Что такое сжатие без потерь и как оно работает — Журнал «Код»
Мы уже разобрались с тем, как оцифровывается звук. Одна из проблем — если качественно его оцифровывать, то нам нужно очень много данных, а это значит большие файлы, большой расход места на диске, дорогие флешки, много трафика в интернете. Хочется, чтобы файлики были поменьше.
Для этого используется сжатие — различные алгоритмы, которые творят с данными свою магию и на выходе получаются данные меньшего объёма.
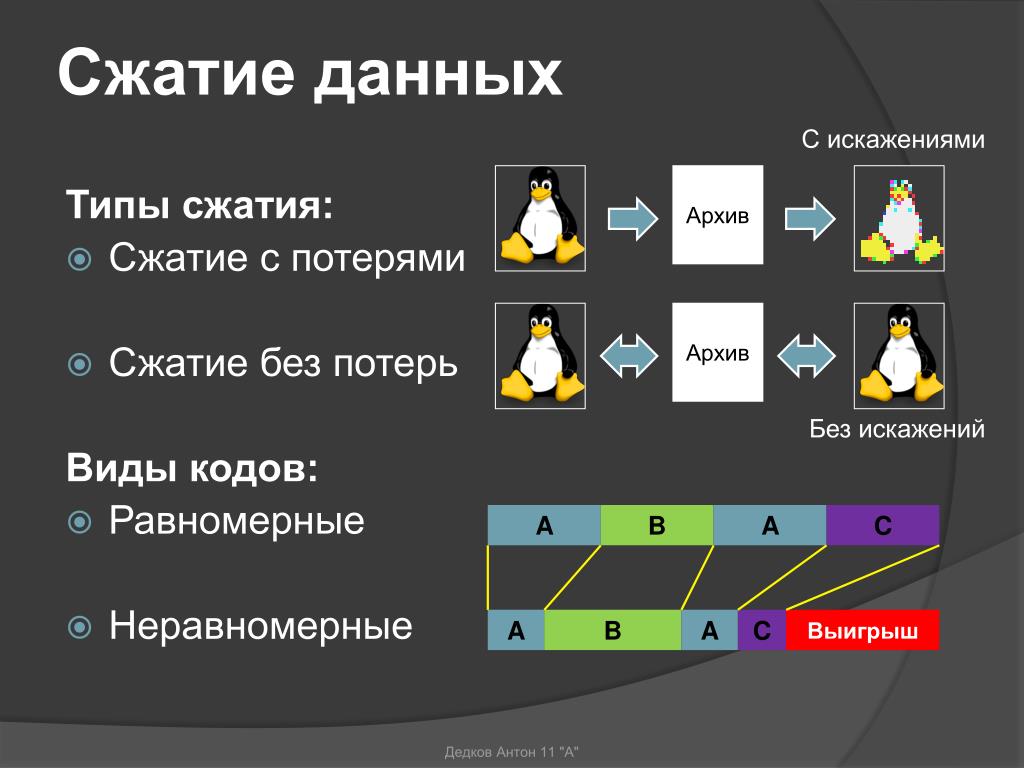
Сжатие с потерями и без потерь
Есть два принципиальных вида сжатия — с потерями и без.
Сжатие с потерями означает, что в процессе мы лишились части информации. Алгоритмы сжатия с потерями стараются сделать так, чтобы мы потеряли только те данные, которые нам не слишком важны.
Представьте, что сжатие с потерями — это краткий пересказ произведения из школьной программы: школьнику не так важны описания природы и авторский стиль, ему главное сюжет. Краткий пересказ сохранил только важное, но передал это намного быстрее.
Сжатие без потерь — это когда мы уменьшаем размер файла, при этом не теряя в качестве. Для этого используются интересные математические приёмы и кодирование. Главная мысль — чтобы при раскодировании все данные остались на месте.
Алгоритмы сжатия без потерь
Есть два основных варианта: алгоритм Хаффмана или LZW. LZW используется повсеместно, но объяснить его довольно сложно, он неинтуитивный и требует целой лекции. Гораздо приятнее объяснить алгоритм Хаффмана.
Алгоритм Хаффмана берёт файл, разбивает его на фрагменты, с которыми ему удобно работать, а потом смотрит, насколько часто встречается каждый фрагмент. Самые частые слова этот алгоритм обозначает коротким кодом, а самые редкие — кодом подлиннее. Так как самые частые слова занимают теперь гораздо меньше места, то и готовый файл становится меньше.
Но есть и минус: иногда нужно хранить эту таблицу соответствий слов и кода прямо в этом же файле, а она может сама по себе получиться большой. Чаще всего алгоритм Хаффмана применяется для сжатия текстовых файлов и видео без потерь.
Чаще всего алгоритм Хаффмана применяется для сжатия текстовых файлов и видео без потерь.
Вот пример: берём песню Beyonce — All The Single Ladies. Там есть два таких пассажа:
All the single ladies
All the single ladies
All the single ladies
Now put your hands up
…
If you like it then you shoulda put a ring on it
If you like it then you shoulda put a ring on it
Don’t be mad once you see that he want it
If you like it then you shoulda put a ring on it
Здесь 281 знак. Мы видим, что некоторые строчки повторяются. Закодируем их:
ТАБЛИЦА СЖАТИЯ
\a\ All the single ladies
\b\ Now put your hands up
\c\ If you like it then you shoulda put a ring on it
\d\ Don’t be mad once you see that he want it
ТЕКСТ ПЕСНИ
\a\ \a\ \a\ \b\
…
\c\ \c\ \d\ \c\
Вместе таблицей сжатия этот текст теперь занимает 187 знаков — мы сжали текст почти на треть благодаря тому, что он довольно монотонный.
Сжатие без потерь на примере аудио
В среднем минута несжатого аудио занимает 10 мегабайт. Это довольно много: если у вас, например, часовая запись концерта, то она будет занимать полгигабайта. С другой стороны, в этой записи захвачены все нюансы звука, есть много высоких частот и вообще красота.
Для таких ситуаций используют сжатие без потерь: оно уменьшает файл в 2–3 раза, не искажая звук. Алгоритмы, которые сжимают аудио, называются кодеками. FLAC и Apple Lossless — два популярных кодека для сжатия аудио без потерь.
Сравните сами размер и качество двухминутного аудио:
Оригинал — без сжатия, формат WAV, 23 мегабайта
Сжатие без потерь — формат FLAC с теми же параметрами, что и WAV, 10 мегабайт
Где ещё применяется сжатие без потерь
В архиваторах. Задача программ-архиваторов — упаковать выбранные файлы так, чтобы архив занимал как можно меньше места, при этом не повреждая то, что внутри. Например, текстовая версия «Войны и мира» может занимать 4 мегабайта, а заархивированная — 100 килобайт, в 40 раз меньше.
Myspace потеряла архивы за 12 лет. Как не потерять свои
В программировании. Есть специальные упаковщики, которые берут готовую программу и оптимизируют код так, чтобы он занимал меньше места, но сохранил свою работоспособность. Например:
- Удаляют комментарии
- Сокращают до минимума названия переменных и функций
- Удаляют символы, которые нужны были человеку для удобочитаемости
Что дальше
В следующей части разберём, как работает сжатие с потерями и почему благодаря этому у нас есть ТикТок и Ютуб.
Сжатие информации без потерь. Часть первая / Хабр
Доброго времени суток.
Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
- Пересылка документов по электронной почте (особенно больших объемов документов с использованием мобильных устройств)
- При публикации документов на сайтах, потребность в экономии трафика
- Экономия дискового пространства в тех случаях, когда замена или добавление средств хранения затруднительно.
 Например, подобное бывает в тех случаях, когда выбить бюджет под капитальные расходы непросто, а дискового пространства не хватает
Например, подобное бывает в тех случаях, когда выбить бюджет под капитальные расходы непросто, а дискового пространства не хватает
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
| Сжатие с потерями |
Лучшие степени сжатия, при сохранении «достаточно хорошего» качества данных. Применяются в основном для сжатия аналоговых данных — звука, изображений. В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений. В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений. |
| Сжатие без потерь |
| Данные восстанавливаются с точностью до бита, что не приводит к каким-либо потерям информации. Однако, сжатие без потерь показывает обычно худшие степени сжатия. |
Итак, перейдем к рассмотрению алгоритмов сжатия без потерь.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Третья группа методов – это так называемые методы преобразования блока. Входящие данные разбиваются на блоки, которые затем трансформируются целиком. При этом некоторые методы, особенно основанные на перестановке блоков, могут не приводить к существенному (или вообще какому-либо) уменьшению объема данных. Однако после подобной обработки, структура данных значительно улучшается, и последующее сжатие другими алгоритмами проходит более успешно и быстро.
Однако после подобной обработки, структура данных значительно улучшается, и последующее сжатие другими алгоритмами проходит более успешно и быстро.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon’s source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики
Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами.
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей p
k(si) для всех элементов si.
Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.
Пусть задан некоторый алфавит , состоящий из некоторого (конечного) числа букв. Назовем каждую конечную последовательность символов из этого алфавита (A=a1, a2,… ,an) словом, а число n — длиной этого слова.
Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a2 <-> B2
…
an <-> Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Пусть слово B имеет вид B=B’B». Тогда B’ называют началом, или префиксом слова B, а B» — его концом. Это довольно простое определение, но нужно отметить, что для любого слова B, и некое пустое слово ʌ («пробел»), и само слово B, могут считаться и началами и концами.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Итак, мы разобрались с основными определениями. Так как же происходит само кодирование без памяти?
Оно происходит в три этапа.
- Составляется алфавит Ψ символов исходного сообщения, причем символы алфавита сортируются по убыванию их вероятности появления в сообщении.
- Каждому символу ai из алфавита Ψ ставится в соответствие некое слово Bi из префиксного множества Ω.
- Осуществляется кодирование каждого символа, с последующим объединением кодов в один поток данных, который будет являться результатам сжатия.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
В первую очередь при кодировании алгоритмом Хаффмана, нам нужно построить схему ∑. Делается это следующим образом:
- Все буквы входного алфавита упорядочиваются в порядке убывания вероятностей. Все слова из алфавита выходного потока (то есть то, чем мы будем кодировать) изначально считаются пустыми (напомню, что алфавит выходного потока состоит только из символов {0,1}).
- Два символа aj-1 и aj входного потока, имеющие наименьшие вероятности появления, объединяются в один «псевдосимвол» с вероятностью p равной сумме вероятностей входящих в него символов. Затем мы дописываем 0 в начало слова Bj-1, и 1 в начало слова Bj, которые будут впоследствии являться кодами символов aj-1 и aj соответственно.
- Удаляем эти символы из алфавита исходного сообщения, но добавляем в этот алфавит сформированный псевдосимвол (естественно, он должен быть вставлен в алфавит на нужное место, с учетом его вероятности).

Шаги 2 и 3 повторяются до тех пор, пока в алфавите не останется только 1 псевдосимвол, содержащий все изначальные символы алфавита. При этом, поскольку на каждом шаге и для каждого символа происходит изменение соответствующего ему слова Bi (путем добавление единицы или нуля), то после завершения этой процедуры каждому изначальному символу алфавита ai будет соответствовать некий код Bi.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — { a1, a2, a3, a4}. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
- Объединяем два символа с наименьшими вероятностями (0.11 и 0.
 15) в псевдосимвол p’.
15) в псевдосимвол p’. - Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Объединяем два символа с наименьшей вероятностью (0.24 и 0.26) в псевдосимвол p».
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Наконец, объединяем оставшиеся два символа, и получаем вершину дерева.
Если сделать иллюстрацию этого процесса, получится примерно следующее:
Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
a1 = 0
a2 = 11
a3 = 100
a4 = 101
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).
Литература
- Ватолин Д., Ратушняк А., Смирнов М. Юкин В. Методы сжатия данных.
 Устройство архиваторов, сжатие изображений и видео; ISBN 5-86404-170-X; 2003 г.
Устройство архиваторов, сжатие изображений и видео; ISBN 5-86404-170-X; 2003 г. - Д. Сэломон. Сжатие данных, изображения и звука; ISBN 5-94836-027-Х; 2004г.
- www.wikipedia.org
Что такое сжатие без потерь и сжатие с потерями?
К
- Рахул Авати
Что такое сжатие без потерь и сжатие с потерями?
Сжатие файлов без потерь и с потерями описывает, можно ли восстановить все исходные данные, когда файл не сжат.
При сжатии без потерь каждый бит исходных данных в файле остается после распаковки, и вся информация восстанавливается. Сжатие с потерями уменьшает размер файла, навсегда удаляя определенную информацию, особенно избыточную.
Когда файл несжатый, часть исходной информации отсутствует, хотя пользователь может этого не заметить.
Что такое сжатие файлов?
Цифровые файлы, такие как файлы изображений, часто «сжимаются» для уменьшения их размера и/или изменения различных атрибутов, например:
- тип файла
- размеры
- разрешение
- битовая глубина
Сжатие уменьшает размер файла, часто без заметной потери информации. Он может быть как без потерь, так и с потерями.
Сжатый файл меньшего размера можно восстановить до большей формы — полностью или с некоторой потерей данных, в зависимости от типа сжатия — путем распаковки.
Сравнение сжатия без потерь и сжатия с потерями
Сжатие без потерь восстанавливает и перестраивает данные файла в его исходную форму после распаковки файла. Например, при сжатии файла изображения его качество остается прежним.
Файл можно распаковать до исходного качества без потери данных. Этот метод сжатия также известен как обратимое сжатие.
Несмотря на то, что при использовании этого метода размеры файлов уменьшаются, уменьшение меньше по сравнению с уменьшением с использованием сжатия с потерями.
При сжатии с потерями данные в файле удаляются и не восстанавливаются в исходную форму после распаковки. В частности, данные удаляются навсегда, поэтому этот метод также известен как необратимое сжатие .
Эта потеря данных обычно незаметна. Однако чем сильнее сжат файл, тем больше происходит деградация, и потеря в конечном итоге становится заметной.
Сжатие с потерями уменьшает размер файла намного больше, чем размер файла после сжатия без потерь.
Lossless и lossy — это методы сжатия данных для уменьшения размера файлов.Применение сжатия без потерь и с потерями
Сжатие без потерь в основном используется для сжатия:
- изображений
- звук
- текст
Как правило, это метод выбора для подробных изображений продуктов, фотографий витрин, текстовых файлов и файлов электронных таблиц, где потеря качества изображения, слов или данных (например, финансовых данных) может создать проблему.
Графический файл обмена (GIF), формат изображения, используемый в Интернете, обычно сжимается с использованием сжатия без потерь. RAW, BMP и PNG также являются форматами изображений без потерь.
Сжатие с потерями в основном используется для сжатия:
- изображений
- аудио
- видео
Этот метод предпочтителен для аудио- и видеофайлов, где допустима некоторая потеря информации, поскольку большинство пользователей вряд ли обнаружат ее. Файл изображения JPEG, обычно используемый для фотографий и других сложных неподвижных изображений в Интернете без прозрачности, обычно сжимается с использованием сжатия с потерями.
Используя сжатие JPEG, создатель может решить, какие потери внести и какой компромисс допустим между размером файла и качеством изображения.
Сжатие с потерями также подходит для веб-сайтов с файлами JPEG и быстрой загрузкой, поскольку степень сжатия можно регулировать, сохраняя при этом правильный баланс.
Алгоритмы, используемые при сжатии без потерь и с потерями
Различные виды алгоритмов используются для уменьшения размеров файлов при сжатии без потерь и с потерями.
При сжатии без потерь используются следующие алгоритмы:
- Кодирование длины серии
- Лемпель-Зив-Велч (LZW)
- Код Хаффмана
- Арифметическое кодирование
При сжатии с потерями используются следующие алгоритмы:
- Кодирование преобразования
- Дискретное косинусное преобразование
- Дискретное вейвлет-преобразование
- Фрактальное сжатие
Преимущества и недостатки сжатия без потерь
Основное преимущество сжатия без потерь заключается в том, что качество файла (например, изображения) может быть сохранено при уменьшении размера файла.
В файлах JPEG и PNG это делается путем удаления ненужных метаданных. Для приложений, где важно сохранить качество файла, лучшим выбором будет сжатие без потерь.
Недостаток этого метода сжатия заключается в том, что для сохранения качества после сжатия требуются файлы большего размера.
Преимущества и недостатки сжатия с потерями
Сжатие с потерями приводит к значительному уменьшению размера файла (меньше, чем сжатие без потерь), что является его наиболее примечательным преимуществом. Он поддерживается многими инструментами, плагинами и программными продуктами, которые позволяют пользователю выбирать предпочтительную степень сжатия.
Недостатком является то, что это также приводит к потере качества, что может быть неприемлемо для некоторых приложений или пользователей. Чем выше степень сжатия, тем больше ухудшение качества. Кроме того, исходный файл с исходным качеством невозможно восстановить после сжатия.
Выбор сжатия данных без потерь или с потерями зависит от трех факторов: приложения, для которого оно используется, приемлемого уровня потери качества и желаемого размера файла.
Что лучше выбрать для сжатия: без потерь или с потерями?
Не существует «правильного» или «лучшего» ответа, когда дело доходит до выбора между сжатием без потерь и сжатием с потерями. Выбор зависит от:
- приложение
- допустимый уровень потери качества
- желаемый размер файла
Так, например, блог или веб-сайт портфолио могут выиграть от сжатия с потерями, поскольку оно обеспечивает значительное уменьшение размера файла, экономит место для хранения и повышает производительность сайта и удобство для пользователей. С другой стороны, веб-сайту, которому требуются высококачественные фотографии, лучше использовать сжатие без потерь.
Также можно использовать оба типа сжатия для одного и того же приложения.
Последнее обновление: октябрь 2021 г.
Продолжить чтение О сжатии без потерь и с потерями
- Учебник по хранению данных ДНК и возможному использованию
- Сжатие, дедупликация и шифрование: в чем разница?
- Как устранить 8 распространенных ограничений автоэнкодера
- Как вычислительный накопитель меняет вычисления
- 5 советов, как уменьшить вес веб-страницы и улучшить взаимодействие с пользователем
когнитивное искажение
Когнитивное искажение — это систематический мыслительный процесс, вызванный склонностью человеческого мозга к упрощению обработки информации через фильтр личного опыта и предпочтений.
Сеть
-
коллизия в сети
В полудуплексной сети Ethernet коллизия возникает в результате попытки двух устройств в одной сети Ethernet передать.
 ..
.. -
краеугольный камень домкрат
Гнездо трапецеидального искажения — это гнездовой разъем, используемый для передачи аудио, видео и данных. Он служит гнездом для соответствующей вилки…
-
инкапсуляция (объектно-ориентированное программирование)
В объектно-ориентированном программировании (ООП) инкапсуляция — это практика объединения связанных данных в структурированную единицу вместе с …
Безопасность
-
маскировка
Маскировка – это метод, при котором пользователям возвращается версия веб-контента, отличная от той, которую получают сканеры поисковых систем.
-
Вредоносное ПО TrickBot
TrickBot — это сложное модульное вредоносное ПО, которое начиналось как банковский троян, а затем эволюционировало, чтобы поддерживать множество различных типов …
-
Общая система оценки уязвимостей (CVSS)
Общая система оценки уязвимостей (CVSS) — это общедоступная платформа для оценки серьезности уязвимостей безопасности в .
 ..
..
ИТ-директор
-
качественные данные
Качественные данные — это информация, которую невозможно подсчитать, измерить или выразить с помощью чисел.
-
зеленые ИТ (зеленые информационные технологии)
Green IT (зеленые информационные технологии) — это практика создания и использования экологически устойчивых вычислительных ресурсов.
-
Agile-манифест
The Agile Manifesto — это документ, определяющий четыре ключевые ценности и 12 принципов, в которые его авторы верят разработчикам программного обеспечения…
HRSoftware
-
опыт кандидата
Опыт кандидата отражает отношение человека к прохождению процесса подачи заявления о приеме на работу в компанию.
-
непрерывное управление производительностью
Непрерывное управление эффективностью в контексте управления человеческими ресурсами (HR) представляет собой надзор за работой сотрудника .
 ..
.. -
вовлечения сотрудников
Вовлеченность сотрудников — это эмоциональная и профессиональная связь, которую сотрудник испытывает к своей организации, коллегам и работе.
Служба поддержки клиентов
-
распознавание голоса (распознавание говорящего)
Распознавание голоса или говорящего — это способность машины или программы принимать и интерпретировать диктовку или понимать и …
-
Облачная служба Salesforce
Salesforce Service Cloud — это платформа управления взаимоотношениями с клиентами (CRM), позволяющая клиентам Salesforce предоставлять услуги и …
-
БАНТ
BANT — это аббревиатура от «Budget, Authority, Need, Timing».
Какой лучший формат изображения без потерь? Сравнение PNG, WebP, AVIF и JPEG XL — siipo.la
В прошлогоднем блоге я рассмотрел форматы изображений с потерями и то, как они складываются. На этот раз я подумал, что было бы интересно сравнить форматы изображений без потерь.
На этот раз я подумал, что было бы интересно сравнить форматы изображений без потерь.
Что такое сжатие без потерь?
Сжатие без потерь — это способ уменьшить размер файла, чтобы его можно было быстрее передать или загрузить, но при этом его можно распаковать обратно в тот же исходный файл. ZIP и RAR — популярные форматы файлов без потерь для сжатия файлов. В веб-контексте сжатие GZIP часто используется для уменьшения файлов JavaScript и CSS. В сжатии изображений PNG является хорошо известным форматом без потерь.
Альтернативой сжатию без потерь является сжатие с потерями, которое часто используется при сжатии фотографий. JPEG, вероятно, является самым известным форматом изображений с потерями. Сжатие с потерями приведет к потере некоторых деталей изображения, что приведет к значительному уменьшению размера файла. Поскольку в противном случае большие фотографии были бы слишком большими для передачи и хранения, потеря качества часто является хорошим компромиссом.
Когда использовать сжатие без потерь?
Хотя форматы изображений с потерями, такие как JPEG и WebP с потерями, отлично подходят для фотографий, они не так хороши для графики. Артефакты сжатия, такие как блочные артефакты и размытие, могут быть легко видны и отвлекать на таких изображениях.
Сжатие без потерь отлично подходит для изображений с большими непрерывными областями цвета, поскольку они хорошо сжимаются с использованием алгоритмов сжатия без потерь. Вы можете представить себе классический алгоритм Run-Length Encoding (RLE), который очень эффективно сжимает повторяющиеся данные. Реальные алгоритмы, используемые этими форматами, конечно, сложнее.
Таким образом, сжатие изображений без потерь лучше всего подходит для таких вещей, как логотипы, снимки экрана, диаграммы и графика. Сжатие таких изображений с помощью сжатия без потерь часто может привести к уменьшению размера файлов с лучшим качеством по сравнению со сжатием с потерями.
Пример изображения, на котором хорошо работает сжатие без потерь.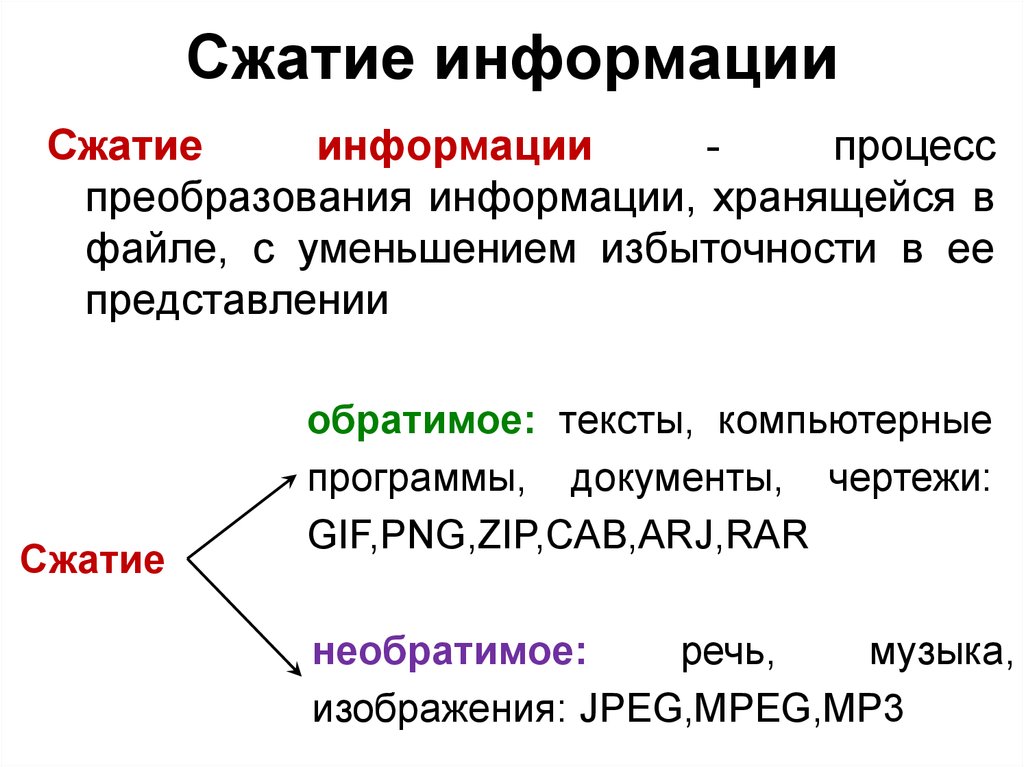 Символ переработки в формате PNG занимает 3 килобайта. JPEG при том же размере файла имеет заметные артефакты сжатия. JPEG с максимально возможным качеством выглядит так же, как PNG, но в восемь раз больше.
Символ переработки в формате PNG занимает 3 килобайта. JPEG при том же размере файла имеет заметные артефакты сжатия. JPEG с максимально возможным качеством выглядит так же, как PNG, но в восемь раз больше.
Выбор набора данных
Для тестирования сжатия без потерь нам сначала понадобятся изображения. Поскольку сжатие без потерь не очень эффективно для фотографий, нам понадобятся несколько образцов изображений, содержащих графику, логотипы и текст. В итоге я загрузил набор изображений с Dribbble, сайта-портфолио для дизайнеров.
На большинстве изображений изображены веб-сайты, мобильные приложения, логотипы или иллюстрации. Такие изображения идеально подходят для сжатия без потерь. Я скачал около 100 или около того самых популярных «шотов» или изображений с сайта.
Так как многие изображения были довольно большими, уменьшили изображения до максимальной ширины 1000 пикселей, чтобы их сжатие не занимало очень много времени. Я также убедился, что цветовое пространство sRGB.
Примеры изображений из набора данных Dribbble. Авторское право на изображение: Майк | Creative Mints, Тарас Мигулко, Энес Акташ, Макс Панчик, Майк | Creative Mints, Tran Mau Tri Tam, DStudio, Брэд Кузен, Мелисса Миямото-Миллс
Вы можете скачать тестовые изображения здесь.
Форматы файлов для тестирования
Я решил протестировать следующие форматы изображений: PNG, WebP без потерь, AVIF и JPEG XL. Все они сегодня могут использоваться в браузерах, за исключением JPEG XL, который поддерживается в Chrome и Firefox, но сначала его необходимо включить с помощью флага функции. JPEG XL, скорее всего, будет поддерживаться по умолчанию в будущих версиях этих браузеров.
Все эти форматы файлов имеют параметр скорости кодирования. При указании низкой скорости кодирование занимает больше времени, но результирующее изображение будет меньше. При высокой скорости кодирования все наоборот. Я использовал максимально возможную скорость во всех примерах, чтобы получить максимальную отдачу от форматов изображений.
PNG означает переносимую сетевую графику. Это один из старейших форматов веб-изображений, впервые выпущенный в 1996 году. Первоначально он был разработан как альтернатива формату GIF, который в то время был запатентован. PNG имеет много преимуществ по сравнению с GIF, включая полный 24-битный цвет (8 бит на канал) и альфа-канал. Формат GIF ограничен 256 цветами на изображение и одним прозрачным цветом.
Формат файла PNG основан на алгоритме сжатия DEFLATE и имеет специальную настройку фильтра, предсказывающую значения цвета. Это привело к разработке нескольких инструментов оптимизации PNG, которые проверяют различные параметры сжатия, чтобы минимизировать размер файла. Одними из самых известных являются PNGOUT, OptiPNG и OxiPNG на основе Rust. Также можно заменить обычное сжатие DEFLATE на сжатие Zopfli от Google, которое совместимо с DEFLATE, но обеспечивает более высокое сжатие за счет гораздо более длительного времени сжатия.
Формат PNG поддерживается всеми браузерами.
Я сжал файлы PNG с помощью OxiPNG v5.0.0, используя максимально возможный уровень оптимизации с помощью следующей команды:
oxipng /path/to/input/image.png --out /path/to/output/image.png --opt max --strip safe
Я также оптимизировал тот же набор изображений, используя сжатие Zopfli, которое занимает очень много времени, но приводит к еще меньшему размеру файлов.
oxipng /path/to/input/image.png --out /path/to/output/image.png --opt max --strip safe --zopfli
Google запустил WebP в 2010 году как формат изображения с потерями на основе видеокодека VP8. WebP 0.3, выпущенный в 2012 году, представил режим без потерь, который не имеет отношения к кодеку VP8. В то время как WebP с потерями ограничен субдискретизацией Chroma 4: 2: 0, которая отбрасывает некоторую информацию о цвете, WebP без потерь сохранит все исходные данные изображения.
В дополнение к режимам с потерями и без потерь, WebP также поддерживает режим «почти без потерь», но я не тестировал его в этой статье. Такая опция может быть полезна в некоторых случаях, но я обычно не нахожу ее полезной, поскольку предпочитаю выбирать между кодированием без потерь и кодированием с потерями, а не что-то среднее.
Такая опция может быть полезна в некоторых случаях, но я обычно не нахожу ее полезной, поскольку предпочитаю выбирать между кодированием без потерь и кодированием с потерями, а не что-то среднее.
До недавнего времени браузер Safari от Apple был единственным противником WebP. С 2021 года WebP поддерживается всеми основными браузерами.
Для WebP я использовал официальный инструмент cwebp версии 1.2.0. Для лучшего сжатия я определил качество 100 и метод 6.
cwebp /path/to/input/image.png -o /path/to/output/image.webp -q 100 -m 6 -lossless
AVIF означает формат файла изображения AV1. Это новый формат изображения, основанный на видеокодеке AV1. Он имеет множество дополнительных функций, таких как поддержка высокой битовой глубины и HDR. Формат поддерживает сжатие как без потерь, так и с потерями.
AVIF поддерживается в последних версиях Google Chrome и может быть включен в Firefox с помощью флага конфигурации.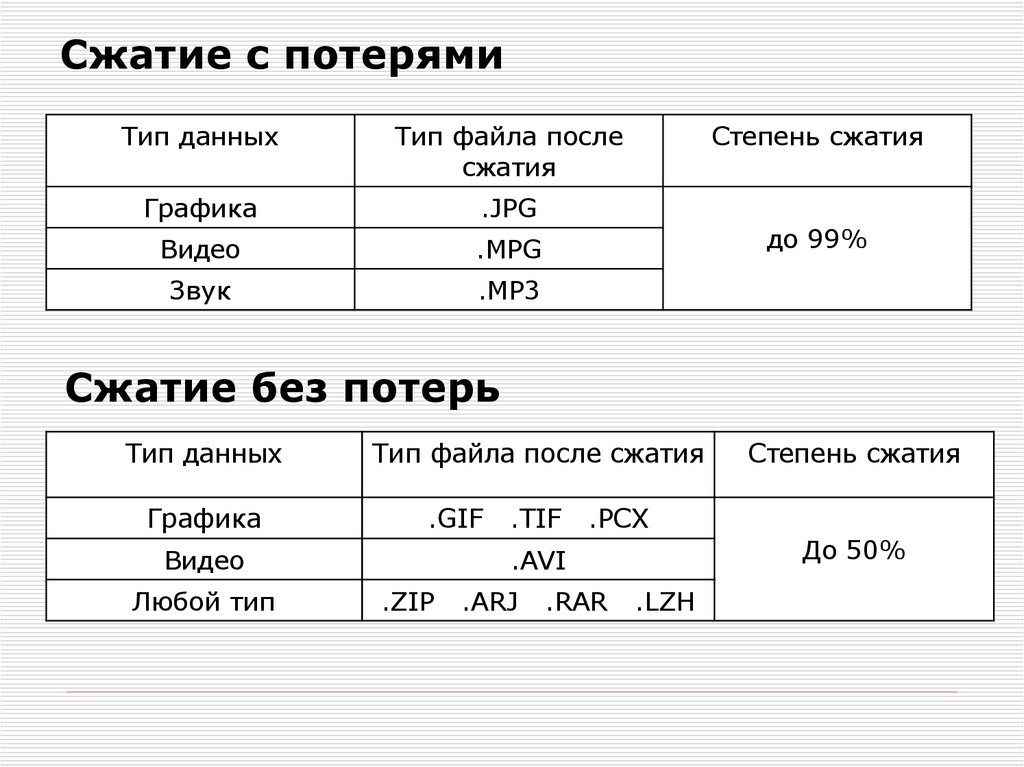
Для кодирования файлов AVIF я использовал avifenc v0.9.1 от libavif. Я использовал самую низкую возможную скорость, чтобы получить наилучшее сжатие.
avifenc --lossless --speed 0 /path/to/input/image.png /path/to/output/image.avif
JPEG XL
JPEG XL — это новый и перспективный формат изображения. JPEG XL был разработан путем объединения двух существующих форматов изображений: формата изображений Pik, разработанного Google, и FUIF (бесплатный универсальный формат изображений), разработанного в Cloudinary.
Инструмент командной строки cjxl по умолчанию использует формат на основе Pik с именем VarDCT, но модульный режим, производный от FUIF, можно выбрать, указав флаг –modular в командной строке. JPEG XL поддерживает сжатие как без потерь, так и с потерями.
JPEG XL поддерживается в Chrome и Firefox, но не включен по умолчанию. Поддержка формата должна быть включена с помощью флага функции.
Для сжатия файлов JPEG XL я использовал официальный инструмент cjxl версии 0.3.7_1.
cjxl /path/to/input/image.png /path/to/output/image.jxl --modular --quality 100 --speed 9-E 3
В остальном флаги командной строки говорят сами за себя, за исключением флага -E, который, как я слышал, означает «дополнительные аргументы». Я использовал значение 3, которое рекомендуется для лучшего сжатия. Использование этой опции уменьшило размер файла на несколько килобайт, а сжатие изображения заняло немного больше времени.
Результаты
Вот результаты для 94 изображений. Столбцы отображают средние результаты, а столбцы погрешностей иллюстрируют 25-й и 75-й процентили. Вы можете увидеть полные данные в виде электронной таблицы здесь.
Размер файла
Скорость кодирования
Я подумал, что было бы интересно также сравнить скорость сжатия файлов разных форматов. Для справки, кодирование было выполнено на моем 15-дюймовом MacBook Pro 2015 года.
Для справки, кодирование было выполнено на моем 15-дюймовом MacBook Pro 2015 года.
Заключение
Судя по результатам тестов, можно сделать вывод, что большинство современных форматов изображений без потерь, таких как WebP и JPEG XL, обеспечивают значительный прирост эффективности по сравнению даже с наиболее оптимизированным PNG.
Оптимизация файлов PNG с помощью OxiPNG может сделать их немного меньше, примерно на 12%, что не является существенной разницей. OxiPNG работает очень быстро: обработка одного изображения занимает всего около 700 миллисекунд.
Использование параметра Zopfli с OxiPNG делает оптимизацию чрезвычайно медленной, в среднем занимая около 208 секунд или три с половиной минуты. Полученные файлы примерно на 18% меньше по сравнению с исходными PNG. Я бы не рекомендовал использовать сжатие Zopfli, потому что оно занимает очень много времени и дает файлы только немного меньшего размера. Более новый формат, такой как WebP или JPEG XL, создает файлы гораздо меньшего размера, а время кодирования составляет лишь часть времени Zopfli.
Так как выигрыш от оптимизации PNG очень мал, а процесс занимает так много времени, может быть вообще нецелесообразно оптимизировать файлы PNG, если вместо этого вы можете использовать более современный формат. Даже неоптимизированный формат PNG может быть хорошим выбором в качестве формата исходного изображения, поскольку он совместим с большинством программ, таких как редакторы изображений и системы управления контентом. Затем вы можете преобразовать исходные файлы PNG в более эффективный формат, прежде чем отображать их конечным пользователям. PNG также может быть полезным резервным форматом для клиентов, которые не могут отображать современные форматы, таких как некоторые почтовые клиенты и старые браузеры.
WebP — хороший выбор для изображений без потерь, так как он легко выигрывает у PNG, когда дело доходит до эффективности сжатия, имея изображения в среднем на 41% меньше. Он также широко поддерживается в веб-браузерах и другом программном обеспечении. Файлы WebP также быстро кодируются, сжатие занимает всего около 3 секунд.
Должен сказать, я немного разочарован работой AVIF. Хотя сжатие AVIF с потерями занимает много времени, оно дает отличные результаты сжатия по сравнению с JPEG и WebP. К сожалению, этого нельзя сказать о AVIF без потерь.
В режиме без потерь кодирование файла AVIF занимает в среднем 30 секунд, но результаты не так хороши по сравнению с другими конкурирующими форматами. При среднем уменьшении примерно на 20% результирующие размеры файлов сопоставимы с OxiPNG с Zopfli, но заметно больше по сравнению с WebP или JPEG XL. При использовании AVIF я бы придерживался сжатия с потерями, которое этот формат делает лучше всего.
JPEG XL
JPEG XL — новый формат, который производит сильное впечатление. Среднее уменьшение размера файла составляет около 48%, что немного лучше, чем у WebP. Если посмотреть на 75-й процентиль, JPEG XL имеет преимущество перед WebP, что означает, что JPEG XL лучше справляется со сложными изображениями, которые трудно сжать. Кодирование изображения JPEG XL занимает в среднем около 24 секунд, что довольно медленно, но опять же, я намеренно использую самые медленные настройки.