не применяется к гистограммам категориальных данных.
Примечание
Если вы устанавливаете BinLimitsNumBins BinEdges , или BinWidth свойство, затем BinMethod свойство установлено в 'manual'.
Пример: histogram(X,'BinMethod','integers') создает гистограмму с интервалами, сосредоточенными на целых числах.
Гистограммы цифровых камер: цвет и контраст
Понимание гистограмм изображений является, вероятно, наиболее важным элементом приобретения навыков работы с изображениями, снятыми цифровой камерой. Гистограмма расскажет вам, правильной ли была экспозиция изображения, является свет жёстким или мягким, и какие изменения сработают наилучшим образом. Это повысит ваши умения не только в компьютерной обработке, но и как фотографа.
Это повысит ваши умения не только в компьютерной обработке, но и как фотографа.
В каждом пикселе изображения содержится цвет, который образован некоторой комбинацией первичных цветов: красного (R), зелёного (G) и синего (B). Каждый из этих цветов имеет значение яркости в диапазоне от 0 до 255 для цифрового изображения разрядностью 8 бит. RGB-гистограмма образуется, когда компьютер сканирует все значения яркостей RGB и считает количество яркостей от 0 до 255 в каждом из них. Существуют и другие типы гистограмм, но все они будут иметь базовый вид, аналогичный примеру гистограммы, показанному ниже.
Цвета
Область, в которой находится большинство значений яркости, называется «тональным диапазоном». Тональный диапазон может радикально отличаться от изображения к изображению, и потому выработать ощущение того, как числа соотносятся с яркостями, зачастую критически важно, как до съёмки, так и по её результатам. Не существует «идеальной гистограммы», которой должны соответствовать все изображения; гистограммы должны соответствовать тональному диапазону сцены и замыслу фотографа.
Вышеприведенный пример изображения имеет весьма широкий тональный диапазон, на котором проставлены маркеры для иллюстрации соотношения между уровнями яркостей и элементами изображения. Эта прибрежная сцена имеет очень немного полутонов, но она изобилует тенями и яркими зонами в нижнем левом и верхнем правом углах изображения, соответственно. Это отражается на гистограмме, которая содержит большое число пикселей как на левой, так и на правой границах.
|
Свет часто не настолько экстремален, как на приведенном примере. В условиях обычного и ровного освещения при правильно подобранной выдержке гистограмма обычно будет показывать максимум в центральной части, спадая в области теней и яркостей. За исключением прямого солнечного света, отражающегося от крыши и окон здания, сцена с лодкой достаточно равномерно освещена. |
|
 Большинство камер не испытает никаких затруднений с передачей изображения, которое имеет гистограмму наподобие приведенной ниже..
Большинство камер не испытает никаких затруднений с передачей изображения, которое имеет гистограмму наподобие приведенной ниже..Изображения в высоком и низком ключе
Несмотря на то, что большинство камер в режиме автоматической экспозиции зафиксирует центрированную гистограмму, разброс пиков в гистограмме зависит также от тонального диапазона предмета съёмки. Изображения с перевесом теней называются «низким ключом», тогда как изображения в «высоком ключе» состоят преимущественно из ярких элементов.
Перед тем как сделать снимок, бывает полезно оценить, относится ли предмет съёмки к высокому или низкому ключу. Поскольку камеры измеряют отражённый свет, а не падающий, они не могут оценить абсолютную яркость предмета съёмки. В результате во многих камерах содержатся комплексные алгоритмы, которые пытаются обойти это ограничение и оценить, насколько ярким должно оказаться изображение. Эти оценки часто создают итоговое изображение со средней яркостью в полутонах. Обычно это решение верно, но для сцен в высоком или низком ключе от фотографа может потребоваться скорректировать экспозицию вручную относительно того, что камера сделала бы автоматически. Возьмите за правило применять экспокоррекцию, если средняя яркость предмета съёмки должна оказаться больше или меньше, чем полутона.
Следующий набор изображений мог бы получиться, если бы я использовал автоэкспозицию камеры. Обратите внимание,как среднее число пикселей сдвигается в сторону полутонов.
Большинство цифровых камер лучше воспроизводят сцены в низком ключе, поскольку это предотвращает засветку ярких областей, вне зависимости от того, насколько тёмным может оказаться остальное ихображение. С другой стороны, сцены в высоком ключе зачастую порождают снимки, которые заметно недоэкспонированы. К счастью, недосвет гораздо более простителен, чем пересвет (хотя он и ухудшает соотношение сигнал-шум). Из тех областей, которые в результате переэкспонирования превратились в абсолютно белый, извлечь детали уже невозможно. Когда это происходит, говорят, что произошла «засветка» или «клип».
Из тех областей, которые в результате переэкспонирования превратились в абсолютно белый, извлечь детали уже невозможно. Когда это происходит, говорят, что произошла «засветка» или «клип».
Гистограмма является хорошим инструментом контроля засветок, поскольку они непосредственно видны на границе диапазона. В случаях, когда в кадре присутствуют отражения от воды или металла, солнце или другие источники яркого света, некоторый небольшой объём засветок может быть вполне приемлем. В конечном счёте количество засветки остаётся на усмотрение фотографа и воплощения его замысла.
Контраст
Гистограмма может также описать степень контраста в изображении. Контраст является измерением разницы яркостей между светлыми и тёмными частями изображения. Широкие гистограммы отражают сцены со значительным контрастом, тогда как узкие гистограммы означают, что контраст снижен, и изображение может оказаться плоским или скучным. Это может быть вызвано любой комбинацией предметов съёмки и условий освещения. Снимки, сделанные в тумане, будут иметь малый контраст, тогда как те, что были сняты в ярком дневном свете, окажутся высококонтрастными.
Контраст может иметь значительное визуальное влияние на изображение, выделяя текстуры, как показано на снимке выше. На высококонтрастной воде тени глубже, а свет более выраженный, порождая текстуру, которая «торчит» из снимка.
Контраст может также варьироваться в различных частях одного снимка как вследствие самих предметов, так и их освещённости. Мы можем поделить снимок с лодкой на три независимых части, каждая со своей собственной гистограммой.
Из всех трёх частей верхняя наиболее контрастна, поскольку снимок сделан при освещении, которое не отражалось сперва от поверхности воды. Это создаёт более глубокие тени под лодкой и её бортами и более яркие тона на освещённых участках. Средняя и нижняя части полностью освещены рассеянным отражённым светом, и потому контраст в них меньше; они соответствуют тем фотографиям, которые могли бы быть сняты в тумане. В нижней части контраста больше, чем в средней, несмотря на гладкое и монотонное синее небо, поскольку здесь присутствует сочетание тени и более интенсивного солнечного света. Условия в нижней части создают более выраженные зоны яркости, но всё же ей не хватает глубины теней из верхней части. Сумма гистограмм всех трёх частей создаёт гистограмму, приведенную ранее.
За дальнейшей информацией о гистограммах обратитесь ко второй части данной статьи:
«Гистограммы: яркость и цвет»
laurenzlong / histogram-and-statics-C: Программа на C, которая считывает список меток, вычисляет статистику и печатает гистограмму
Изначально создан для школьного задания по курсу программирования C. Ниже инструкция по выполнению задания.
Программа: Ваша задача — написать программу на языке C, которая считывает список меток и печатает следующее:
Средняя оценка Стандартное отклонение Минимальная оценка Максимальная оценка Текстовая гистограмма, показывающая распределение буквенных оценок Все метки будут целыми числами от 0 до 100 включительно.Для гистограммы используйте буквенные диапазоны оценок, используемые в Queen’s: F = 0–49 D = 50-59 С = 60–69 В = 70-79 А = 80-100 Поскольку мы еще не говорили о файловом вводе-выводе, ваша программа должна прочитать список меток из стандартного ввода. Вы можете вводить данные непосредственно во время работы программы, заканчивая нажатием Ctrl-D, но самый простой способ протестировать вашу программу — это поместить список меток во входной файл и направить этот файл в стандартный ввод вашей программы. Пример выполнения ниже иллюстрирует эту возможность.
Примеры прогонов: Этот стенограмма замазки показывает два прогона моего решения. Ваш результат не обязательно должен быть похож на мой, но он должен быть максимально похожим. Другими словами, мы не собираемся снимать очки, если ваш интервал не такой, как у меня, но ваш результат должен отображать ту же информацию в том же порядке, и ваша гистограмма должна иметь такой же вид, как моя. Высота гистограммы не задана; вы должны сделать его настолько высоким, насколько это необходимо для буквенной оценки с наибольшим количеством оценок.
Статистика: Я уверен, что все уже знают, что среднее значение списка значений — это их сумма, деленная на количество значений.
Чтобы найти стандартное отклонение списка из N значений, найдите разницу между каждым значением и средним значением, возведите каждую разницу в квадрат, сложите все квадраты, разделите на N-1 и извлеките квадратный корень.
Например, среднее из четырех значений [2,9,6,1] составляет (2 + 9 + 6 + 1) / 4 = 4,5. Их стандартное отклонение — это квадратный корень из ((2-4,5) 2+ (9-4.5) 2+ (6-4,5) 2+ (1-4,5) 2) деленное на 3, что равно квадратному корню из ((2,52 + 4,52 + 1,52 + 3,52) / 3) или квадратному корню из 41 / 3, что составляет примерно 3,7.
Обработка ошибок: Вам нужно только проверить два типа ошибок при чтении ввода. Если входные данные содержат что-либо, кроме целочисленных значений, напишите сообщение об ошибке и прервите программу. Если входные данные содержат менее двух целочисленных значений, вы также должны написать сообщение об ошибке и прервать выполнение, так как вам нужно как минимум два значения для вычисления стандартного отклонения.
Ваша программа должна будет принять максимальное количество входных значений. Любые значения после этого во входных данных следует просто игнорировать. Это максимальное число должно быть не менее 20, и вы должны использовать для него макрос (например, #define) вместо жесткого кодирования числа в вашей программе.
Использование математической библиотеки:
Чтобы вычислить стандартное отклонение, вам понадобится функция извлечения квадратного корня. Я реализовал в классе функцию извлечения квадратного корня, но вместо того, чтобы копировать мою, вы должны использовать функцию sqrt из математической библиотеки C.Включите
Использование нескольких файлов: Для получения полной оценки вы должны разбить вашу программу как минимум на четыре файла .c. В своем решении я использовал ровно четыре файла .c:
histogram.c: содержит функцию, которая принимает массив и размер массива в качестве параметров и печатает гистограмму. readMarks.c: содержит функцию, которая принимает массив в качестве параметра, считывает значения из стандартного ввода в массив и возвращает количество прочитанных значений.statistics.c: содержит функции, которые принимают массив и размер массива в качестве параметров и возвращают статистику (среднее, стандартное отклонение, минимум и максимум). assn6.c: содержит основную функцию, которая вызывает функции из других файлов и выводит статистику. Если вы думаете о другом способе разделения программы на файлы, вы можете использовать его, если вы используете как минимум четыре файла .c, и каждый из них содержит хотя бы одну функцию, выполняющую нетривиальную часть программы. Как бы вы ни разделили свою программу, вы должны предоставить.h для каждого файла .c, содержащего заголовок (ы) для функций в файле, которые будут вызываться из функций в других файлах. Если есть какие-либо макросы препроцессора (#defines), которые необходимо использовать более чем в одном файле, они должны быть определены в соответствующем файле .h.
Использование препроцессора C: Используйте как минимум два макроса #define где-нибудь в вашей программе. Я уже указывал выше, что одним из них должно быть ограничение на количество оценок, которые программа будет читать (не менее 20).Подумайте о другом способе определения и использования #define в вашей программе.
Также добавьте некоторые отладочные данные в какой-либо раздел вашей программы, чтобы они печатались только в том случае, если определен макрос DEBUG. В моем решении вывод отладки выводил количество отметок в каждой буквенной категории непосредственно перед гистограммой. Если хотите, вы можете придумать другой вид вывода отладки.
Скрипты сборки: Вы должны написать и передать сценарий bash под названием buildAssn6, который выполняет все компиляции и этап связывания для создания вашей полной программы в версии, которая не включает вывод отладки.Ваш последний исполняемый файл должен называться assn6. Вам не нужно писать make-файл для этого назначения; просто напишите сценарий bash, чтобы скомпилировать и связать все с нуля.
Вы должны написать и передать второй сценарий bash под названием buildDebug, который выполняет все компиляции и этап компоновки для построения вашей полной программы в версии, которая включает отладочные данные. Это должно выглядеть так же, как buildAssn6, но с дополнительным флагом хотя бы в одной из команд компиляции. Ваш последний исполняемый файл из этого скрипта также должен называться assn6.
Стиль: Вы будете отмечены за ваш стиль программирования. Хороший стиль включает в себя:
Комментарий заголовка для каждого файла с кратким описанием цели файла и указанием автора (ов), курса, семестра и номера задания. Комментарий заголовка для каждой функции, кратко объясняющий, что она делает, для чего предназначены ее параметры и какое значение, если оно есть, она вернет. Значимые имена переменных Четкие и последовательные отступы Написание кода максимально простым и понятным способом.Комментарии внутри функций, если вы делаете что-то сложное, разобраться с которым другому программисту на языке C может потребовать времени. Вы можете предположить, что вашу программу читает кто-то, кто знаком с основами C, а также с базовой статистикой и гистограммами. Например, вам не нужно писать комментарии, объясняющие, что такое стандартное отклонение или как работает printf. Меня часто спрашивают, принадлежит ли комментарий заголовка функции ее определению в файле .c или ее «прямому объявлению» в файле .h. Ответ — оба места.Чтобы включить эти комментарии дважды, достаточно просто вырезать и вставить, а это означает, что любой, кто просматривает файл .c или файл .h, увидит основную информацию о назначении объявляемых и определяемых функций.
Два обязательных сценария bash короткие и простые, но они все равно должны содержать комментарии заголовков, аналогичные комментариям заголовков, которые я просил выше для вашего кода C.
Хороший стиль для этой программы также включает использование НИКАКИХ глобальных переменных. Позже в курсе будут времена, когда нам понадобится использовать глобальные переменные, но в этой программе они не нужны.Ваши функции должны использовать параметры и возвращать результаты для взаимодействия друг с другом.
Примеры программ: Если вы хотите посмотреть на примеры небольших многофайловых программ на C, я поместил две в систему CASLab для вашей справки. Одна из них — программа извлечения квадратного корня, которую мы обсуждали в классе; его в / cas / course / cisc220 / CIntro / squareRootMultipleFiles. Другой — решение Задания 6 от осени 2011 года и находится в / cas / course / cisc220 / CIntro / Fall2011Assn6.
Совет: Если вам неудобно писать многофайловую программу на C, попробуйте записать эту программу в один файл, а затем разбить его на несколько файлов, как я разбил пример квадратного корня в классе.Сохраните исходную однофайловую программу, чтобы, если вы не можете получить работающую версию с несколькими файлами, вы могли отправить эту программу для частичного кредита.
С другой стороны, если вы поняли пример, который я сделал в классе, вы можете с самого начала написать программу в нескольких файлах.
В любом случае, не ждите до последней минуты. Посетите свою лабораторию и попросите о помощи, если у вас возникнут проблемы. Помните, что посещать более одной лаборатории — это нормально, и вам не обязательно придерживаться той лаборатории, в которой вы зарегистрированы.Единственный раз, когда TA откажут любого студента от лаборатории, — это если не хватит мест для всех, и в этом случае они будут отдавать предпочтение студентам, зарегистрированным для этой лаборатории. На практике этого никогда не бывает. Я слышал, что лабораторные работы в 8:30 особенно плохо посещаются, а это означает, что у технических специалистов этих лабораторий есть много времени для оказания помощи и поддержки.
Также не забывайте, что у меня рабочие часы со вторника по пятницу, а также обычно есть время поговорить со студентами после лекций.
Наконец, обязательно протестируйте свою программу и свои сценарии. А если вы внесете даже небольшое изменение, протестируйте их еще раз! Я часто вижу ошибки в отправке заданий, которые было бы довольно легко исправить, и подозреваю, что ученик не провел достаточного тестирования, чтобы понять, что это была ошибка.
Административная информация: Для этого задания вам нужно сдать много файлов. Не забудьте ни одного из них. Полная заявка должна включать:
Как минимум четыре файла .c По крайней мере, три.h файлы (по одному для каждого файла .c, кроме основного файла) Два скрипта, называемые buildAssn6 и buildDebug Всего 9 файлов. Я настрою область отправки Moodle, чтобы разрешить максимум 9 файлов. Если вам нужно отправить более 9 файлов или если загрузка 9 отдельных файлов вызывает неудобства, другой вариант — отправить один файл «zip». Вот простая команда bash для создания zip-файла всего, что вам нужно: zip assn6.zip * .c * .h buildAssn6 buildDebug Эта команда создает файл assn6.zip, который будет содержать сжатую копию всех остальных файлов в списке аргументов. Если вы решите создать zip-файл, создайте его таким образом, а не с помощью zip-программы на вашем компьютере с Windows или Mac. Zip-файлы из разных систем могут иметь несколько разные форматы, и нам нужны zip-файлы, которые специалисты службы поддержки могут быстро распаковать в Linux. Пожалуйста, используйте имена файлов, которые я просил для ваших скриптов. Не объединяйте файлы никаким другим способом, кроме zip-файла Linux — никаких rar-файлов и т. Д.Если вы тратите время TA, используя разные имена или форматы файлов, мы снимем с вашей оценки один или два административных балла.
Вот схема маркировки для этого задания: основная правильность: 16 отметки о чтении и статистика печати: 8 печать гистограмм: 8 обработка ошибок: 4 организация программы с использованием не менее 4 модулей: 8 использование как минимум 2 #defines: 4 условный вывод отладки: 4 два скрипта сборки: 4 стиль: 4 всего: 44
R hist () для создания гистограмм (с многочисленными примерами)
В этой статье вы научитесь использовать функцию hist () для создания гистограмм в программировании на R с помощью многочисленных примеров.
Гистограмма может быть создана с помощью функции hist () на языке программирования R. Эта функция принимает вектор значений, для которых строится гистограмма.
Давайте воспользуемся встроенным набором данных airquality , который содержит ежедневных измерений качества воздуха в Нью-Йорке с мая по сентябрь 1973 года. Документация по
-R.
> ул (качество воздуха)
'data.frame': 153 набл. из 6 переменных:
$ Озон: внутренний 41 36 12 18 - нет данных 28 23 19 8 - нет ...
$ Solar.R: внутр.1 149 313 NA NA 299 99 19 194 ...
$ Wind: число 7,4 8 12,6 11,5 14,3 14,9 8,6 13,8 20,1 8,6 ...
$ Temp: внутр 67 72 74 62 56 66 65 59 61 69 ...
$ Месяц: int 5 5 5 5 5 5 5 5 5 5 ...
$ День: int 1 2 3 4 5 6 7 8 9 10 ...
Мы будем использовать параметр температуры, который имеет 154 измерения в градусах Фаренгейта.
Пример 1: Простая гистограмма
Температура <- качество воздуха $ Temp
hist (Температура)
Выше видно, что есть 9 ячеек с одинаковыми разрывами.В этом случае высота ячейки равна количеству наблюдений, попадающих в эту ячейку.
Мы можем передать дополнительные параметры, чтобы контролировать внешний вид нашего графика. Вы можете прочитать о них в разделе помощи - hist .
Вот некоторые из часто используемых: main , чтобы дать название, xlab и ylab , чтобы предоставить метки для осей, xlim и ylim для предоставления диапазона осей, col для определения цвет и т. д.
Кроме того, с аргументом freq = FALSE мы можем получить распределение вероятностей вместо частоты.
Пример 2: Гистограмма с добавленными параметрами
# гистограмма с добавленными параметрами
hist (Температура,
main = "Максимальная дневная температура в аэропорту Ла-Гуардия",
xlab = "Температура в градусах Фаренгейта",
xlim = c (50,100),
col = "darkmagenta",
freq = FALSE
)
Обратите внимание, что по оси Y отложена плотность, а не частота.В этом случае общая площадь гистограммы равна 1.
Возвращаемое значение hist ()
Функция hist () возвращает список из 6 компонентов.
> h <- hist (Температура)
> ч
$ перерывы
[1] 55 60 65 70 75 80 85 90 95 100
$ counts
[1] 8 10 15 19 33 34 20 12 2
$ плотность
[1] 0,010457516 0,013071895 0,019607843 0,024836601 0,043137255
[6] 0,044444444 0,026143791 0,015686275 0,002614379
$ средние
[1] 57,5 62,5 67,5 72,5 77,5 82.5 87,5 92,5 97,5
$ xname
[1] «Температура»
$ эквидист
[1] ИСТИНА
attr (, "класс")
[1] "гистограмма"
Мы видим, что возвращается объект класса гистограмма , который имеет:
-
разрывы- места разрыва, -
отсчитывает- количество наблюдений, попадающих в эту ячейку, -
density- плотность ячеек,середины- середины ячеек, -
xname- имя аргумента x и -
equidist- логическое значение, указывающее, равномерно ли расположены разрывы или нет.
Мы можем использовать эти значения для дальнейшей обработки.
Например, в следующем примере мы используем возвращаемые значения для размещения счетчиков в верхней части каждой ячейки с помощью функции text () .
Пример 3. Использование возвращаемых значений гистограммы для меток с помощью text ()
h <- hist (Температура, ylim = c (0,40))
текст (h $ mids, h $ counts, labels = h $ counts, adj = c (0.5, -0.5))
Определение количества перерывов
С помощью аргумента breaks мы можем указать количество ячеек в гистограмме.Однако это число - всего лишь предположение.
R вычисляет наилучшее количество ячеек, учитывая это предложение. Ниже приведены две гистограммы для одних и тех же данных с разным количеством ячеек.
Пример 4: Гистограмма с разными изломами
hist (Температура, перерывы = 4, основная = «С перерывами = 4»)
hist (Температура, перерывы = 20, main = "С перерывами = 20")
На приведенном выше рисунке мы видим, что фактическое количество нанесенных ячеек больше, чем мы указали.
Мы также можем определить точки останова между ячейками как вектор. Это дает возможность строить гистограмму с неравными интервалами. В таком случае площадь ячейки пропорциональна количеству наблюдений, попадающих в эту ячейку.
Пример 5: Гистограмма с неравномерной шириной
hist (Температура,
main = "Максимальная дневная температура в аэропорту Ла-Гуардия",
xlab = "Температура в градусах Фаренгейта",
xlim = c (50,100),
col = "шоколад",
border = "коричневый",
разрывы = c (55,60,70,75,80,100)
)
C-печать гистограммы
Горизонтальная гистограмма в c
Упражнение 1.13, Распечатать горизонтальную гистограмму слов во входных данных. * ** / #include
консольная горизонтальная гистограмма в c, Код в C для печати горизонтальной гистограммы.Ставьте лайки и делитесь с друзьями. Это тоже БЕСПЛАТНО 🙂 Исходный код Продолжительность: 1:36 Размещено: 11 июля 2018 г. Мне нужно получить горизонтальную и вертикальную гистограмму заданного массива. Ниже приведен C-код, который я пробовал. Есть ли способ улучшить этот или какой-либо простой альтернативный метод? # включить & lt; stdio.h & gt; #
Горизонтальная и вертикальная гистограмма массива на C, Отлично сделано. Однако есть некоторые мелочи, которые можно улучшить: кажется, что вы пропустили ось x на горизонтальной гистограмме.Также на горизонтальной гистограмме консоли в c - Продолжительность: 1:36. AllTech 328 просмотров. 1:36 [16] (C #) Więcej danych! - Таблице - Продолжительность: 26:33. Maszyna Licząca Рекомендуем вам. 26:33.
Код гистограммы изображения в c
Выравнивание гистограммы в C, Ниже приведена программа C для выполнения выравнивания гистограммы изображения. filter_none. редактировать закрыть. play_arrow. link яркость_4 код Выравнивание гистограммы - это метод настройки уровней контрастности и расширения диапазона яркости цифрового изображения.Таким образом, он улучшает изображение, что упрощает извлечение информации и дальнейшую обработку изображения. Ниже приведен алгоритм выравнивания гистограммы на языке C. Преобразование входного изображения в изображение в оттенках серого
гистограмма изображения - C Board, Мне нужно получить гистограмму изображения с имеющимися у меня кодами, но коды выдают мне ошибки, когда я пишу в визуальной студии. Код: [Просмотр]. #include <Я застрял с созданием этой гистограммы в C. Дело в том, что задача состоит в том, чтобы подсчитать, как часто происходит каждый ввод пользователя.Для: 1 0 6 1 5 0 7 9 0 7 -> есть 3x 0, 2x 1 и т. Д. Затем вхождение должно быть преобразовано в звезды вместо количества вхождений.
Выравнивание гистограммы с использованием C ++: Обработка изображений, Подробнее об выравнивании гистограмм с использованием C ++: Обработка изображений и др. Расчет гистограммы изображения Исходный код: C ++ Гистограмма изображения - это представление распределения значений его яркости. Это предварительное условие для выполнения других операций обработки изображений, таких как статистический анализ изображений, улучшение, восстановление и сегментация.
Гистограмма в java
Histogram.java, Код гистограммы на Java. type поддерживает простой клиентский код для создания динамических * гистограмм частоты появления значений в [0, N). Если это так, просто 1) определите строку длиной 12 звездочек и 2) возьмите substring () длиной 0..12 для каждой строки вашей гистограммы. PS: я бы использовал массив int [] вместо двенадцати отдельных переменных «один», «два», - paulsm4 28 окт. 2012 г. в 6:47
как создать гистограмму в java, Вот несколько различных фрагменты кода, которые вы можете использовать для этого.Создать массив int [] histogram = new int [13] ;. Увеличение позиции в массиве. Выравнивание гистограммы используется для выравнивания всех значений пикселей изображения. Преобразование выполняется таким образом, что получается однородная уплощенная гистограмма. Выравнивание гистограммы увеличивает динамический диапазон значений пикселей и делает равное количество пикселей на каждом уровне, что дает плоскую гистограмму с высококонтрастным изображением.
Histogram.java, / * Marty Stepp, CSE 142, Spring 2010 Эта программа считывает файл с результатами тестов и показывает гистограмму распределения оценок со звездочкой для каждого ученика, получившего * Частоты сохраняются в массиве переменных экземпляра, а * переменная экземпляра max отслеживает максимальную частоту (для масштабирования).* *% java Histogram 50 1000000 * ***** / public class Histogram {private final double [] freq; // freq [i] = # случаев значения i private double max; // максимальная частота любого значения // Создаем новую гистограмму.
Гистограмма Mpi
histogram.c, Создает гистограмму чисел с использованием MPI. В настоящее время числа генерируются с помощью rand () и имеют приблизительно равномерное распределение. #Применение. Скомпилировать. mpi-histogram Создает гистограмму чисел с использованием MPI. В настоящее время числа генерируются с помощью rand () и имеют приблизительно равномерное распределение.
retrohacker / mpi-histogram: Создает гистограмму, примеров программ гистограммы. Для задач или HistoSeq.cpp Последовательная программа для вычисления гистограммы C MPI-версия вычисления гистограммы. Затем выделите (n) отдельных массивов гистограмм. Разделите изображение на (n) горизонтальных фрагментов. Затем создайте (n) потоков и передайте каждому разное число (1..n). Каждый поток будет обрабатывать данные гистограммы для разных срезов и помещать результаты в разные массивы гистограмм.
Примеры программ гистограммы, Думаю, я бы использовал потоки (а не процессы) для распараллеливания этой задачи (pthreads в Unix). При этом все потоки могут совместно использовать один и тот же пул. Гистограмма представляет собой график частотного распределения числового массива, разбивая его на небольшие интервалы равного размера. Если вы хотите математически разделить данный массив на интервалы и частоты, используйте метод numpy histogram () и распечатайте его, как показано ниже.
Показать гистограмму c ++
Создать гистограмму в c, Создать гистограмму в c.Спросите пользовательский ввод и сохраните в массиве. Обработайте массив и сгенерируйте массив гистограмм. Отобразите гистограмму в виде звездочек. Я застрял в создании этой гистограммы на C. Дело в том, что задача состоит в том, чтобы подсчитать, как часто происходит каждый ввод пользователя. Для: 1 0 6 1 5 0 7 9 0 7 -> есть 3x 0, 2x 1 и т. Д. Затем вхождение должно быть преобразовано в звезды вместо количества вхождений.
Как создать гистограмму с помощью кода программирования C, Как создать гистограмму с помощью кода программирования C.Заполните целочисленный массив, называемый «значениями», вашим набором данных и установите для переменной «numvalues» количество значений в вашем наборе данных. Настройте две целочисленные переменные (i и j) для использования в качестве итераторов: Обойдите свои данные - массив значений - и установите «maxval». Выберите «Окно»> «Гистограмма» или щелкните вкладку «Гистограмма», чтобы открыть панель «Гистограмма». По умолчанию панель гистограммы открывается в компактном представлении без элементов управления или статистики, но вы можете настроить вид. Панель гистограммы (расширенный вид)
Программа для построения гистограммы массива, Рекомендуемые сообщения: Программа на C / C ++ для создания простого калькулятора · Минимальное количество удалений, чтобы сделать сумму массива ровной · Проверить, можно ли суммировать C программа для отображения календаря по месяцам на данный год; Выведите буквы от A до Z в виде звездочки; Печать рисунка, разделенного треугольником; Представьте N как сумму K четных или K нечетных чисел с допустимыми повторениями; Программа для поиска всех факторов числа с помощью рекурсии; Найдите наибольшее и второе наибольшее значение в связанном списке
Структура данных гистограммы
Эффективное управление большими объемными числовыми данными с помощью гистограмм, - это представление распределения непрерывной переменной, в котором разделен весь диапазон значений в серию интервалов (или «ячеек»), и представление показывает, сколько значений попадает в каждую ячейку.Гистограмма - это диаграмма, на которой показано распределение значений числовой переменной в виде серии столбцов. Каждая полоса обычно охватывает диапазон числовых значений, называемых ячейкой или классом; высота столбца указывает частоту точек данных со значением в соответствующем интервале.
Полное руководство по гистограммам, Существует ли известный алгоритм + структура данных для поддержания динамической гистограммы? Представьте, что у меня есть поток данных (x_1, w_1), (x_2, w_2), где Шаг 1. Откройте окно анализа данных.Это можно найти на вкладке «Данные» как «Анализ данных: Шаг 2: Выберите гистограмму: Шаг 3: Введите соответствующий диапазон ввода и диапазон ячеек». В этом примере диапазоны должны быть:
Как сохранить динамическую гистограмму ?, Гистограмма используется для суммирования дискретных или непрерывных данных. Другими словами, гистограмма обеспечивает визуальную интерпретацию числовых данных, показывая, что гистограмма A - это тип графика, который имеет широкое применение в статистике. Гистограммы обеспечивают визуальную интерпретацию числовых данных, указывая количество точек данных, лежащих в пределах диапазона значений.Эти диапазоны значений называются классами или ячейками. Частота данных, попадающих в каждый класс, отображается с помощью столбца.
Псевдокод гистограммы
Псевдокод для алгоритма вычисления гистограммы., Скачать научную диаграмму | Псевдокод алгоритма вычисления гистограммы. из публикации: Легкий подсчет людей и легкая локализация Это домашнее задание? Я бы начал с листа бумаги и набросал, что должна выводить программа.Выясните, как это сделать, напишите код и протестируйте его.
Алгоритм гистограммы, Рассмотрим функцию псевдокода ниже, которую можно использовать для выполнения многопоточной версии вычисления гистограммы. внутренняя гистограмма [HIST_BINS]. [Обработка изображений] Псевдокод для создания гистограммы серого изображения Привет, я готовлюсь к экзамену, просматривая прошлые статьи, и есть раздел, посвященный гистограммам серого изображения.
[Обработка изображений] Псевдокод для создания гистограммы серого, Однако я не понимаю, как бы я реализовал для этого псевдокод.Я считаю, что понимаю, как формируется сама гистограмма, поскольку она представляет частоту пересечения гистограммы, что является эффективным способом сопоставления гистограмм. Его сложность линейна от количества элементов в гистограммах. Две гистограммы 16 × 16 × 8 могут быть сопоставлены за 2 миллисекунды на SUN Sparestation 1 (машина 12 MIP RISC). Сами гистограммы можно эффективно вычислять с помощью оборудования для параллельной обработки изображений.
Гистограмма массива
numpy.histogram, краев интервала, включая крайний правый край, с учетом неравномерной ширины интервала.Гистограмма вычисляется по сглаженному массиву. bins int или последовательность скаляров или str, необязательно. Если bins имеет тип int, он определяет количество интервалов одинаковой ширины в заданном диапазоне (по умолчанию 10). Если ячейки являются последовательностью, она определяет монотонно увеличивающийся массив краев ячейки, включая крайний правый край, что позволяет использовать неоднородную ширину ячейки.
Построение гистограммы из массива, Вместо прямого вызова plt.hist попробуйте использовать subplot и построить внутри него гистограмму, например: import matplotlib.pyplot as plt # define window Программа для построения гистограммы массива. Для массива целых чисел выведите гистограмму значений массива. Примеры: Вход: 0 11 2 13 5 12 8 11 12 9 Выход: 13 | х 12 | х х х 11 | х х х х х 10 | х х х х х 9 | х х х х х х 8 | х х х х х х х 7 | х х х х х х х 6 | х х х х х х х 5 | х х х х х х х х 4 | х х х х х х х х 3 | х х х х х х х х 2 | х х х х х х х х х 1 | х х х х х х х х х 0 | xxxxxxxxxx --------------------------------------- 0 11 2 13 5 12 8 11 12 9 Ввод: 10 9 12 4 5 2 8 5 3 1
NumPy - Гистограмма Используя Matplotlib, функция гистограммы () принимает входной массив и ячейки как два параметра.Последовательные элементы в массиве бункеров действуют как граница каждого бункера. import numpy as np Пример массива: a = np.array ([1,2,3,4,4,4,2,1,1,1,1]) Я хочу создать гистограмму из массива, и если Я использую гистограмму matplotlib.pyplot: import matplotlib.pyplot as plt plt.hist (a, bins = [1,2,3,4,5]) Я получаю следующее: Как мне получить столбцы разных цветов? и как получить метки, например, если зеленый столбец в легенде показывает номер 1 зеленого цвета.
Другие статьи
Кредиторская задолженность Microsoft Dynamics
Внедрение Microsoft Dynamics SL, консультации и поддержка для растущего бизнеса.Microsoft Dynamics SL, ранее называвшаяся Solomon, представляет собой программное обеспечение для планирования ресурсов предприятия (ERP), подходящее для проектно-ориентированных отраслей, включая профессиональные услуги, инжиниринг, государственные контракты и строительство. Наши бизнес-проверки NetSuite имеют встроенные функции безопасности проверки, нажмите, чтобы узнать подробности, наши бизнес-проверки Microsoft Dynamics GP (Great Plains) гарантируют гибкость как для многоцелевого использования, так и для счетов к оплате и начисления заработной платы. Установите флажок, если вы хотите, чтобы проверки Microsoft Dynamics GP (Great Plains) с линиями или без них, варианты обратной нумерации и для одной или двух строк подписи были доступны.
2 октября 2018 г. · Возможности Microsoft Dynamics GP 2018 R2 Этот курс / модуль был создан для партнеров и клиентов. Функции Microsoft Dynamics GP 2018 R2 построены на улучшении основного приложения и платформы. После этого курса / модуля вы сможете: Понимать ключевые области функции Microsoft Dynamics GP 2018 R2: Рабочий процесс Финансы Человечество ... Innovation Expo 2017 - это стартовая площадка для новых инноваций и лучших в своем классе технологий в Microsoft Dynamics. сообщество.Зарегистрируйтесь на эту БЕСПЛАТНУЮ виртуальную выставку! Пожалуйста, завершите регистрацию ниже.
Копирование категорий учетных записей между компаниями Microsoft Dynamics GP Вторник, 3 сентября 2019 г., суббота, 17 августа 2019 г. Ян Грив 3 минуты прочтения 2 комментария При внедрении Microsoft Dynamics GP для нового клиента у них обычно очень похожие настройки для разных компаний. Этот модуль представляет собой введение в Счета к оплате. Он знакомит с ключевыми концепциями и функциями, включая настройку, ввод транзакций, обработку проверок и отчетность.
26 октября 2014 г. · Корпоративное планирование ресурсов Microsoft Dynamics AX. Воскресенье, 26 октября 2014 г. Импорт модуля «Вся кредиторская задолженность» Для расчетов с кредиторской задолженностью самое время, как в реальном времени. С помощью программного обеспечения для расчетов с поставщиками Sage Intacct вы можете отслеживать и просматривать счета-фактуры и платежи, утверждения и отчеты - в любое время и в любом месте. Просматривайте отчеты о кредиторской задолженности и устаревших поставщиках, выставляйте счета и проверяйте отчеты регистров по всему бизнесу в режиме реального времени.
график гистограммы ggplot2: Краткое руководство - Программное обеспечение R и визуализация данных - Easy Guides - Wiki
В этом руководстве R описывается, как создать график гистограммы с помощью программного обеспечения R и пакета ggplot2 .
Используется функция geom_histogram () . Вы также можете добавить линию для среднего значения, используя функцию geom_vline.
Будут использованы данные ниже:
набор. Семян (1234)
df
## пол вес
## 1 F 49
## 2 F 56
## 3 F 60
## 4 F 43
## 5 F 57
## 6 F 58
библиотека (ggplot2)
# Базовая гистограмма
ggplot (df, aes (x = вес)) + geom_histogram ()
# Изменить ширину бункеров
ggplot (df, aes (x = вес)) +
geom_histogram (ширина бина = 1)
# Изменить цвета
п
- Гистограмма строится с плотностью, а не счетом по оси Y
- Наложение с прозрачным графиком плотности.Значение альфа контролирует уровень прозрачности
# Добавить среднюю строку
p + geom_vline (aes (xintercept = среднее (вес)),
color = "blue", linetype = "dashed", size = 1)
# Гистограмма с графиком плотности
ggplot (df, aes (x = вес)) +
geom_histogram (aes (y = .. плотность ..), color = "black", fill = "white") +
geom_de density (альфа = .2, fill = "# FF6666")
Подробнее о типах линий ggplot2: типы линий ggplot2
# Изменить цвет линии и цвет заливки
ggplot (df, aes (x = вес)) +
geom_histogram (color = "darkblue", fill = "lightblue")
# Изменить тип линии
ggplot (df, aes (x = вес)) +
geom_histogram (color = "черный", fill = "голубой",
linetype = "пунктирная")
Рассчитайте среднее значение для каждой группы:
Пакет plyr используется для расчета среднего веса каждой группы:
библиотека (plyr)
му
## пол гр.иметь в виду
## 1 F 54.70
## 2 M 65.36
Изменить цвет линий
Цветами линий графика гистограммы можно автоматически управлять уровнями переменной , пол .
Обратите внимание, что вы можете изменить настройку положения, чтобы использовать для перекрытия точек на слое. Возможные значения для позиции аргумента : «identity», «stack», «dodge». Значение по умолчанию - «стек».
# Изменение цвета линии графика гистограммы по группам
ggplot (df, aes (x = вес, цвет = пол)) +
geom_histogram (fill = "белый")
# Наложенные гистограммы
ggplot (df, aes (x = вес, цвет = пол)) +
geom_histogram (fill = "white", альфа = 0.5, position = "identity")
# Гистограммы с чередованием
ggplot (df, aes (x = вес, цвет = пол)) +
geom_histogram (fill = "white", position = "dodge") +
тема (legend.position = "top")
# Добавить средние линии
п
Также можно изменить вручную цвета линии графика гистограммы с помощью функций:
- scale_color_manual () : использовать собственные цвета
- scale_color_brewer () : для использования цветовых палитр из пакета RColorBrewer
- scale_color_grey () : использовать палитры серого
# Использовать собственные цветовые палитры
p + scale_color_manual (values = c ("# 999999", "# E69F00", "# 56B4E9"))
# Используйте цветовые палитры пивоварни
p + scale_color_brewer (palette = "Dark2")
# Использовать шкалу серого
p + scale_color_grey () + theme_classic () +
тема (легенда.position = "top")
Подробнее о цветах ggplot2 здесь: ggplot2 colors
p + тема (legend.position = "top")
p + тема (legend.position = "bottom")
# Удалить легенду
p + theme (legend.position = "none")
Допустимые значения аргументов legend.position : «левый», «верхний», «правый», «нижний».
Подробнее на ggplot legends: ggplot2 legends
Разделить график на несколько панелей:
п.
Подробнее о фасетах: ggplot2 фасеты
# Базовая гистограмма
ggplot (df, aes (x = вес, fill = пол)) +
geom_histogram (fill = "white", color = "black") +
geom_vline (aes (xintercept = mean (weight)), color = "blue",
linetype = "пунктирная") +
labs (title = "График гистограммы веса", x = "Вес (кг)", y = "Количество") +
theme_classic ()
# Меняем цвета линий по группам
ggplot (df, aes (x = вес, цвет = пол, заливка = пол)) +
geom_histogram (position = "identity", альфа = 0.5) +
geom_vline (data = mu, aes (xintercept = grp.mean, color = sex),
linetype = "пунктирная") +
scale_color_manual (values = c ("# 999999", "# E69F00", "# 56B4E9")) +
scale_fill_manual (values = c ("# 999999", "# E69F00", "# 56B4E9")) +
labs (title = "График гистограммы веса", x = "Вес (кг)", y = "Количество") +
тема_classic ()
Объединить гистограмму и графики плотности:
# Изменение цвета линий по группам
ggplot (df, aes (x = вес, цвет = пол, заливка = пол)) +
geom_histogram (aes (y =.. плотность ..), позиция = "идентичность", альфа = 0,5) +
geom_de density (альфа = 0,6) +
geom_vline (data = mu, aes (xintercept = grp.mean, color = sex),
linetype = "пунктирная") +
scale_color_manual (values = c ("# 999999", "# E69F00", "# 56B4E9")) +
scale_fill_manual (values = c ("# 999999", "# E69F00", "# 56B4E9")) +
labs (title = "График гистограммы веса", x = "Вес (кг)", y = "Плотность") +
тема_classic ()
Изменить цвета линий вручную:
п.
Подробнее о цветах ggplot2 здесь: ggplot2 colors
Rekordbox отмечает
списком тегов rekordbox.Список тегов rekordbox можно совместно использовать в интерактивном режиме между вашим компьютером и любыми DJ проигрывателями, подключенными к локальной сети. Эта функция удобна для выбора треков во время живых выступлений с попеременным использованием нескольких DJ-плееров. Связывание и совместное использование музыкальных файлов и данных с DJ-устройствами. USB EXPORT My Tag, позволяющий добавлять собственные теги к дорожкам или группам дорожек; Связанные треки на основе тегов; Новый диспетчер синхронизации, включая возможность синхронизации плейлистов; Посмотрите видео выше, чтобы увидеть экскурсию по Eat Everything и Kissy Sellout, или загрузите Rekordbox 3.0 бесплатно здесь.
Тегами являются, например, «Балеарские острова, клуб, отдых» или «Техно, склад, клуб», для которых можно создавать интеллектуальные списки воспроизведения на основе этих тегов. Я перемещаю свою библиотеку в Rekordbox, есть ли простой способ скопировать эти теги в поле «Мой тег», или мне придется повторно вводить их все вручную? Система «Мои теги» в Rekordbox DJ - отличный способ помочь распределить треки по категориям по настраиваемым полям, которые впоследствии можно будет фильтровать. Вы можете открыть панель «Мои теги» в правой части библиотеки. После открытия вы увидите теги по умолчанию, которые входят в стандартную комплектацию Rekordbox.
скриншота для rekordbox. Управляйте музыкальными библиотеками и лучше систематизируйте свои треки. ... Сортировка тегов iTunes. Пишите или редактируйте теги сразу для нескольких треков iTunes. 1.2. БЕСПЛАТНО.
Rekordbox 5 Rekordbox dj 5 Full Crack Программное обеспечение для повышения производительности лицензионного ключа дает вам гибкость в использовании единой библиотеки rekordbox для управления музыкой, подготовки треков и исполнения наборов - независимо от того, предпочитаете ли вы играть с помощью контроллеров, CDJ или XDJ. как я могу создавать теги, видимые в Rekordbox и Serato? Ответ №2 - 2015-08-28 17:27:51 Полагаю, эти программы поддерживают запись собственных тегов? если это так, посмотрите, доступны ли они для просмотра в foobar через диалог свойств.если они есть, вы можете пометить их в foobar. если вы их не видите, вам придется использовать что-то другое.
Бесплатное. Бесплатные программы можно загружать бесплатно и без каких-либо ограничений по времени. Бесплатные продукты можно использовать бесплатно как в личных, так и в профессиональных целях (коммерческое использование).
Контроллер Pioneer Limited Edition DDJ-400-N - это портативный самородок с золотым покрытием для точного диджеинга. Элегантный контроллер только укрепляет статус Pioneer как лидера индустрии ди-джеев.
27 марта 2018 г. · Отметьте отличные пары песен в поле комментариев - «Комментарии» - это текстовое поле в музыкальных файлах, которое позволяет добавлять комментарии к трекам - вы можете отобразить его в виде столбца в программном обеспечении DJ и отсортировать, поиск и фильтрация по нему. Например, если вы найдете песню, которая действительно хорошо сочетается с другой песней, почему бы не написать короткую заметку, чтобы побудить вас ... использовать библиотеку, сохраненную в формате rekordbox xml, или библиотеку в других музыкальных приложениях. Дорожки также можно добавлять из потоковой передачи, облака и мобильных устройств.В режиме PERFORMANCE также можно добавлять видеофайлы. Для получения дополнительной информации см. «Руководство по эксплуатации rekordbox video» на веб-сайте rekordbox. 1 Щелкните [Коллекция] в древовидной структуре.
CBT создает на целевом диске так называемый файл «Rekordbox.xml» или «iTunes Music Library.xml». Этот XML-файл является идентичным представлением вашей коллекции, включая папки / списки воспроизведения, а когда дело доходит до Rekordbox, даже реплики, петли и т. Д.
Теги: например, «Балеарские, клубные, холодные» или «Техно, складские». , club », для которого можно создавать умные плейлисты на основе этих тегов.Я перемещаю свою библиотеку в Rekordbox, есть ли простой способ скопировать эти теги в поле «Мой тег», или мне придется повторно вводить их все вручную?
rekordbox вер. 6.4.2 была выпущена - 22 декабря 2020 г. 21 декабря 2020 г. 01:41 0 голосов 0 комментариев Решено: совместимость с macOS Catalina 10.15 Экспортируйте всю коллекцию в XML, в Rekordbox выберите «Файл», а затем «Экспортировать коллекцию в формате xml». Найдите свой XML-файл и откройте его в текстовом редакторе (например, в блокноте или аналоге для Mac).Найдите свой трек по его названию, используя функцию поиска в текстовом редакторе. Выделите дорожку, начиная с тега
• Работа в 5 раз быстрее, 100% качество без потерь и теги ID3. Ниже приводится подробное руководство о том, как загружать песни Spotify в файлы MP3 с помощью Tunelf Spotify Music to Rekordbox Converter. 12 ноября 2019 г. · Rekordbox DJ Crack Полный серийный ключ {Latest} Rekordbox DJ 5.8.0 Crack для Mac Windows - лучшее программное обеспечение для аранжировки ваших треков в студии, дома или даже на корабле! Это позволяет вам перемещать или копировать музыку из других программ для аранжировки музыки.Таким образом, используя функцию моста, или суммируя их в программе […] Tag & Image Finder. Найдите недостающие теги и обложки для ваших треков. Редактор треков. ... Переместите файлы, чтобы Rekordbox, Traktor и VirtualDJ могли снова их найти.
Функции DJ-исполнения в rekordbox называются rekordbox dj. Чтобы использовать rekordbox dj, введите лицензионный ключ на карту лицензионных ключей rekordbox dj, прилагаемую к этому продукту. Информация о тегах не отображается. Ferranlozano Домашний пользователь Участник с 2020 г. Привет, я хочу сделать процесс в обратном порядке... У меня есть все в Rekordbox, и я хочу экспортировать свои списки в Virtual DJ. 16 декабря 2012 г. · Параметры тегов позволяют работать с различными шаблонами для организации файлов, а кнопка «Токены» позволяет просматривать все доступные шаблоны. Любые файлы с отсутствующими тегами будут помещены в отдельную папку. Вы можете указать имя этой папки в поле «Missing tag text».
Разработанный специально для использования с программным обеспечением rekordbox dj от Pioneer, Pioneer DDJ-1000 предлагает полноразмерный интерфейс в клубном стиле с профессиональными функциями - все в компактном портативном корпусе.Диджеи, знакомые с флагманским автономным 4-канальным микшером и CDJ-плеером Pioneer, будут чувствовать себя как дома, когда сядут за руль этого профессионального контроллера. Все выглядит, ощущается и ... 18 апр.2020 г. · Rekordbox 6.0 от Pioneer DJ предлагает множество новых функций. Программное обеспечение Rekordbox от Pioneer DJ, широко признанное ди-джеями в качестве отраслевого стандарта, только что получило масштабное обновление, которое добавляет как захватывающие новые функции, так и улучшает существующие.
rekordbox - это программа, позволяющая пользователям, которые приобрели DJ-проигрыватель Pioneer с поддержкой rekordbox, управлять музыкальными файлами, которые будут использоваться для DJ-выступлений.Прилагаемое программное обеспечение для управления музыкой rekordbox можно использовать для управления (анализа, настройки, создания, хранения истории) музыкальных файлов на компьютерах.
12 июля, 2017 · Тег: rekordbox Как записать микстейп менее чем за неделю. 12 июля 2017 г. 12 июля 2017 г. Я мама, жена и диджей. Планирование - вот как я сохраняю рассудок, но иногда ... AlphaTheta Pioneer DJ rekordbox v6.0.1 Чисто профессиональное исполнение. Без ожидания. rekordbox dj объединяет весь превосходный опыт Pioneer в области ди-джеев в одном пакете, чтобы создать самое быстрое и стабильное программное обеспечение в отрасли с превосходным качеством звука.вер. 6.0.1 (2020.05.26) НОВАЯ поддержка потокового сервиса Beatsource LINK. Добавлена функция вокального анализа, которая обнаруживает и отображает вокал […]
Лицензионный ключ RekordBox DJ - лучший способ подготовки треков и управления ими дома, в студии или в самолете. Используя функцию моста, он позволяет импортировать музыку из другого программного обеспечения для управления музыкой или добавлять ее в программное обеспечение для управления. Мастерская Rekordbox DJ Playlisten и теги: DJ-программа Pioneers с использованием zahlreiche Funktionen, фильтрация и поиск тегов Система тегов для eure Musik-Library, einem das Leben als DJ...
01 июля, 2019 · Благодаря тому, что rekordbox позволяет ди-джеям упорядочивать музыкальные файлы перед выступлением, интеграция с Beatport LINK, которая дает исполнителям доступ к полному каталогу Beatport непосредственно из программного обеспечения для ди-джеев ...
Совместимость Plug and Play с rekordbox и Serato DJ Pro Благодаря встроенной звуковой карте и поддержке функций DJ Performance в rekordbox (эквивалент плана Core) и Serato DJ Pro, все, что вам нужно сделать, это подключить DDJ-FLX6 через USB-кабель к ноутбуку это работает с любым программным приложением, и вы можете начать диджеить.Или используйте поддержку HID для воспроизведения со своего ноутбука с помощью настройки CDJ или XDJ. rekordbox dj дает вам доступ не только к музыке. Весь ваш набор, вместе с репликами и тегами, можно использовать на разных платформах и устройствах, а вы с легкостью унифицируете управляемые музыкальные треки. Как только у вас будет прокат rekordbox dj, без сомнения, шоу продолжится.
Quick-R: графики плотности
Гистограммы
Вы можете создавать гистограммы с помощью функции hist ( x ) , где x - числовой вектор значений, которые должны быть нанесены на график.Параметр freq = FALSE отображает плотности вероятностей вместо частот. Параметр breaks = управляет количеством ячеек.
# Простая гистограмма
hist (mtcars $ mpg)
нажмите для просмотра
# Цветная гистограмма с разным количеством ячеек
hist (mtcars $ mpg, breaks = 12, col = "red")
нажмите для просмотра
# Добавить нормальную кривую (спасибо Питеру Далгаарду)
x <- mtcars $ mpg
h <-hist (x, breaks = 10, col = "red", xlab = "Miles Per Gallon",
main = " Гистограмма с нормальной кривой ")
xfit <-seq (min (x), max (x), length = 40)
yfit <-dnorm (xfit, mean = mean (x), sd = sd (x))
yfit <- yfit * diff (h $ mids [1: 2]) * length (x)
строк (xfit, yfit, col = "blue", lwd = 2)
нажмите для просмотра
Гистограммы могут быть плохим методом определения формы распределения, потому что на нее сильно влияет количество используемых интервалов.
Чтобы попрактиковаться в построении графика плотности с помощью функции hist (), попробуйте это упражнение.
Графики плотности ядра
Графики плотности ядра обычно являются гораздо более эффективным способом просмотра распределения переменной. Создайте график, используя график (плотность ( x )) , где x - числовой вектор.
# График плотности ядра
d <- density (mtcars $ mpg) # возвращает данные плотности
plot (d) # отображает результаты
нажмите для просмотра
# Заполненный график плотности
d <- density (mtcars $ mpg)
plot (d, main = "Kernel Density of Miles Per Gallon")
polygon (d, col = "red", border = "blue")
нажмите для просмотра
Сравнение групп по плотности ядра
см.Функция density.compare () в пакете sm позволяет наложить графики ядерной плотности двух или более групп. Формат: см. Плотность. Сравнение ( x , фактор ), где x - числовой вектор, а фактор - группирующая переменная.
# Сравните раздачи MPG для автомобилей с
#
4,6 или 8 цилиндров
библиотека (см)
прикрепление (mtcars)
# создание ярлыков значений
цилиндров.f <- коэффициент (цилиндр, уровни = c (4,6,8),
метки = c («4 цилиндр», «6 цилиндр», «8 цилиндр»))
# плотностей графика
см. плотность. сравните (mpg, cyl, xlab = "Miles Per Gallon")
title (main = "Распределение MPG по автомобильным цилиндрам")
# добавить легенду щелчком мыши
colfill <-c (2: (2 + length (levels (cyl .f))))
легенда (локатор (1), уровни (cyl.f), fill = colfill)
нажмите для просмотра
.