Шампунь для волос Naturasept 250 мл.
Перхоть – одна из самых распространённых причин обращения к трихологам. Недугу подвержены все, мужчины и женщины любого возраста и статуса. Чаще всего, эта проблема появляется у тех пациентов, чьи сальные железы выделяют чрезмерное количество секрета, делая кожу головы и волосы жирными. Если не лечить перхоть, то она очень быстро превратится в тяжёлый себорейный дерматит, а это уже не только косметологическая, но и медицинская проблема. Среди первых симптомов – зуд, раздражение эпидермиса волосистой части головы, появление белёсых чешуек. Чтобы не допустить распространение перхоти, важно применять лечебные шампуни с нейтральным уровнем Ph (5,5).
Производитель: Artlife
Форма выпуска: 250 мл
Возраст: 12+
Здоровье в каждой капле
Специалисты компании Арт Лайф – лидера по производству натуральных продуктов для красоты и здоровья, разработали эффективный противосеборейный шампунь, который вошёл в серию Natur asept.
Шампунь имеет нейтральный уровень Ph. Это поддерживает эпидермис головы в здоровом состоянии и препятствует появлению патогенных бактерий, для которых более благоприятна щелочная среда. Мягкое средство бережно очищает волосы и кожу, выравнивает их структуру и поддерживает нормальный уровень влажности. Волосы получают необходимое питание и приобретают сияющий вид без эффекта утяжеления. Natur asept-шампунь подходит для ежедневного применения, он не содержит красителей и отдушек.
Действующие компоненты:
Основным противосеборейным компонентом средства является масляная вытяжка чайного дерева – самого эффективного природного антисептика. Это вещество прекрасно борется с любыми патогенными бактериями, оказывает противовоспалительное и регенерирующее действие.
Экстракт березы в сочетании с противогрибковым комплексом «Климбазол» нормализуют секрецию сальных желёз, препятствуют появлению и распространению грибка Pityrosporum ovale – основной причины перхоти.
Состав:
- разработка компании – комплекс «Климбазол» вытяжка березы
- масло чайного дерева
- лимонная кислота
- натрия лаурет сульфат 70%
- подготовленная вода
- кокамидопропил бетаин
- трилон Б ЭДТА Б
- кремафор RH 410
- метилизотиазолинон
- кокамид ДЭА
- метилхлороизотиазолинон
- алкилгликозид
- лаурет-2
- бензиловый спирт
- протелан AGL 95 С
- ЦЕТИОЛ НЕ
- целкват SC 240C
- Д-пантенол
- ПЭГ 120.
Инструкция по применению:
Небольшое количество нанести на влажные волосы, интенсивно вспенить, смыть. Для достижения максимального эффекта, рекомендуется использовать бальзам из этой же серии.
Для достижения максимального эффекта, рекомендуется использовать бальзам из этой же серии.
*Бад не является лекарством
поезда и развертывание пользовательской модели ML, поддерживаемой GPU на Amazon Sagemaker
, созданная Ankur Shukla (AWS)
| Среда: POC или пилот | Technologies: Matcher Leving & AI; Контейнеры и микросервисы | Сервисы AWS: Amazon ECS; Amazon SageMaker |
Сводка
Для обучения и развертывания модели машинного обучения (ML) с поддержкой графического процессора (GPU) требуется первоначальная настройка и инициализация определенных переменных среды, чтобы полностью раскрыть преимущества графических процессоров NVIDIA. Однако настройка среды и обеспечение ее совместимости с архитектурой Amazon SageMaker в облаке Amazon Web Services (AWS) может занять много времени.
Этот шаблон помогает обучать и создавать пользовательскую модель машинного обучения с поддержкой графического процессора с помощью Amazon SageMaker. Он предоставляет шаги для обучения и развертывания пользовательской модели CatBoost, построенной на наборе данных обзоров Amazon с открытым исходным кодом. Затем вы можете оценить его производительность на экземпляре
Он предоставляет шаги для обучения и развертывания пользовательской модели CatBoost, построенной на наборе данных обзоров Amazon с открытым исходным кодом. Затем вы можете оценить его производительность на экземпляре p3.16xlarge Amazon Elastic Compute Cloud (Amazon EC2).
Этот шаблон полезен, если ваша организация хочет развернуть существующие модели машинного обучения с поддержкой графического процессора в SageMaker. Ваши специалисты по обработке и анализу данных могут выполнить действия, описанные в этом шаблоне, для создания контейнеров с поддержкой графического процессора NVIDIA и развертывания моделей машинного обучения в этих контейнерах.
Предварительные условия и ограничения
Предварительные требования
-
Активный аккаунт AWS.
-
Исходный сегмент Amazon Simple Storage Service (Amazon S3) для хранения артефактов модели и прогнозов.
-
Понимание экземпляров блокнотов SageMaker и блокнотов Jupyter.

-
Понимание того, как создать роль AWS Identity and Access Management (IAM) с базовыми разрешениями роли SageMaker, доступом к корзине S3 и разрешениями на обновление, а также дополнительными разрешениями для Amazon Elastic Container Registry (Amazon ECR).
Limitations
Architecture
Technology stack
-
SageMaker
-
Amazon ECR
Tools
Tools
-
Amazon ECR – Amazon Elastic Container Registry (Amazon ECR) — это безопасный, масштабируемый и надежный сервис реестра образов контейнеров, управляемый AWS.
-
Amazon SageMaker — SageMaker — это полностью управляемый сервис машинного обучения.
-
Docker — это программная платформа для быстрого создания, тестирования и развертывания приложений.
-
Python — Python — это язык программирования.

Код
Код для этого шаблона доступен на GitHub Реализация модели классификации обзоров с репозиторием Catboost и SageMaker.
Эпики
| Задание | Описание | Требуемые навыки |
|---|---|---|
| Создайте роль IAM и прикрепите необходимые политики. | Войдите в консоль управления AWS, откройте консоль IAM и создайте новую роль IAM. Прикрепите следующие политики к роли IAM: Дополнительные сведения об этом см. в разделе Создание экземпляра записной книжки в документации по Amazon SageMaker. | Специалист по данным |
| Создайте экземпляр блокнота SageMaker. | Откройте консоль SageMaker, выберите Экземпляры записной книжки , а затем выберите Создать экземпляр записной книжки . Для роли IAM выберите роль IAM, созданную ранее. Настройте экземпляр записной книжки в соответствии с вашими требованиями, а затем выберите Создать экземпляр записной книжки . Подробные шаги и инструкции см. в разделе Создание экземпляра записной книжки документации Amazon SageMaker. | Специалист по данным |
| Клонировать репозиторий. | Откройте терминал в экземпляре ноутбука SageMaker и клонируйте GitHub. Реализация модели классификации обзоров с помощью репозитория Catboost и SageMaker, выполнив следующую команду: | |
| Запустите блокнот Jupyter. | Запустите модель классификации | Специалист по данным |

| Задача | Описание | Требуемые навыки |
|---|---|---|
| Запуск команд в блокноте Jupyter. | Откройте блокнот Jupyter и выполните команды из следующих историй, чтобы подготовить данные для обучения вашей модели ML. | Специалист по данным |
| Считайте данные из корзины S3. | | Специалист по данным |
| Предварительно обработайте данные. | Примечание : Этот код заменяет нулевые значения в 'Unk' , что означает «неизвестно».
| Специалист по данным |
| Разделите данные на обучающие, проверочные и тестовые наборы данных. | Чтобы сохранить идентичное распределение целевой метки в разделенных наборах, необходимо стратифицировать выборку с помощью библиотеки scikit-learn. | Специалист по данным |

| Задача | Описание | Требуемые навыки |
|---|---|---|
. Подготовьте и отправьте образ Docker. Подготовьте и отправьте образ Docker. | В блокноте Jupyter выполните команды из следующих историй, чтобы подготовить образ Docker и отправить его в Amazon ECR. | Инженер машинного обучения |
| Создайте репозиторий в Amazon ECR. | | Инженер машинного обучения |
| Создайте образ Docker локально. | | Инженер машинного обучения |
Запустите образ Docker и отправьте его в Amazon ECR. | | Инженер машинного обучения |
| Задача | Описание | 901|
|---|---|---|
| Создайте задание настройки гиперпараметров SageMaker. | В блокноте Jupyter выполните команды из следующих статей, чтобы создать задание настройки гиперпараметров SageMaker с использованием образа Docker. | Специалист по данным |
| Создайте оценщик SageMaker. | Создайте средство оценки SageMaker, используя имя образа Docker.
| Специалист по данным |
| Создать задание HPO. | Создайте задание настройки оптимизации гиперпараметров (HPO) с диапазонами параметров и передайте наборы обучения и проверки в качестве параметров функции. | Специалист по данным |
| Запустить задание HPO. | | Специалист по данным |
| Получите лучшую работу по обучению. | | Data Scientist |
 format(учетная запись, регион)
tree_hpo = sage.estimator.Estimator(изображение,
роль, 1,
'мл.p3.16xlarge',
train_volume_size = 100,
output_path="s3://{}/sagemaker/DEMO-GPU-Catboost/output".format(bucket),
sagemaker_session=сеанс)
format(учетная запись, регион)
tree_hpo = sage.estimator.Estimator(изображение,
роль, 1,
'мл.p3.16xlarge',
train_volume_size = 100,
output_path="s3://{}/sagemaker/DEMO-GPU-Catboost/output".format(bucket),
sagemaker_session=сеанс)  ]+)'}]
тюнер = ГиперпараметрТюнер(tree_hpo,
target_metric_name,
гиперпараметр_диапазоны,
метрика_определения,
target_type = 'Максимум',
макс_работ = 50,
max_parallel_jobs=2)
]+)'}]
тюнер = ГиперпараметрТюнер(tree_hpo,
target_metric_name,
гиперпараметр_диапазоны,
метрика_определения,
target_type = 'Максимум',
макс_работ = 50,
max_parallel_jobs=2) | Задача | Описание | Требуется навыки |
|---|---|---|
| В записной книжке Jupyter выполните команды из следующих историй, чтобы создать модель из задания настройки гиперпараметров SageMaker и отправить задание пакетного преобразования SageMaker для тестовых данных для прогнозирования модели. | Специалист по данным | |
| Создайте модель SageMaker. | Создайте модель в SageMaker, используя лучшее обучающее задание. | Специалист по данным |
Создать задание пакетного преобразования. | Создать задание пакетного преобразования набора тестовых данных. | Специалист по обработке и анализу данных |
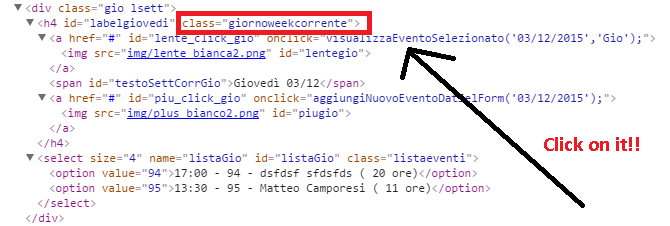
| Задача | Описание | Требуемые навыки |
|---|
В записной книжке Jupyter запустите команды из следующих историй, чтобы прочитать результаты и оценить производительность модели в модели Area Under the ROC Curve (ROC-AUC) и Area Under the Precision Recall Curve (PR-AUC). метрики.
Дополнительные сведения об этом см. в разделе Ключевые концепции машинного обучения Amazon в документации по машинному обучению Amazon (Amazon ML).
Чтение результатов задания пакетного преобразования во фрейм данных.
имя_файла = 's3://'+bucket+'/sagemaker/DEMO-GPU-Catboost/data/test-predictions/file_1.out'
результаты = pd.read_csv(имя_файла, имена=['review_id','цель','оценка'], sep='\t',escapechar ='\\' , quoting=csv.QUOTE_NONE,
lineterminator='\n',quotechar='"').dropna() Оценить производительность модели на ROC-AUC и PR-AUC.
из показателей импорта sklearn
импортировать matplotlib
импортировать панд как pd
matplotlib.use('agg', предупреждение=False, сила=True)
из matplotlib импортировать pyplot как plt
%matplotlib встроенный
def analysis_results (метки, прогнозы):
точность, отзыв, пороги = metrics.precision_recall_curve (метки, прогнозы)
auc = metrics.auc(отзыв, точность)
fpr, tpr, _ = metrics.roc_curve (метки, прогнозы)
roc_auc_score = metrics.roc_auc_score (метки, прогнозы)
print('Нейронные сети: ROC auc=%. 3f' % ( roc_auc_score))
plt.plot(fpr, tpr, label="data 1, auc=" + str(roc_auc_score))
plt.xlabel('1-специфичность')
plt.ylabel('Чувствительность')
plt.legend(loc=4)
plt.show()
lr_precision, lr_recall, _ = metrics.precision_recall_curve (метки, прогнозы)
lr_auc = metrics.auc(lr_recall, lr_precision)
# подвести итоги
print('Нейронные сети: PR auc=%.3f' % ( lr_auc))
# построить кривые точности-отзыва
no_skill = длина (метки [метки == 1.0]) / длина (метки)
plt.plot([0, 1], [no_skill, no_skill], linestyle='--', label='Нет навыков')
plt.plot(lr_recall, lr_precision, marker='.', label='Нейронные сети')
# метки осей
plt.xlabel('Отзыв')
plt.ylabel('Точность')
# показать легенду
plt.legend()
# показать сюжет
plt.show()
возврат аукциона
analysis_results(результаты['цель'].значения,результаты['оценка'].значения)
3f' % ( roc_auc_score))
plt.plot(fpr, tpr, label="data 1, auc=" + str(roc_auc_score))
plt.xlabel('1-специфичность')
plt.ylabel('Чувствительность')
plt.legend(loc=4)
plt.show()
lr_precision, lr_recall, _ = metrics.precision_recall_curve (метки, прогнозы)
lr_auc = metrics.auc(lr_recall, lr_precision)
# подвести итоги
print('Нейронные сети: PR auc=%.3f' % ( lr_auc))
# построить кривые точности-отзыва
no_skill = длина (метки [метки == 1.0]) / длина (метки)
plt.plot([0, 1], [no_skill, no_skill], linestyle='--', label='Нет навыков')
plt.plot(lr_recall, lr_precision, marker='.', label='Нейронные сети')
# метки осей
plt.xlabel('Отзыв')
plt.ylabel('Точность')
# показать легенду
plt.legend()
# показать сюжет
plt.show()
возврат аукциона
analysis_results(результаты['цель'].значения,результаты['оценка'].значения)
-
Обучение и размещение моделей Scikit-Learn в Amazon SageMaker путем создания контейнера Scikit Docker
запустите и отправьте образ Docker в Amazon ECR epic.
Установите Python с помощью aws-cli.
ОТ amazonlinux:1
RUN yum update -y && yum install -y python36 python36-devel python36-libs python36-tools python36-pip && \
yum установить gcc tar make wget util-linux kmod man sudo git -y && \
ням установить wget -y && \
yum установить aws-cli -y && \
yum установить nginx -y && \
yum установить gcc-c++.noarch -y && yum очистить все Установка пакетов Python
RUN pip-3.6 install --no-cache-dir --upgrade pip && \pip3 install --no-cache-dir --upgrade setuptools && \
pip3 установить Cython && \
pip3 install --no-cache-dir numpy==1.16.0 scipy==1.4.1 scikit-learn==0.20.3 pandas==0.24.2 \
flask gevent gunicorn boto3 s3fs matplotlib joblib catboost==0.20.2 Установка CUDA и CuDNN
RUN wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda_9.0.176_384.81_linux-run \
&& chmod u+x cuda_9. 0.176_384.81_linux-run \
&& ./cuda_9.0.176_384.81_linux-run --tmpdir=/data --silent --toolkit --override \
&& wget https://custom-gpu-sagemaker-image.s3.amazonaws.com/installation/cudnn-9.0-linux-x64-v7.tgz \
&& tar -xvzf cudnn-9.0-linux-x64-v7.tgz \
&& cp /data/cuda/include/cudnn.h /usr/local/cuda/include \
&& cp /data/cuda/lib64/libcudnn* /usr/local/cuda/lib64 \
&& chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn* \
&& rm -rf /данные/*
0.176_384.81_linux-run \
&& ./cuda_9.0.176_384.81_linux-run --tmpdir=/data --silent --toolkit --override \
&& wget https://custom-gpu-sagemaker-image.s3.amazonaws.com/installation/cudnn-9.0-linux-x64-v7.tgz \
&& tar -xvzf cudnn-9.0-linux-x64-v7.tgz \
&& cp /data/cuda/include/cudnn.h /usr/local/cuda/include \
&& cp /data/cuda/lib64/libcudnn* /usr/local/cuda/lib64 \
&& chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn* \
&& rm -rf /данные/* Создайте необходимую структуру каталогов для SageMaker data/training /opt/ml/model /opt/ml/output /opt/program
Установить переменные среды NVIDIA
ENV PYTHONPATH=/opt/program
ENV PYTHONUNBUFFERED=ИСТИНА
ENV PYTHONDONTWRITEBYTECODE=ИСТИНА
ENV PATH="/opt/program:${PATH}"
# Установить среду монтирования NVIDIA
ENV LD_LIBRARY_PATH=/usr/local/nvidia/lib:/usr/local/nvidia/lib64:$LD_LIBRARY_PATH
ENV NVIDIA_VISIBLE_DEVICES="все"
ENV NVIDIA_DRIVER_CAPABILITIES="вычисления, утилита"
ENV NVIDIA_REQUIRE_CUDA "cuda>=9. 0"
0" Скопировать файлы обучения и выводов в образ Docker
COPY code/* /opt/program/
WORKDIR /opt/program Javascript отключен или недоступен в вашем браузере.
Чтобы использовать документацию Amazon Web Services, должен быть включен Javascript. Инструкции см. на страницах справки вашего браузера.
Условные обозначения документов
Создание контейнеров Docker в SageMaker для обучения модели в Step Functions
Используйте SageMaker Processing для разработки распределенных признаков наборов данных ML размером в терабайт
Используйте PyTorch для обучения вашей модели классификации изображений
- Статья
- 10 минут на чтение
На предыдущем этапе этого руководства мы получили набор данных, который будем использовать для обучения нашего классификатора изображений с помощью PyTorch. Теперь пришло время использовать эти данные.
Теперь пришло время использовать эти данные.
Чтобы обучить классификатор изображений с помощью PyTorch, необходимо выполнить следующие шаги:
- Загрузите данные. Если вы выполнили предыдущий шаг этого руководства, вы уже справились с этим.
- Определение нейронной сети свертки.
- Определите функцию потерь.
- Обучите модель на обучающих данных.
- Протестируйте сеть на тестовых данных.
Определение нейронной сети свертки.
Чтобы построить нейронную сеть с помощью PyTorch, вы будете использовать факел.nn пакет. Этот пакет содержит модули, расширяемые классы и все необходимые компоненты для построения нейронных сетей.
Здесь вы создадите базовую нейронную сеть свертки (CNN) для классификации изображений из набора данных CIFAR10.
CNN — это класс нейронных сетей, определяемый как многослойные нейронные сети, предназначенные для обнаружения сложных функций в данных. Чаще всего они используются в приложениях компьютерного зрения.
Чаще всего они используются в приложениях компьютерного зрения.
Наша сеть будет состоять из следующих 14 уровней:
Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> MaxPool -> Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> Linear .
Слой свертки
Слой свертки — это основной слой CNN, который помогает нам обнаруживать особенности на изображениях. Каждый из слоев имеет несколько каналов для обнаружения определенных функций на изображениях и несколько ядер для определения размера обнаруженной функции. Следовательно, слой свертки с 64 каналами и размером ядра 3 x 3 обнаружит 64 различных признака, каждый из которых имеет размер 3 x 3. Когда вы определяете слой свертки, вы указываете количество входных каналов, количество выходных каналов. и размер ядра. Количество исходящих каналов в слое служит количеством входящих каналов для следующего уровня.
Например: слой свертки с входными каналами = 3, исходящими каналами = 10 и размером ядра = 6 получит изображение RGB (3 канала) в качестве входных данных и применит к изображениям 10 детекторов признаков. с размером ядра 6×6. Меньшие размеры ядра сократят время вычислений и распределение веса.
с размером ядра 6×6. Меньшие размеры ядра сократят время вычислений и распределение веса.
Другие уровни
Следующие другие уровни участвуют в нашей сети:
- Уровень
ReLUпредставляет собой функцию активации, которая определяет, что все входящие функции равны 0 или выше. Когда вы применяете этот слой, любое число меньше 0 изменяется на ноль, в то время как другие остаются прежними. - слой
BatchNorm2dприменяет нормализацию входных данных, чтобы получить нулевое среднее значение и единичную дисперсию и повысить точность сети. - Слой
MaxPoolпоможет нам добиться того, чтобы расположение объекта на изображении не влияло на способность нейросети обнаруживать его особенности. - Слой
Linearявляется последним слоем в нашей сети, который вычисляет баллы каждого из классов. В наборе данных CIFAR10 есть десять классов меток. Метка с наивысшим баллом будет той, которую предсказывает модель. В линейном слое вы должны указать количество входных объектов и количество выходных объектов, которые должны соответствовать количеству классов.
В линейном слое вы должны указать количество входных объектов и количество выходных объектов, которые должны соответствовать количеству классов.
Как работает нейронная сеть?
CNN — это сеть прямой связи. В процессе обучения сеть будет обрабатывать входные данные по всем слоям, вычислять потери, чтобы понять, насколько прогнозируемая метка изображения отличается от правильной, и передавать градиенты обратно в сеть для обновления весов слои. Перебирая огромный набор входных данных, сеть «научится» устанавливать свои веса для достижения наилучших результатов.
Прямая функция вычисляет значение функции потерь, а обратная функция вычисляет градиенты обучаемых параметров. Когда вы создаете нашу нейронную сеть с помощью PyTorch, вам нужно только определить прямую функцию. Обратная функция будет определена автоматически.
- Скопируйте следующий код в файл
PyTorchTraining.pyв Visual Studio, чтобы определить CCN.
импортная горелка импортировать torch.nn как nn импорт импортировать torch.nn.functional как F # Определяем нейронную сеть свертки Сеть класса (nn.Module): защита __init__(сам): супер(Сеть, я).__init__() self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, шаг=1, отступ=1) self.bn1 = nn.BatchNorm2d(12) self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, шаг=1, отступ=1) self.bn2 = nn.BatchNorm2d(12) self.pool = nn.MaxPool2d (2,2) self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, шаг=1, отступ=1) self.bn4 = nn.BatchNorm2d(24) self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, шаг=1, отступ=1) self.bn5 = nn.BatchNorm2d(24) self.fc1 = nn.Linear(24*10*10, 10) защита вперед (я, ввод): вывод = F.relu (self.bn1 (self.conv1 (ввод))) вывод = F.relu(self.bn2(self.conv2(выход))) вывод = self.pool (выход) вывод = F.relu(self.
bn4(self.conv4(выход))) вывод = F.relu(self.bn5(self.conv5(выход))) вывод = вывод.просмотр(-1, 24*10*10) вывод = self.fc1 (выход) возвратный вывод # Создать модель нейронной сети модель = Сеть()
Примечание
Хотите узнать больше о нейронной сети с PyTorch? Ознакомьтесь с документацией PyTorch
Определение функции потерь
Функция потерь вычисляет значение, которое оценивает, насколько далеко выходной сигнал находится от цели. Основная цель состоит в том, чтобы уменьшить значение функции потерь путем изменения значений вектора весов посредством обратного распространения в нейронных сетях.
Значение потерь отличается от точности модели. Функция потерь дает нам понимание того, насколько хорошо ведет себя модель после каждой итерации оптимизации на обучающем наборе. Точность модели рассчитывается на тестовых данных и показывает процент правильного прогноза.
В PyTorch пакет нейронной сети содержит различные функции потерь, которые образуют строительные блоки глубоких нейронных сетей. В этом руководстве вы будете использовать функцию потерь классификации, основанную на определении функции потерь с потерями классификации кросс-энтропии и оптимизаторе Адама. Скорость обучения (lr) устанавливает контроль над тем, насколько вы корректируете веса нашей сети с учетом градиента потерь. Вы установите его как 0,001. Чем он ниже, тем медленнее будет обучение.
В этом руководстве вы будете использовать функцию потерь классификации, основанную на определении функции потерь с потерями классификации кросс-энтропии и оптимизаторе Адама. Скорость обучения (lr) устанавливает контроль над тем, насколько вы корректируете веса нашей сети с учетом градиента потерь. Вы установите его как 0,001. Чем он ниже, тем медленнее будет обучение.
- Скопируйте следующий код в файл PyTorchTraining.py в Visual Studio, чтобы определить функцию потерь и оптимизатор.
от torch.optim импорт Адам # Определите функцию потерь с классификацией кросс-энтропийных потерь и оптимизатором с оптимизатором Адама. loss_fn = nn.CrossEntropyLoss() оптимизатор = Адам (model.parameters (), lr = 0,001, weight_decay = 0,0001)
Обучите модель на обучающих данных.
Чтобы обучить модель, вы должны перебрать наш итератор данных, передать входные данные в сеть и оптимизировать. PyTorch не имеет специальной библиотеки для использования GPU, но вы можете вручную определить исполнительное устройство. Устройством будет графический процессор Nvidia, если он есть на вашем компьютере, или ваш процессор, если его нет.
Устройством будет графический процессор Nvidia, если он есть на вашем компьютере, или ваш процессор, если его нет.
- Добавьте следующий код в файл
PyTorchTraining.py
из torch.autograd импорт Переменная
# Функция для сохранения модели
защита модели сохранения():
путь = "./myFirstModel.pth"
torch.save (model.state_dict (), путь)
# Функция для проверки модели с помощью тестового набора данных и печати точности для тестовых изображений.
определение точности теста():
модель.eval()
точность = 0,0
всего = 0,0
с факелом.no_grad():
для данных в test_loader:
изображения, метки = данные
# запускаем модель на тестовом наборе для предсказания меток
выходы = модель (изображения)
# метка с наибольшей энергией будет нашим прогнозом
_, предсказано = torch.max (outputs.data, 1)
всего += labels.size(0)
точность += (прогнозируемые == метки). sum().item()
# вычисляем точность по всем тестовым изображениям
точность = (100 * точность / сумма)
возврат (точность)
# Функция обучения. Нам просто нужно перебрать наш итератор данных, передать входные данные в сеть и оптимизировать.
деф поезд (num_epochs):
лучшая_точность = 0,0
# Определите свое исполнительное устройство
устройство = torch.device("cuda:0", если torch.cuda.is_available(), иначе "процессор")
print("Модель будет запущена", устройство, "устройство")
# Преобразование параметров модели и буферов в CPU или Cuda
model.to(устройство)
для эпохи в диапазоне (num_epochs): # цикл по набору данных несколько раз
текущая_потеря = 0,0
run_acc = 0,0
для i (изображения, метки) в перечислении (train_loader, 0):
# получить входные данные
изображения = переменная (images.to (устройство))
labels = Variable(labels.to(device))
# обнуляем градиенты параметров
оптимизатор.
sum().item()
# вычисляем точность по всем тестовым изображениям
точность = (100 * точность / сумма)
возврат (точность)
# Функция обучения. Нам просто нужно перебрать наш итератор данных, передать входные данные в сеть и оптимизировать.
деф поезд (num_epochs):
лучшая_точность = 0,0
# Определите свое исполнительное устройство
устройство = torch.device("cuda:0", если torch.cuda.is_available(), иначе "процессор")
print("Модель будет запущена", устройство, "устройство")
# Преобразование параметров модели и буферов в CPU или Cuda
model.to(устройство)
для эпохи в диапазоне (num_epochs): # цикл по набору данных несколько раз
текущая_потеря = 0,0
run_acc = 0,0
для i (изображения, метки) в перечислении (train_loader, 0):
# получить входные данные
изображения = переменная (images.to (устройство))
labels = Variable(labels.to(device))
# обнуляем градиенты параметров
оптимизатор. zero_grad()
# прогнозировать классы, используя изображения из обучающего набора
выходы = модель (изображения)
# вычислить потери на основе выходных данных модели и реальных меток
потеря = потеря_fn (выходные данные, метки)
# обратное распространение потери
потеря.назад()
# настроить параметры на основе рассчитанных градиентов
оптимизатор.шаг()
# Распечатаем статистику для каждой 1000 изображений
running_loss += loss.item() # извлечь значение потери
если я % 1000 == 999:
# печатать каждые 1000 (дважды за эпоху)
print('[%d, %5d] потеря: %.3f' %
(эпоха + 1, i + 1, running_loss / 1000))
# обнуление потерь
текущая_потеря = 0,0
# Вычислите и распечатайте среднюю точность для этой эпохи при тестировании всех 10000 тестовых изображений
точность = точность теста ()
print('Для эпохи', эпоха+1,'точность теста по всему набору тестов составляет %d %%' % (точность))
# мы хотим сохранить модель, если точность наилучшая
если точность > best_accuracy:
сохранитьМодель()
best_accuracy = точность
zero_grad()
# прогнозировать классы, используя изображения из обучающего набора
выходы = модель (изображения)
# вычислить потери на основе выходных данных модели и реальных меток
потеря = потеря_fn (выходные данные, метки)
# обратное распространение потери
потеря.назад()
# настроить параметры на основе рассчитанных градиентов
оптимизатор.шаг()
# Распечатаем статистику для каждой 1000 изображений
running_loss += loss.item() # извлечь значение потери
если я % 1000 == 999:
# печатать каждые 1000 (дважды за эпоху)
print('[%d, %5d] потеря: %.3f' %
(эпоха + 1, i + 1, running_loss / 1000))
# обнуление потерь
текущая_потеря = 0,0
# Вычислите и распечатайте среднюю точность для этой эпохи при тестировании всех 10000 тестовых изображений
точность = точность теста ()
print('Для эпохи', эпоха+1,'точность теста по всему набору тестов составляет %d %%' % (точность))
# мы хотим сохранить модель, если точность наилучшая
если точность > best_accuracy:
сохранитьМодель()
best_accuracy = точность
Протестируйте модель на тестовых данных.

Теперь вы можете протестировать модель с пакетом изображений из нашего тестового набора.
- Добавьте следующий код в файл
PyTorchTraining.py.
импортировать matplotlib.pyplot как plt
импортировать numpy как np
# Функция для показа изображений
определение изображения показать (img):
img = img / 2 + 0,5 # не нормализовать
npimg = img.numpy()
plt.imshow (np.transpose (npimg, (1, 2, 0)))
plt.show()
# Функция для тестирования модели с пакетом изображений и отображения прогнозов меток
деф тестПакет():
# получить пакет изображений из тестового DataLoader
изображения, метки = следующий (iter (test_loader))
# показать все изображения как одну сетку изображений
изображения-шоу (torchvision.utils.make_grid (изображения))
# Показать настоящие метки на экране
print('Настоящие метки: ', ' '.join('%5s' % class[labels[j]]
для j в диапазоне (batch_size)))
# Давайте посмотрим, что если модель идентифицирует метки этих примеров
выходы = модель (изображения)
# Получили вероятность для каждых 10 меток. Самая высокая (максимальная) вероятность должна быть правильной меткой
_, предсказано = torch.max (выходы, 1)
# Покажем предсказанные метки на экране для сравнения с реальными
print('Прогноз: ', ' '.join('%5s' % классов[прогноз [j]]
для j в диапазоне (batch_size)))
Самая высокая (максимальная) вероятность должна быть правильной меткой
_, предсказано = torch.max (выходы, 1)
# Покажем предсказанные метки на экране для сравнения с реальными
print('Прогноз: ', ' '.join('%5s' % классов[прогноз [j]]
для j в диапазоне (batch_size)))
Наконец, добавим основной код. Это запустит обучение модели, сохранит модель и отобразит результаты на экране. Мы запустим только две итерации [train(2)] по тренировочному набору, поэтому процесс обучения не займет слишком много времени.
- Добавьте следующий код в файл
PyTorchTraining.py.
если __name__ == "__main__":
# Давайте построим нашу модель
поезд(5)
print('Завершено обучение')
# Проверить, какие классы работают хорошо
точность модели теста ()
# Давайте загрузим только что созданную модель и проверим точность каждой метки
модель = Сеть()
путь = "myFirstModel. pth"
model.load_state_dict (torch.load (путь))
# Тест с пакетом изображений
тестовая партия ()
pth"
model.load_state_dict (torch.load (путь))
# Тест с пакетом изображений
тестовая партия ()
Давайте проведем тест! Убедитесь, что в раскрывающихся меню на верхней панели инструментов установлено значение «Отладка». Измените платформу решений на x64, чтобы запустить проект на локальном компьютере, если ваше устройство 64-разрядное, или на x86, если оно 32-разрядное.
Выбор номера эпохи (количество полных проходов через обучающий набор данных), равного двум ( [train(2)] ), приведет к двукратному повторению всего тестового набора данных из 10 000 изображений. Для завершения обучения на ЦП Intel 8-го поколения потребуется около 20 минут, и модель должна достичь более или менее 65% успеха в классификации десяти меток.
- Чтобы запустить проект, нажмите кнопку «Начать отладку» на панели инструментов или нажмите клавишу F5.
Всплывет окно консоли и можно будет увидеть процесс обучения.
Как вы определили, значение потерь будет распечатываться каждые 1000 пакетов изображений или пять раз для каждой итерации в обучающем наборе. Вы ожидаете, что значение потерь будет уменьшаться с каждым циклом.
Вы ожидаете, что значение потерь будет уменьшаться с каждым циклом.
Вы также увидите точность модели после каждой итерации. Точность модели отличается от значения потерь. Функция потерь дает нам понимание того, насколько хорошо ведет себя модель после каждой итерации оптимизации на обучающем наборе. Точность модели рассчитывается на тестовых данных и показывает процент правильного прогноза. В нашем случае это скажет нам, сколько изображений из тестового набора из 10 000 изображений наша модель смогла правильно классифицировать после каждой итерации обучения.
После завершения обучения вы должны увидеть результат, аналогичный приведенному ниже. Ваши числа не будут точно такими же — трианнинг зависит от многих факторов и не всегда будет возвращать идентичные результаты — но они должны выглядеть одинаково.
После запуска всего 5 эпох вероятность успеха модели составляет 70%. Это хороший результат для базовой модели, обученной за короткий период времени!
Тестирование с пакетом изображений: модель правильно воспроизвела 7 изображений из пакета из 10. Совсем неплохо и соответствует показателю успешности модели.
Совсем неплохо и соответствует показателю успешности модели.
Вы можете проверить, какие классы наша модель может предсказать лучше всего. Просто добавьте код ниже:
- Дополнительно — добавьте следующую функцию
testClassessв файлPyTorchTraining.py, добавьте вызов этой функции —testClassess()внутри основной функции —__name__ == "__main__".
# Функция для проверки того, какие классы работают хорошо
определение тестовых классов():
class_correct = list(0. для i в диапазоне(number_of_labels))
class_total = list(0. для i в диапазоне(number_of_labels))
с факелом.no_grad():
для данных в test_loader:
изображения, метки = данные
выходы = модель (изображения)
_, предсказано = torch.max (выходы, 1)
c = (прогнозируемые == метки).squeeze()
для i в диапазоне (batch_size):
метка = метки[i]
class_correct[метка] += c[i]. Imgs ml: NEW YORK | WOMEN | IMG Models
Imgs ml: NEW YORK | WOMEN | IMG Models