ChatGPT — это размытый JPEG Интернета — Будущее на vc.ru
Когда я увидел заголовок “ChatGPT is a blurry JPEG of the Web”, я подумал, что это какое-то небрежное замечание. Но нет, это замечательное эссе исследует чат-ботов через призму алгоритмов сжатия изображений с потерями, и в нем есть здравый смысл. Его автор Ted Chiang четырежды лауреат премий «Небьюла», «Хьюго» и «Локус». Он также написал короткий рассказ по которому сняли фильм «Прибытие».
1286 просмотров
В 2013 году рабочие немецкой строительной компании заметили нечто странное в своем копировальном аппарате Xerox: когда они делали копию плана дома, она незначительно, но в тоже время существенно отличалась от оригинала. На первоначальном плане этажа каждая из трех комнат дома сопровождалась прямоугольником, указывающим ее площадь: комнаты были 14, 13, 21, 11 и 17, 42 квадратных метра соответственно. Однако на фотокопии все три комнаты были обозначены площадью 14, 13 квадратных метров.
Компания связалась с ученым-компьютерщиком Дэвидом Криселом, чтобы исследовать этот, казалось бы, невероятный результат.
Сжатие файла требует двух шагов: во-первых, кодирование, во время которого файл преобразуется в более компактный формат, а затем декодирование, при котором происходит обратный процесс. Если восстановленный файл идентичен оригиналу, то процесс сжатия описывается как без потерь: никакая информация не была удалена. Напротив, если восстановленный файл является лишь приближением к оригиналу, сжатие описывается как сжатие с потерями: некоторая информация была отброшена и теперь не может быть восстановлена. Сжатие без потерь — это то, что обычно используется для текстовых файлов и компьютерных программ, потому что это области, в которых даже один неверный символ может иметь катастрофические последствия.
Сжатие с потерями часто используется для фотографий, аудио и видео в ситуациях, когда абсолютная точность не важна. Большую часть времени мы не замечаем, если картинка, песня, или фильм не воспроизводится идеально. Потеря точности становится более заметной только при очень сильном сжатии файлов. В таких случаях мы замечаем так называемые «следы» сжатия: нечеткость мельчайших изображения jpeg и mpeg или металлический звук MP3 с низким битрейтом.
Фотокопировальные устройства Xerox используют формат сжатия с потерями, известный как jbig2, предназначенный для использования с черно-белыми изображениями. Для экономии места копировальный аппарат идентифицирует на изображении похожие области и сохраняет одну копию для всех из них; когда файл распаковывается, он повторно использует эту копию для восстановления изображения. Выяснилось, что фотокопировальный аппарат счел метки, определяющие площадь комнат, достаточно похожими, поэтому ему нужно было сохранить только одну из них — 14, 13 — и повторно использовал ее для всех трех комнат при печати плана этажа.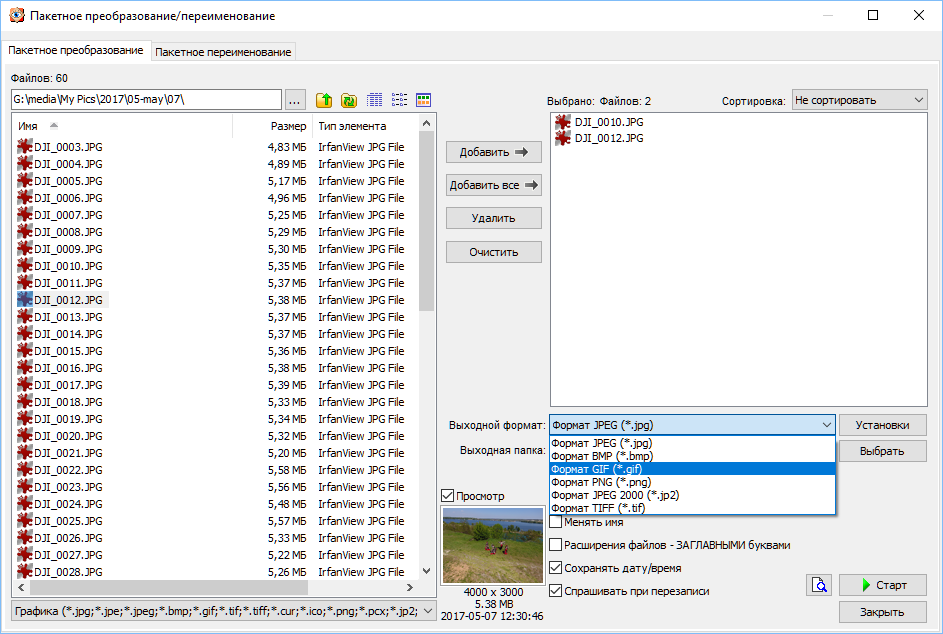
Я думаю, что этот инцидент с копировальным аппаратом Xerox стоит помнить сегодня, когда мы рассматриваем OpenAI ChatGPT и другие подобные программы, которые исследователи ИИ называют большими языковыми моделями. Сходство между копировальным аппаратом и большой языковой моделью может быть не сразу очевидным, но рассмотрим следующий сценарий./JPEG-vs-TIFF-vs-RAW-fb85f34808b8471fb24a1e197c9d7ac3.jpg)
Представьте, что вы вот-вот потеряете доступ к Интернету навсегда. При подготовке вы планируете создать сжатую копию всего текста в Интернете, чтобы хранить ее на частном сервере. К сожалению, на вашем частном сервере есть только один процент необходимого места; вы не можете использовать алгоритм сжатия без потерь, если хотите, чтобы все поместилось. Вместо этого вы пишете алгоритм с потерями, который выявляет статистические закономерности в тексте и сохраняет их в специализированном формате файла. Поскольку у вас есть практически неограниченная вычислительная мощность для решения этой задачи, ваш алгоритм может идентифицировать необычайно тонкие статистические закономерности.
Теперь потеря доступа к Интернету не так уж и ужасна; у вас есть вся информация в Интернете, хранящаяся на вашем сервере. Единственная загвоздка в том, что, поскольку текст был настолько сильно сжат, вы не можете искать информацию, ища точную цитату; вы никогда не получите точного совпадения, потому что хранятся не слова. Чтобы решить эту проблему, вы создаете интерфейс, который принимает запросы в форме вопросов и отвечает ответами, которые передают суть того, что у вас есть на вашем сервере.
Чтобы решить эту проблему, вы создаете интерфейс, который принимает запросы в форме вопросов и отвечает ответами, которые передают суть того, что у вас есть на вашем сервере.
То, что я описал, очень похоже на ChatGPT или любую другую большую языковую модель. Думайте о ChatGPT как о размытом jpeg -файле всего текста в Интернете. Он сохраняет большую часть информации из Интернета точно так же, как jpeg сохраняет большую часть информации изображения с более высоким разрешением, но если вы ищете точную последовательность битов, вы ее не найдете; все, что вы когда-либо получите, это приближенный вариант. Но, поскольку приближенный вариант представлено в виде грамматического текста, который ChatGPT создает превосходно, обычно это приемлемо. Вы по-прежнему смотрите на размытый jpeg, но размытость возникает таким образом, что изображение в целом не выглядит менее четким.
Эта аналогия со сжатием с потерями — не просто способ понять способность ChatGPT переупаковывать информацию, найденную в Интернете, с использованием других слов. Это также способ понять «галлюцинации» или бессмысленные ответы на фактические вопросы, которым слишком подвержены большие языковые модели, такие как ChatGPT. Эти галлюцинации являются следами сжатия, но, как и неправильные метки, сгенерированные фотокопировальным аппаратом Xerox, они достаточно правдоподобны, чтобы их идентифицировать, нужно сравнивать их с оригиналами, что в данном случае означает либо Интернет, либо наши собственные знания о мире.
Это также способ понять «галлюцинации» или бессмысленные ответы на фактические вопросы, которым слишком подвержены большие языковые модели, такие как ChatGPT. Эти галлюцинации являются следами сжатия, но, как и неправильные метки, сгенерированные фотокопировальным аппаратом Xerox, они достаточно правдоподобны, чтобы их идентифицировать, нужно сравнивать их с оригиналами, что в данном случае означает либо Интернет, либо наши собственные знания о мире.
Когда мы думаем о них таким образом, такие галлюцинации совсем не удивительны; если алгоритм сжатия предназначен для восстановления текста после того, как было отброшено девяносто девять процентов оригинала. Эта аналогия становится еще более понятной, если мы вспомним, что распространенным методом, используемым алгоритмами сжатия с потерями, является интерполяция, то есть оценка того, чего не хватает, глядя на то, что находится по обе стороны от разрыва. Когда программа обработки изображений отображает фотографию и должна восстановить пиксель, потерянный в процессе сжатия, она просматривает соседние пиксели и вычисляет среднее значение.
Учитывая, что большие языковые модели, такие как ChatGPT, часто превозносятся как передовые технологии искусственного интеллекта, описание их как алгоритмов сжатия текста с потерями может показаться пренебрежительным или, по крайней мере, обесценивающим. Я действительно думаю, что эта точка зрения предлагает полезную корректировку тенденции антропоморфизировать большие языковые модели, но есть еще один аспект аналогии со сжатием, который стоит рассмотреть. С 2006 года исследователь ИИ по имени Маркус Хаттер предлагает денежное вознаграждение, известное как «Премия за сжатие человеческих знаний» или «Премия Хаттера», всем, кто сможет без потерь сжать конкретный гигабайтный снимок Википедии, меньше, чем у предыдущего призера.
Чтобы понять предлагаемую связь между сжатием и пониманием, представьте, что у вас есть текстовый файл, содержащий миллион примеров сложения, вычитания, умножения и деления. Хотя любой алгоритм сжатия может уменьшить размер этого файла, способ достижения наибольшей степени сжатия, вероятно, состоит в том, чтобы вывести принципы арифметики, а затем написать код для программы-калькулятора. С помощью калькулятора вы могли бы идеально реконструировать не только миллион примеров в файле, но и любой другой пример арифметики, с которым вы можете столкнуться в будущем.
Большие языковые модели выявляют статистические закономерности в тексте. Любой анализ текста в Интернете покажет, что фразы типа «предложение низкое» часто появляются в непосредственной близости от фраз типа «цены растут». Чат-бот, учитывающий эту корреляцию, может на вопрос о влиянии нехватки предложения ответить о росте цен. Если большая языковая модель собрала огромное количество корреляций между экономическими терминами — так много, что может предложить правдоподобные ответы на самые разные вопросы, — должны ли мы сказать, что она действительно понимает экономическую теорию? Такие модели, как ChatGPT, не могут претендовать на премию Хаттера по целому ряду причин, одна из которых заключается в том, что они не реконструируют исходный текст точно, т.
Вернемся к примеру с арифметикой. Если вы попросите GPT-3 (модель большого языка, на основе которой был построен ChatGPT) добавить или вычесть пару чисел, он почти всегда даст правильный ответ, если числа состоят только из двух цифр. Но его точность значительно ухудшается с большими числами, падая до десяти процентов, когда числа состоят из пяти цифр. Большинство правильных ответов, которые дает GPT-3, не встречаются в сети — не так много веб-страниц, содержащих, например, текст «245 + 821», — поэтому простым заучиванием он не занимается. Но, несмотря на поглощение огромного количества информации, он также не смог вывести принципы арифметики.
Статистический анализ GPT-3 примеров арифметики позволяет ему произвести поверхностное приближение к реальному значению, но не более того.
Учитывая неудачу GPT-3 в изучении предмета, преподаваемого в начальной школе, как мы можем объяснить тот факт, что иногда он показывает хорошие результаты при написании эссе на уровне колледжа? Несмотря на то, что большие языковые модели часто вызывают «галлюцинации», в осознанном состоянии они звучат так, как будто действительно понимают такие предметы, как экономическая теория. Возможно, арифметика — это особый случай, для которого большие языковые модели плохо подходят. Возможно ли, что статистические закономерности в тексте, помимо сложения и вычитания, действительно соответствуют подлинным знаниям о реальном мире?
Возможно, арифметика — это особый случай, для которого большие языковые модели плохо подходят. Возможно ли, что статистические закономерности в тексте, помимо сложения и вычитания, действительно соответствуют подлинным знаниям о реальном мире?
Я думаю, есть более простое объяснение. Представьте, как бы это выглядело, если бы ChatGPT был алгоритмом без потерь. Если бы это было так, он всегда отвечал бы на вопросы, предоставляя дословную цитату с соответствующей веб-страницы. Мы, вероятно, расценим это программное обеспечение лишь как незначительное улучшение по сравнению с обычной поисковой системой и будем менее впечатлены им. Тот факт, что ChatGPT перефразирует материал из Интернета, а не цитирует его дословно, создает впечатление, что студентка выражает идеи своими словами, а не просто повторяет прочитанное; это создает иллюзию того, что ChatGPT понимает материал. У студентов механическое запоминание не является индикатором подлинного обучения, поэтому неспособность ChatGPT воспроизводить точные цитаты из веб-страниц как раз и заставляет нас думать, что он чему-то научился. Когда мы имеем дело с последовательностями слов, сжатие с потерями выглядит умнее, чем сжатие без потерь.
Когда мы имеем дело с последовательностями слов, сжатие с потерями выглядит умнее, чем сжатие без потерь.
Было предложено множество вариантов использования больших языковых моделей. Думая о них как о размытых изображениях в формате JPEG, можно оценить, для чего они могут или не могут хорошо подходить. Рассмотрим несколько сценариев.
Могут ли большие языковые модели заменить традиционные поисковые системы? Чтобы нам доверять им, нам нужно знать, что их не кормят пропагандой и теориями заговора — нам нужно знать, что jpeg захватывает нужные разделы Интернета. Но даже если большая языковая модель включает в себя только ту информацию, которая нам нужна, остается проблема размытости. Существует тип размытости, который является приемлемым, а именно повторное изложение информации другими словами. Кроме того, есть размытость прямой выдумки, которую мы считаем неприемлемой, когда ищем факты. Пока не ясно, возможно ли технически сохранить приемлемый вид размытия, убрав неприемлемый, но я ожидаю, что мы это узнаем в ближайшем будущем.
Даже если можно запретить использование больших языковых моделей в производстве, должны ли мы использовать их для создания веб-контента? Это имело бы смысл только в том случае, если бы наша цель состояла в том, чтобы переупаковать информацию, которая уже доступна в Интернете. Некоторые компании существуют именно для этого — мы обычно называем их «фабриками контента».
Возможно, им пригодится размытость больших языковых моделей, как способ избежать нарушения авторских прав. Однако в целом я бы сказал, что все, что хорошо для производителей контента, плохо для людей, которые ищут информацию. Распространение этого типа переупаковки затрудняет нам поиск того, что мы ищем в Интернете прямо сейчас; чем больше в сети публикуется текст, сгенерированный большими языковыми моделями, тем более размытой становится еть.Существует очень мало информации о предстоящем преемнике OpenAI для ChatGPT, GPT-4. Но я собираюсь сделать прогноз: при сборке огромного количества текста, используемого для обучения GPT-4, люди из OpenAI приложили все усилия, чтобы исключить материал, сгенерированный ChatGPT или любой другой большой языковой моделью. Если это окажется так, то это послужит непреднамеренным подтверждением того, что аналогия между большими языковыми моделями и сжатием с потерями полезна.
Если это окажется так, то это послужит непреднамеренным подтверждением того, что аналогия между большими языковыми моделями и сжатием с потерями полезна.
Многократное повторное сохранение файла jpeg создает больше артефактов сжатия, поскольку каждый раз теряется больше информации. Это цифровой эквивалент многократного изготовления фотокопий фотокопий в старые времена. Качество изображения становится только хуже.
Действительно, полезным критерием для оценки качества большой языковой модели может быть готовность компании использовать созданный ею текст в качестве учебного материала для новой модели. Если выходные данные ChatGPT недостаточно хороши для GPT-4, мы можем принять это как показатель того, что они недостаточно хороши и для нас. И наоборот, если модель начинает генерировать текст настолько хорошо, что его можно использовать для обучения новых моделей, то это должно вселить в нас уверенность в качестве этого текста. (Я подозреваю, что такой результат потребует серьезного прорыва в методах, используемых для построения этих моделей. ) Если и когда мы начнем видеть, что модели производят результат, который так же хорош, как и их вход, тогда аналогия со сжатием с потерями больше не будет применима.
) Если и когда мы начнем видеть, что модели производят результат, который так же хорош, как и их вход, тогда аналогия со сжатием с потерями больше не будет применима.
Могут ли большие языковые модели помочь людям в создании оригинального письма? Чтобы ответить на этот вопрос, нам нужно уточнить, что мы подразумеваем под этим вопросом. Существует жанр искусства, известный как ксероксное искусство или фотокопирование, в котором художники используют отличительные свойства копировальных аппаратов в качестве творческих инструментов. Что-то в этом роде, безусловно, возможно с фотокопировальным устройством, которым является ChatGPT, так что в этом смысле ответ — да. Но я не думаю, что кто-то станет утверждать, что копировальные аппараты стали важным инструментом в создании искусства; подавляющее большинство художников не используют их в своем творческом процессе, и никто не спорит, что этим выбором они ставят себя в невыгодное положение.
Итак, давайте предположим, что мы не говорим о новом жанре письма, аналогичном искусству Xerox. Учитывая это условие, может ли текст, сгенерированный большими языковыми моделями, быть полезной отправной точкой для писателей, на которую они могут опираться при написании чего-то оригинального, будь то художественная или научная литература? Позволит ли большая языковая модель обрабатывать шаблоны, позволит ли писателям сосредоточить свое внимание на действительно творческих частях?
Учитывая это условие, может ли текст, сгенерированный большими языковыми моделями, быть полезной отправной точкой для писателей, на которую они могут опираться при написании чего-то оригинального, будь то художественная или научная литература? Позволит ли большая языковая модель обрабатывать шаблоны, позволит ли писателям сосредоточить свое внимание на действительно творческих частях?
Очевидно, что никто не может говорить за всех писателей, но позвольте мне привести аргумент, что начинать с размытой копии неоригинальной работы — не лучший способ создать оригинальную работу. Если вы писатель, вы напишете много неоригинальной работы, прежде чем напишете что-то оригинальное. И время и усилия, затраченные на эту неоригинальную работу, не потрачены впустую; напротив, я бы предположил, что именно это позволяет вам со временем создать что-то оригинальное. Часы, потраченные на выбор правильного слова и перестановку предложений, чтобы лучше следовать одно за другим, учат вас тому, как смысл передается прозой. Написание сочинений студентами — это не просто способ проверить, насколько они усвоили материал; это дает им опыт в формулировании своих мыслей. Если учащимся никогда не придется писать сочинения, которые мы все читали раньше, они никогда не приобретут навыков, необходимых для написания того, чего мы никогда не читали.
Написание сочинений студентами — это не просто способ проверить, насколько они усвоили материал; это дает им опыт в формулировании своих мыслей. Если учащимся никогда не придется писать сочинения, которые мы все читали раньше, они никогда не приобретут навыков, необходимых для написания того, чего мы никогда не читали.
И дело не в том, что, раз уж вы перестали быть студентом, вы можете смело пользоваться тем шаблоном, который предоставляет большая языковая модель. Борьба за выражение своих мыслей не исчезнет после окончания учебы — она может возникать каждый раз, когда вы начинаете набрасывать новую работу. Иногда только в процессе написания вы обнаруживаете свои оригинальные идеи. Кто-то может сказать, что вывод больших языковых моделей не сильно отличается от первого наброска, написанного писателем-человеком, но, опять же, я думаю, что это поверхностное сходство. Ваш первый набросок — это не неоригинальная идея, выраженная ясно; это исходная идея, плохо выраженная, и она сопровождается вашей аморфной неудовлетворенностью, вашим осознанием дистанции между тем, что она говорит, и тем, что вы хотите, чтобы она сказала. Это то, что направляет вас во время переписывания, и это одна из вещей, которой не хватает, когда вы начинаете с текста, сгенерированного ИИ.
Это то, что направляет вас во время переписывания, и это одна из вещей, которой не хватает, когда вы начинаете с текста, сгенерированного ИИ.
В письме нет ничего волшебного или мистического, но оно включает в себя нечто большее, чем размещение существующего документа на ненадежном фотокопировальном аппарате и нажатие кнопки «Печать». Возможно, в будущем мы создадим ИИ. который способен писать хорошую прозу, основанную только на собственном опыте восприятия мира. День, когда мы этого добьемся, будет поистине знаменательным, но этот день лежит далеко за горизонтом нашего предсказания. Между тем разумно спросить: какой смысл иметь что-то, что перефразирует сеть? Если бы мы теряли доступ к Интернету навсегда и должны были бы хранить копию на частном сервере с ограниченным пространством, модель большого языка, такая как ChatGPT, могла бы быть хорошим решением, при условии, что ее можно было бы уберечь от создания. Но мы не теряем доступ к Интернету. Так насколько же полезен размытый JPEG, если у вас все еще есть оригинал?
Перевод статьи Ted Chiang «ChatGPT Is a Blurry JPEG of the Web»
Как работает JPEG-сжатие? Разбор | Droider.
 ru
ruСегодня для нас нет ничего необычного в том, чтобы отправить фотку другу и не волноваться по поводу того, какое устройство, браузер или операционную систему он использует. Все это благодаря формату JPEG, который может уменьшить размер исходного файла в 10, 50 и даже в 100 раз. Изображения формата JPEG встречаются повсюду в нашей жизни в интернете, но за простотой и удобством использования скрываются алгоритмы, устраняющие детали, не воспринимаемые человеческим глазом. В итоге получается высочайшее визуальное качество при наименьшем размере файла.
Вы когда-нибудь задумывались, сколько места фотки на наших устройствах?
Давате посмотрим на этот снимок:
Его разрешение 12.2 мегапикселя или 4032 × 3024 точек. Сколько он должна бы весить? Давайте посчитаем. Как известно, цвет каждого пикселя определяется тремя составляющими: красным, зелёным и синим. Каждая составляющая кодируется восьмибитным числом. Получим, что такое изображение будет весить 8х3х4032×3024 = 292 626 432 бит, то есть почти 300 мб!!!
Как известно, цвет каждого пикселя определяется тремя составляющими: красным, зелёным и синим. Каждая составляющая кодируется восьмибитным числом. Получим, что такое изображение будет весить 8х3х4032×3024 = 292 626 432 бит, то есть почти 300 мб!!!
В реальности же она весит 7.36 мб. То есть в 40 раз МЕНЬШЕ! А если пожать через Whatsapp, будут какие-то 200 килобайт. Все благодаря формату JPEG, с которым мы сталкиваемся постоянно.
Конечно, присутствует небольшая потеря качества, но по сравнению с тем, что размер файла был уменьшен в несколько десятков раз, это уже не играет большой роли. И новые форматы отвоевывают рынок — тот же hevc. JPEG все еще остается королем индустрии. Так что давайте разберемся, как конкретно всё это работает? Причем здесь психология зрения, и как хитрая математика экономит место.
К началу 80-х годов прошлого столетия компьютеры умели хранить и показывать цифровые изображения, однако для воплощения этого существовало множество различных решений. Например, нельзя было просто отправить изображение с одного компьютера на другой. Для решения этой проблемы в 1986 году был собран комитет экспертов со всего мира под названием «Объединённая группа экспертов по фотографии» (Joint Photographic Experts Group, JPEG). Эта группа людей и создала стандарт сжатия цифровых изображений JPEG в 1992 году, который спасает нас до сих пор.
Для решения этой проблемы в 1986 году был собран комитет экспертов со всего мира под названием «Объединённая группа экспертов по фотографии» (Joint Photographic Experts Group, JPEG). Эта группа людей и создала стандарт сжатия цифровых изображений JPEG в 1992 году, который спасает нас до сих пор.
Прежде всего давайте разберёмся, почему вообще возможно сжать изображение так, чтобы наши глаза при этом не замечали изменений, вносимых форматом в фотографию. JPEG удаляет информацию, которую человеческий глаз плохо воспринимает.
Теперь стоит поговорить о том, как устроено наше зрение. Как известно, в глазу есть два типа восприимчивых к свету клеток: палочки и колбочки (rods and cones). Палочки плохо восприимчивы к свету, но играют решающую роль для зрения в условиях низкой освещенности, в то время как колбочки имеют цветовые рецепторы. Именно они обеспечивают нашим глазам цветное зрение. В каждом глазу имеется около 100 миллионов палочек и всего лишь 6 миллионов колбочек.
Как следствие, глаз гораздо более восприимчив к изменениям в яркости изображения и менее восприимчив к изменению в цвете. Поэтому при сжатии картинки можно использовать такую хитрость: во первых, отделить цвет от яркости, во вторых, убрать немного цвета, и в таком случае никто ничего не заметит. Именно на данной хитрости и основывается первый и очень важный этап сжатия, называемый цветовой субдискредитацией.
Поэтому при сжатии картинки можно использовать такую хитрость: во первых, отделить цвет от яркости, во вторых, убрать немного цвета, и в таком случае никто ничего не заметит. Именно на данной хитрости и основывается первый и очень важный этап сжатия, называемый цветовой субдискредитацией.
Но как именно нам отделить яркость от цвета? Как известно, каждый пиксель характеризуется тремя компонентами: R,G,B — по одной переменной для каждого цвета, которые могут принимать значения в диапазоне от 0 до 255.
Хитрость в том, что эту же информацию мы можем сохранить, используя другие три переменные: Y, Cb, Cr. Тогда мы без проблем можем преобразовать изображение с пикселями формата RGB в новый формат с другими компонентами Y,Cb,Cr. Здесь Y отвечает за яркость, а Cb и Cr- цветовые каналы. Таким образом, вычислив эти переменные, мы получаем три новых изображения, составленных из этих трех компонент. Вычисление происходит по таким мудреным формулам, если интересно.
Такое разделение необходимо, чтобы дальше мы могли убрать часть деталей из цветовых каналов (составленных из Сb и Cr). Пока что никакие данные мы не удаляли, а математические преобразования из одного формата в другой являются обратимыми. Данные действия, конечно же, проделываются над всеми пикселями изображения.
Пока что никакие данные мы не удаляли, а математические преобразования из одного формата в другой являются обратимыми. Данные действия, конечно же, проделываются над всеми пикселями изображения.
Теперь мы и будем использовать особенность нашего зрения: воспринимать изменения в цвете хуже, чем изменения в яркости. Ранее мы получили из исходной картинки 2 цветовых переменных и одну яркостную.
Теперь делается еще один ход: каждые 4 пикселя в обоих цветовых изображениях объединяются в 1, тем самым удаляется повторяющаяся информация. В результате, детали, плохо воспринимаемые нашими глазами, т.е. обе цветовые составляющие (Cr и Сb), уменьшаются до ¼ своего исходного размера, а яркостная составляющая остаётся прежней. Таким образом, всего за два шага изображение становится в 2 раза меньше исходного размера
Было: 1+1+1=3
Стало: ¼+¼+1=1,5
При этом если сейчас собрать эти 3 составляющие в одно исходное изображение, то невооруженным глазом разницу между оригиналом и сжатым изображением заметить будет невозможно.
Теперь выполняется подготовка к самому важному, сложному и умному этапу. Для этого каждая из 3 наших картинок, составленных из яркостного и двух цветовых каналов, разбивается на блоки пикселей 8×8. Теперь алгоритмы сжатия должны каким-то образом понять, насколько много деталей в каждом из таких блоков. Если деталей мало, то можно закодировать меньшим количеством бит, уменьшая размер файла, а если деталей много, то наоборот.
Иными словами, если бы картины в музеях хранились в джипеге, то любая картина Ван Гога занимала бы меньше места, чем черный квадрат Малевича.
Такой анализ и производится с помощью штуки со страшным названием — дискретное косинусное преобразование. Прежде, чем переходить к нему, рассмотрим такой простой пример. У нас есть разноцветные полупрозрачные стеклышки. Накладывая их друг на друга, мы можем получить тот цвет, который нам нужен, т.е., например,чтобы получить фиолетовый цвет, нужно наложить синее стеклышко на красное. Такая же ситуация и в случае с алгоритмом.
Рассмотрим один из блоков 8х8. Все последующие действия будут выполняться для каждого из таких блоков. Такой блок содержит 64 пикселя. Оказывается, что любое простое монохромное изображение можно представить в виде комбинации вот таких 64 базовых картинок.
То есть, накладывая их друг на друга с разной степенью прозрачности, можно получить любую простую картинку 8х8 примерно так же, как и в примере со стеклышками.
Именно таким образом мы и можем перестроить любой наш блок 8х8 путём наложения этих базовых картинок друг на друга. При этом каждый из узоров умножается на число, являющееся показателем того, какая его часть используется при построении определенной картинки.
Суть алгоритма дискретного косинусного преобразования и заключается в вычислении данных чисел. На выходе получаем матрицу 8х8, состоящую из чисел, отображающих, насколько большой или не очень вклад каждого узора в данное изображение 8х8. Выглядит это примерно так. Прикольно, да?
Чем больше число, тем больший вклад базового изображения (узора), соответствующего данному числу. Коэффициенты, находящиеся в левой верхней части матрицы отвечают за плавные переходы и более общие черты, а коэффициенты, лежащие в правой нижней части- за частые переходы, т.е. за тонкие детали. Если деталей в данном блоке оказывается мало, то коэффициенты, отвечающие за них (находящиеся в правой нижней части матрицы) будут равны нулям или близким к нулю значениям. (Именно на данном этапе отбрасывается огромная часть информации, не видимой человеческим глазом.) Это важный момент запомним.
Коэффициенты, находящиеся в левой верхней части матрицы отвечают за плавные переходы и более общие черты, а коэффициенты, лежащие в правой нижней части- за частые переходы, т.е. за тонкие детали. Если деталей в данном блоке оказывается мало, то коэффициенты, отвечающие за них (находящиеся в правой нижней части матрицы) будут равны нулям или близким к нулю значениям. (Именно на данном этапе отбрасывается огромная часть информации, не видимой человеческим глазом.) Это важный момент запомним.
Это немного напоминает составление фоторобота: нос номер 9, рот номер 13, глаза среднее между нумером 6 и 42.
Прежде, чем идти дальше, подведем промежуточные итоги. Что мы имеем на данный момент?
У нас есть матрица из 64 чисел, содержащих информацию о том, как именно нужно использовать базовые изображения. Если не считать этап цветовой субдискредитации, то пока что мы не отбрасывали существенное количество информации, а только определяли, что нужно отбросить.
Как это делается?
Для этого этапа используется вот такая таблица. Называется таблица квантования. К квантовым компьютерам не имеет отношения. Не пугайтесь, какждется это послдений сложный термин на сегодня. Если по простому: она определяет какую часть из полученной прежде информации мы возьмем в итоговый файл. Смотрите: это матрица 8х8, содержащая коэффициенты, на которые мы делим числа из нашей исходной матрицы. Степень сжатия задаётся характеристиками таблицы квантования, т.е. чем больше коэффициенты в этой таблице, тем меньше будут числа в новой матрице. В зависимости от характеристик таблицы квантования мы можем уменьшить размер изображения до 95% от первоначального размера, но в таком случае, конечно, качество сжатого изображения будет далеко не самым высоким. Именно эта таблица и является основной настройкой jpeg, регулирующей степень сжатия.
Называется таблица квантования. К квантовым компьютерам не имеет отношения. Не пугайтесь, какждется это послдений сложный термин на сегодня. Если по простому: она определяет какую часть из полученной прежде информации мы возьмем в итоговый файл. Смотрите: это матрица 8х8, содержащая коэффициенты, на которые мы делим числа из нашей исходной матрицы. Степень сжатия задаётся характеристиками таблицы квантования, т.е. чем больше коэффициенты в этой таблице, тем меньше будут числа в новой матрице. В зависимости от характеристик таблицы квантования мы можем уменьшить размер изображения до 95% от первоначального размера, но в таком случае, конечно, качество сжатого изображения будет далеко не самым высоким. Именно эта таблица и является основной настройкой jpeg, регулирующей степень сжатия.
Теперь переходим к квантованию, т.е. этапу, на котором будет производиться наибольшее сжатие. Здесь происходит сначала деление чисел из матрицы, которую мы получили на прошлом этапе, на определенные коэффициенты, соответствующие таблице квантования, а затем происходит округление полученных чисел до ближайшего целого (например: делим 560/4=140; -41/3=-13,7- округляем до целого, получаем -14 и т. д.). Но что ещё за таблица квантования и откуда она берется?
д.). Но что ещё за таблица квантования и откуда она берется?
- Исходная матрица
- Таблица квантования
- Новая матрица
Если посмотреть на таблицу квантования, то можно увидеть, что самые большие числа расположены в правой нижней части таблицы. Это значит, что большего всего отбрасываются высокочастотные данные, т.е. отвечающие за те детали, которые наши глаза хуже всего воспринимают.
В результате этого процесса получается, что большая часть чисел нашей исходной матрицы стала равной нулю, так как числа, близкие к правому нижнему углу матрицы были слишком малы и после деления и округления обнулились. Остаются только числа, близкие к левому верхнему углу матрицы. На этом этапе и происходит самое существенное сжатие изображения, т.е. практически все данные, к которым наши глаза плохо восприимчивы, отбрасываются.
Далее используется зигзагообразное сканирование матрицы чисел, в результате чего получается числовая строка, в начале которой ненулевые значения, а в конце — нулевые.
Затем вместо того, чтобы перечислять все числа строки по порядку, мы используем алгоритм кодирования длин серий, благодаря которому можно не перечислять все нули, а просто назвать их количество.
Далее уже сжатая последовательность кодируется с помощью алгоритма Хаффмана. Это достаточно сложный процесс, но если говорить кратко, то нули кодируются меньшим количеством бит, а ненулевые элементы последовательности кодируются большим количеством бит.
Процесс сжатия завершён. Мы получили сжатое изображение в виде последовательности чисел.
Как же теперь вывести его на экран? Для этого необходимы все те же самые действия, но уже проделанные в обратном порядке: 1. Декодирование с помощью алгоритма Хаффмана, 2. Декодирование по методу длин серий, 3. Заполнение матрицы 8х8 коэффициентами зигзагообразным методом для каждого из блоков 8х8, 4. Умножение каждого числа матрицы на соответствующий коэффициент согласно таблице квантования, 5. Масштабирование компоненты цветов, 6. Преобразование полученных значений Y, Cb и Cr для каждого пикселя в RGB и 7. Вывод изображения уже в формате JPEG на экран. Готово!
Преобразование полученных значений Y, Cb и Cr для каждого пикселя в RGB и 7. Вывод изображения уже в формате JPEG на экран. Готово!
Подведём итоги. Как видите, при работе JPEG используется огромное количество нюансов: особенности строения глаза, математические методы сжатия, разложение в спектр.
Конечно, у JPEG есть достаточно большое количество недостатков: невозможность качественного сжатия текстовых изображений, ухудшение качества при повторном сохранении, но несмотря на все его многочисленные недостатки и почтенный возраст, он по сей день остаётся самым популярным форматом изображений в интернете, хотя сейчас ему на смену начали приходить другие, гораздо более продвинутые форматы, такие как HEIC, AV1, WebP и другие. Причины популярности JPEG в настоящее время, конечно, есть: он очень хорошо изучен за 30 лет существования, является бесплатным, а также всем понятен и привычен.
Post Views: 3 625
форматов/jpeg.md на мастере · корками/форматах · GitHub
JPEG (Joint Photographic Experts Group) — это кодировка изображения,
JFIF (формат обмена файлами JPEG) — это формат хранения файлов.
Официальные спецификации
- Формат обмена файлами JPEG v1.02, 1 сентября 1992 г.
- МСЭ Т.81 | ISO IEC 10918-1: Информационные технологии. Цифровое сжатие и кодирование неподвижных изображений с непрерывной тональностью. Требования и рекомендации
источников:
- libjpeg: список: jdmarker.c#L21, обработка: jdmarker.c#L1113
- libjpeg-турбо
- Ральф Джайлз jpegdump.c
- OpenJPEG j2k.h
- Инструменты Exif Теги JPEG
- JPEG-кодировщик-python, NanoJPEG, microJPEG
Инструмент и источник:
- JPEGsnoop, JfifDecode.h
Это могла бы быть очень простая структура, если бы не было исключений.
Файл JPEG представляет собой последовательность фрагментов Type-Length-Value, называемых сегментов :
\хFF; маркер:с; длина(значение+2):>u2; значение;длина*c;
- тип определяется маркером : 2 байта,
FF, затем ненулевым байтом (*).
- длина имеет прямой порядок байтов на 2 байта и покрывает сам размер. Таким образом, длина всего сегмента равна
2 + длина(чтобы покрыть длину маркера ). Это также означает, что любой сегмент имеет длину не более 65537 байт.
(*) это правило ненулевого байта важно: если любая кодировка данных выводит FF байта, то после него должен быть закодирован литерал 00 , чтобы выразить, что это FF байта данных, а не маркер сегмента.
Исключения
В этой структуре TLV есть 2 исключения:
Общая структура JPEG : Скан тоже сегмент, но ECS возможен только сразу после сканирования.
маркеры без параметров
Некоторые типы маркеров не имеют параметров: без длины, без значения, просто маркер:
- магическая подпись , по смещению
0, называемая Начало изображения (SOI):FFD8 - терминатор , в конце файла, называемый End of Image (EOI):
FFD9 - маркеры перезапуска,
FFD0—D7, которые являются просто необязательными индикаторами в середине данныхECS.
Энтропийно-кодированный сегмент
Начало сканирования — правильно определенный TLV-сегмент. Сразу после этого начинается сегмент с энтропийным кодированием , который не следует никакому аналогичному соглашению, несмотря на то же имя сегмента .
Вероятно, это позволит ECS увеличиться до любого размера, превышающего обычное ограничение в 65537 байт: они представляют большую часть данных файла — справедливо считать, что формат JFIF вводит в заблуждение: хорошо структурированные фрагменты с неясным огромным ECS blob в середине.
Его длина заранее неизвестна и не определена в файле.
Единственный способ получить его длину — это либо декодировать его, либо перемотать вперед:
просто просканируйте вперед FF байта. Если это маркер перезапуска (за которым следует D0 — D7 ) или данные FF (за которым следует 00 ), продолжайте.
файлов начинаются
Большинство файлов JPEG начинаются с FF D8 FF E0 00 10 .J .F .I .F 00 , что приводит к следующим неверным предположениям:
- подпись , а не
FF D8 FF E0по смещению0илиJFIFпо смещению6.
Читается как:
- a Маркер начала изображения ,
FF D8. Этот является подписью, установленной по смещению0. - сегмент a: с маркером
Application 0(закодированоFF E0) и длиной 16 (закодировано00 10) - его данные:
- и
JFIF\0подпись. - , затем остальная часть APP0 куска, здесь мало интересного..
Но многие файлы JPEG не имеют сегмента FF E0 со смещением 3, например, с информацией EXIF и начинаются так:
-
FF D8FF E1XX YY.…. E .x .i .f \0
E .x .i .f \0
рассеченный RGB JPEG :
из сегментов SOI, APP9, DQT, SOS, DHT*4, SOS (с ECS), затем EOI
Наблюдения:
- Подпись слишком короткая и не читается человеком.
- «заголовок по умолчанию», то есть APP0 , не содержит типичной информации, такой как размеры или цветовое пространство, что фактически делает их необязательными (!)
- таблица квантования 100% качества очень неоптимизирована.
Структура JFIF (скачать PDF) (из официальной спецификации)
Насколько нам известно, сокращенный формат (в котором несколько файлов JPG передаются без повторного использования заголовка).
JPEG зарезервировано
-
00: nul JPEG зарезервировано
зарезервировано
-
01: TEM временный маркер для арифметического кодирования -
02: RESn зарезервировано 02-FB
JPEG 1994
определено в ITU T. 81 | ИСО/МЭК 10918-1
81 | ИСО/МЭК 10918-1
типа кадра (поддерживается libjpeg: 01/2/9/10):
-
C0: SOF0 начало кадра (базовый jpeg) -
C1: SOF1 начало кадра (расширенный последовательный, Хаффман) -
C2: SOF2 начало кадра (прогрессивный, Хаффман) -
C3: SOF3 начало кадра (без потерь, Хаффман) libjpeg-unsupported - (
C4→ см. ДХТ ) -
C5: SOF5 начало кадра (дифференциальный последовательный, Хаффман) libjpeg-unsupported -
C6: SOF6 начало кадра (дифференциальный прогрессивный, Хаффман) libjpeg-unsupported -
C7: SOF7 начало кадра (дифференциал без потерь, Хаффман) libjpeg-unsupported - (
C8→ см. JPG ) -
С9: SOF9 начало кадра (расширенный последовательный, арифметический) -
CA: SOF10 начало кадра (прогрессивный, арифметический) -
CB: SOF11 начало кадра (без потерь, арифметика) libjpeg-unsupported - (
CC→ см. DAC )
DAC ) -
CD: SOF13 начало кадра (дифференциально-последовательный, арифметический) libjpeg-unsupported -
CE: SOF14 начало кадра (дифференциально-прогрессивный, арифметический) libjpeg-unsupported -
CF: SOF15 начало кадра (дифференциальное без потерь, арифметическое) libjpeg-unsupported
Прочие
-
C8: JPG зарезервировано для расширения JPEG libjpeg-unsupported -
C4: DHT определение таблиц Хаффмана -
CC: DAC определить условие арифметического кодирования libjpeg-skiped
маркеры перезапуска (без параметров), только в данных сканирования:
-
D0: RST0 маркер перезапуска 0 -
D1: RST1 маркер перезапуска 1 -
D2: RST2 маркер перезапуска 2 -
D3: RST3 маркер перезапуска 3 -
D4: RST4 маркер перезапуска 4 -
D5: RST5 маркер перезапуска 5 -
D6: RST6 маркер перезапуска 6 -
D7: RST7 маркер перезапуска 7
разделители:
-
D8: SOI начало изображения (без параметров) -
D9: EOI конец изображения (без параметров) -
DA: SOS начало сканирования -
DB: DQT определение таблиц квантования -
DC: DNL определить количество строк # libjpeg-skiped -
DD: DRI определить интервал перезапуска -
DE: DHP определить иерархическую последовательность -
DF: EXP расширить справочные компоненты -
FE: COM данные расширения (комментарий)
JPEG 1997
расширения ITU T. 84 | ИСО/МЭК 10918-3
84 | ИСО/МЭК 10918-3
сегмента приложений:
-
E0: APP0 сегмент приложения 0 (JFIF (длина >= 14) / JFXX (длина >= 6) / AVI MJPEG) -
E1: APP1 сегмент приложения 1 (EXIF/XMP/XAP?) -
E2: APP2 сегмент приложений 2 (FlashPix/ICC) -
E3: APP3 сегмент приложений 3 (Kodak/…) -
E4: APP4 сегмент приложения 4 (FlashPix/…) -
E5: APP5 сегмент приложения 5 (Ricoh…) -
E6: APP6 сегмент приложений 6 (GoPro…) -
E7: APP7 сегмент приложений 7 (Pentax/Qualcomm) -
E8: APP8 сегмент приложений 8 (Spiff) -
E9: APP9 прикладной сегмент 9(MediaJukebox) -
EA: APP10 сегмент приложений 10 (PhotoStudio) -
EB: APP11 сегмент приложений 11 (HDR) -
EC: APP12 сегмент приложения 12 (фотошоп уточка / сохранить для сети) -
ED: APP13 сегмент приложения 13 (фотошоп сохранить как) -
EE: APP14 сегмент приложения 14 («adobe» (длина = 12)) -
EF: APP15 сегмент приложения 15 (GraphicConverter)
разделы данных расширения:
-
F0: JPG0 данные расширения 00 libjpeg-unsupported -
F1: JPG1 данные расширения 01 libjpeg-неизвестно -
F2: JPG2 данные расширения 02 libjpeg-неизвестно -
F3: JPG3 данные расширения 03 libjpeg-неизвестно -
F4: JPG4 данные расширения 04 libjpeg-неизвестно -
F5: JPG5 данные расширения 05 libjpeg-неизвестно -
F6: JPG6 данные расширения 06 libjpeg-неизвестно - (
F7→ см. SOF48 )
SOF48 ) - (
F8→ см. LSE ) -
F9: JPG9 данные расширения 09 libjpeg-неизвестно -
FA: JPG10 данные расширения 10 libjpeg-неизвестно -
FB: JPG11 данные расширения 11 libjpeg-неизвестно -
FC: JPG12 данные расширения 12 libjpeg-unknown -
FD: JPG13 данные расширения 13 libjpeg-unsupported
JPEG-LS (без потерь):
-
F7: SOF48 начало кадра -
F8: Параметры расширения LSE
определено в ISO/IEC 15444-1 JPEG 2000 Core (часть 1)
Файл JP2 начинается со структуры Atom/Box (например, mp4/mov, с типичным атомом ftyp …)
затем в конечном итоге содержит блок длиной 0 (до конца файла), который затем содержит структуру сегмента/маркеров JFIF с этими
разделители:
-
4F: SOC начало кодового потока -
90: СОТ начало плитки -
93: SOD начало . ..?
..? -
D9: EOC конец кодового потока (перекрывается EOI)
фиксированный информационный сегмент:
-
51: SIZ размер изображения и плитки
функциональных сегмента:
-
52: COD стиль кодирования по умолчанию -
53: COC компонент стиля кодирования -
5E: RGN область интереса -
5C: QCD квантование по умолчанию -
5D: QCC компонент квантования -
5F: POC изменение порядка продвижения
сегментов указателя:
-
55: TLM Длина плитки -
57: Длина пакета PLM (главный заголовок) -
58: PLT длина пакета (заголовок фрагмента) -
60: PPM заголовки упакованных пакетов (основной заголовок) -
61: PPT заголовки упакованных пакетов (заголовок части тайла)
внутренние маркеры и сегменты битового потока:
-
91: СОП начало пакета -
92: EPH конец заголовка пакета
информационные сегменты:
-
63: CRG регистрация компонента -
64: COM комментарий -
78: CBD Определение битовой глубины компонента -
74: MCT Преобразование нескольких компонентов -
75: MCC Коллекция нескольких компонентов -
77: MCO Заказ преобразования нескольких компонентов
Часть 8: Безопасный JPEG 2000
-
65: SEC SEcured Codestream -
94: INSEC INSEcured Codestream
Часть 11: JPEG 2000 для беспроводной связи
-
68: EPC Возможность защиты от ошибок -
66: EPB Блок защиты от ошибок -
67: ESD Дескриптор чувствительности к ошибкам -
69: КРАСНЫЙ Дескриптор остаточной ошибки
определено в системе кодирования ISO/IEC 18181-1 JPEG XL Core (часть 1)
-
0A: JXL начало кодового потока JPEG XL
(другие маркеры для JPEG XL не определены)
| х0 | х 1 | x2 | х3 | х 4 | х5 | х6 | х7 | х8 | х9 | хА | хВ | хС | хD | хЕ | xF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x | ноль | ТЭМ | ДЖСЛ | |||||||||||||
| 5x | СИЗ | Код наложенного платежа | КОК | ТЛМ | ПЛМ | ПЛТ | ККД | ККК | РГН | ПК | ||||||
| 6x | Ч/МН | РРТ | СРГ | КОМ | СЕК | ЭПБ | ПАЗ | ЭПК | КРАСНЫЙ | |||||||
| 9x | СОТ | СОП | ЭПХ | СОД | ИНСЕК | |||||||||||
| Сх | SOF0 | СОФ1 | SOF2 | SOF3 | ДХТ | SOF5 | SOF6 | SOF7 | JPG | SOF9 | SOF10 | SOF11 | ЦАП | SOF13 | SOF14 | SOF15 |
| Дх | РСТ0 | РСТ1 | РСТ2 | РСТ3 | РСТ4 | РСТ5 | РСТ6 | РСТ7 | СОИ | EOI/EOC | SOS | ДКТ | ДНЛ | ДРИ | ДХП | ОПЫТ |
| Пример | ПРИЛОЖЕНИЕ0 | ПРИЛОЖЕНИЕ1 | ПРИЛОЖЕНИЕ2 | ПРИЛОЖЕНИЕ3 | ПРИЛОЖЕНИЕ4 | ПРИЛОЖЕНИЕ5 | ПРИЛОЖЕНИЕ6 | ПРИЛОЖЕНИЕ7 | ПРИЛОЖЕНИЕ8 | ПРИЛОЖЕНИЕ9 | ПРИЛОЖЕНИЕ10 | ПРИЛОЖЕНИЕ11 | ПРИЛОЖЕНИЕ12 | ПРИЛОЖЕНИЕ13 | ПРИЛОЖЕНИЕ14 | ПРИЛОЖЕНИЕ15 |
| Факс | JPG0 | JPG1 | JPG2 | JPG3 | JPG4 | JPG5 | JPG6 | SOF48 | ЛСЭ | JPG9 | JPG10 | JPG11 | JPG12 | JPG13 | КОМ |
Формат файла QuickTime
нет реального стандарта, 3 варианта:
- чистая конкатенация изображений JPG.
 сразу после
сразу после EOIследует новыйSOIследующего кадра. См. кодек FFMpegmjpeg. - Motion-JPEG A (настоящий JFIF): начинается как изображение JFIF, с0043 FF E1 APP1, затем тег
mjpg, но затем со стандартной структурой JFIF (маркеры,00— заполненный ECS). - Motion-JPEG B (не JFIF): начинается непосредственно как маркер mjpg, затем не маркер JFIF для различных сегментов, поскольку заголовок
mjpgсодержит указатели на таблицу квантования, таблицу Хаффмана, начало кадра и начало сканирования. .. Данные ECS не заполнены00байтами.
-
Сегменты APPxне применяются по смещению 0, несмотря на спецификации. Они даже не требуются.
хранилище без потерь:
- , чтобы JPEG хранил данные без потерь: используйте оттенки серого, качество 100%, затем либо ширину, либо от восьми до 1 пикселя, либо дублируйте дополненные данные 8 раз (изображения JPEG хранятся в блоках 8×8).

разделенное сканирование:
-
ECSлегко превышает 64 КБ, в то время как размер сегмента COMment ограничен 64 КБ, поэтому, чтобы сохранить большой JPEG в комментариях, разделите сканирование, сделав JPEG прогрессивным или используя пользовательские сканирования с помощью управления последовательностью многократного сканирования JPEGTran
JPEG — JPEG 1
Стандарт JPEG 1 (ISO/IEC 10918) был создан в 1992 г. (последняя версия, 1994 г.) в результате процесса, начатого в 1986 г. Тем не менее, этот стандарт обычно рассматривается как единая спецификация. , на самом деле он состоит из четырех отдельных частей и набора режимов кодирования.
Часть 1 стандарта JPEG 1 (ISO/IEC 10918-1 | Рекомендация ITU-T T.81) определяет базовую технологию кодирования и включает множество вариантов кодирования фотографических изображений. Часть 2 определяет тестирование на соответствие. Часть 3 определяет набор расширений технологий кодирования части 1, и посредством поправки был введен формат файла SPIFF. Часть 4 посвящена регистрации профилей JPEG 1, профилям SPIFF, тегам SPIFF, цветовым пространствам SPIFF, типам сжатия SPIFF и определяет органы регистрации. И, наконец, часть 5 определяет формат обмена файлами JPEG (JFIF). Без всякого сомнения, можно сказать, что JPEG 1 был одним из самых успешных мультимедийных стандартов, определенных до сих пор.
Часть 4 посвящена регистрации профилей JPEG 1, профилям SPIFF, тегам SPIFF, цветовым пространствам SPIFF, типам сжатия SPIFF и определяет органы регистрации. И, наконец, часть 5 определяет формат обмена файлами JPEG (JFIF). Без всякого сомнения, можно сказать, что JPEG 1 был одним из самых успешных мультимедийных стандартов, определенных до сих пор.
Хотя JPEG 1 (рекомендация ITU T.81 | ISO/IEC 10918) по-прежнему является наиболее распространенным форматом неподвижных изображений, может показаться удивительным, что ISO/IEC никогда не предоставляла справочное программное обеспечение, демонстрирующее надлежащую реализацию стандарта. Поэтому JPEG инициировал инициативу по созданию новой эталонной реализации для ISO/IEC 10918. Дополнительную информацию о конкурсе можно найти здесь.
JPEG 1 в настоящее время включает следующие части:
Часть 1: Требования и рекомендации Определяет базовую систему кодирования, состоящую из хорошо известного формата изображения с потерями, основанного на кодировании Хаффмана DCT, но также включающего опцию арифметического кодирования, кодирование без потерь и иерархическое кодирование. |
Часть 2. Проверка соответствияОпределяет тестирование на соответствие и предоставляет процедуры тестирования и тестовые данные для проверки кодеров и декодеров JPEG 1 на соответствие. |
Часть 3: РасширенияЗадает различные расширения формата JPEG 1, такие как пространственно-переменное квантование, мозаичное отображение, выборочное уточнение и формат файла SPIFF. |
Часть 4: Органы регистрацииРегистрирует известные маркеры приложений, профили тегов SPIFF, типы сжатия и центры регистрации. |
Часть 5. Формат обмена файламиУказывает формат обмена файлами JPEG (JFIF), который включает повышающую дискретизацию цветности и преобразование YCbCr в RGB. |
Часть 6: Применение в системах печати Указывает маркеры, которые уточняют интерпретацию цветового пространства кодовых потоков JPEG 1, например, для включения встраивания профилей ICC и разрешения кодирования в цветовой модели CMYK. Jpeg что это за формат: JPEG или JPG. Чем различаются форматы изображений
|

