«Почему 1 байт равен 8 битам (при использовании в мире десятичной системы счисления)?» — Яндекс Кью
Популярное
Сообщества
ТехнологииКомпьютеры
Анонимный вопрос
·
827
ОтветитьУточнитьВиталий Сергеев
Программирование
959
старший разработчик в DATADVANCE · 2 нояб 2021
На первый взгляд кажется, что десятичная система и длина байта никак не связаны. Не удивляет же нас что, например, в почтовом индексе шесть цифр, а не десять. Так и тут, бит — это просто цифра двоичного числа, а уж сколько там этих цифр — вопрос отдельный.
На заре компьютеростроения байты имели разную длину. Были и четырёхбитные байты, и шестибитные. А совсем старые ЭВМ так и вовсе оперировали не байтами, а машинными словами, при этом адресовать конкретный байт внутри слова они не умели.
Однако довольно быстро инженеры пришли к тому, что выгоднее всего разбивать двоичные данные на небольшие одинаковые кусочки (те самые «байты»). Осталось выбрать длину такого кусочка. Длина в восемь бит оказалась самой оптимальной по нескольким причинам:
- Восемь это степень двойки, что было выгодно для аппаратной реализации двоичной системы. Ну тут чисто инженерная причина
- Далее, в восемь бит можно закодировать любой нужный символ в кодировке EBCDIC. Это упрощало работу со строками, так как при этом каждый байт соответствует одному символу. Резервировать больше бит не стали, ибо памяти в то время не хватало
- Наконец, при операциях с десятичным представлением чисел использовался формат BCD, при котором десятичная цифра представлена четырьмя битами. То есть в один байт можно записать два десятичных разряда
 Именно четыре бита нужно, чтобы закодировать все цифры от 0 до 9.
Именно четыре бита нужно, чтобы закодировать все цифры от 0 до 9.Бесплатные консультации по JS в Телеграме
Перейти на t.me/jstsmentorКомментировать ответ…Комментировать…
Алексей Грин
Технологии
945
ИТ-блогер и сборщик ПК => · 4 окт 2021 ·
Добрый день, Аноним. Десятичная система счисления используется людьми для их же удобства, а вот компьютерам удобно использовать двоичную систему счисления. Биты это единица измерения компьютерной информации, поэтому не следует смешивать их с человеческой системой счисления. Если говорить совсем упрощённо, то управление всеми процессами в компьютере завязано на… Читать далее
Не будь редиской, если помог — подпишись😎
Перейти на vk.com/s3boxКомментировать ответ…Комментировать…
Вы знаете ответ на этот вопрос?
Поделитесь своим опытом и знаниями
Войти и ответить на вопрос
Почему в одном байте 8 бит?
Почему в одном байте 8 бит?
Байтовая адресация памяти была впервые применена в системе IBM System/360. … 8-битные байты были приняты в System/360, вероятно, из-за использования BCD-формата представления чисел: одна десятичная цифра (0−9) требует 4 бита (тетраду) для хранения; один 8-битный байт может представлять две десятичные цифры.
… 8-битные байты были приняты в System/360, вероятно, из-за использования BCD-формата представления чисел: одна десятичная цифра (0−9) требует 4 бита (тетраду) для хранения; один 8-битный байт может представлять две десятичные цифры.
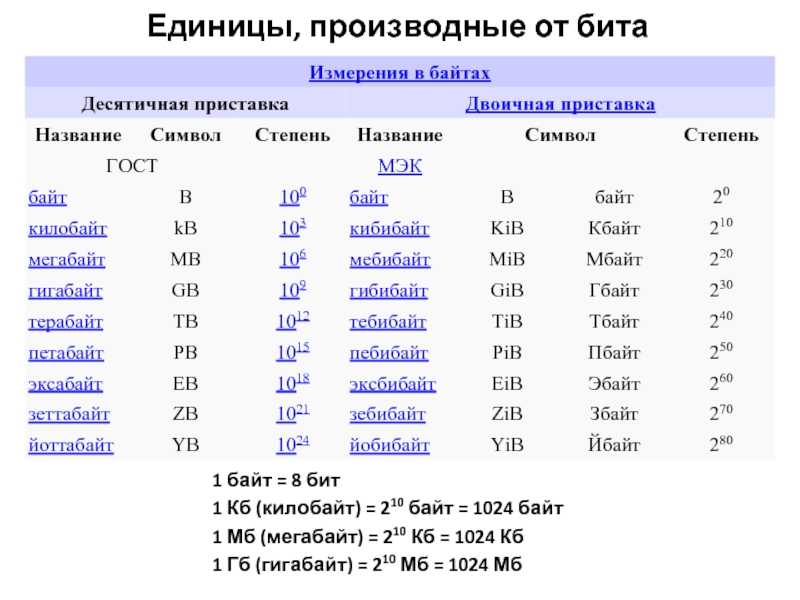
Сколько бит содержит 1 килобайт?
Тут все просто и без подводных камней. Если в одном байте 8 бит, то в одном килобайте 8 килобит, а в одном мегабайте — 8 мегабит.
Сколько бит в слове байт?
Так что ответ «11 байт или 88 бит» предполагает, что мы с получателем используем одну и ту же однобайтовую кодировку, содержащую кириллические буквы.
Сколько бит информации содержит сообщение объёмом 128 Кб?
128 Кбайт = 128 * 1024 байт = 128 * 8 * 1024 бит = 1048576 бит.
Какое количество бит содержится в одном Мегабайте?
В каждом мегабайте 1024 килобайта, а в каждом килобайте 1024 байта, а значит, один мегабайт содержит 1024*1024 = 1048576 байт: Один байт равен восьми битам. Один килобайт (обозначается как 1кб или 1kb) равен восьми килобитам (обозначается как 1 кбит, или 1kbit, в некоторых случаях 1kbps).
Один килобайт (обозначается как 1кб или 1kb) равен восьми килобитам (обозначается как 1 кбит, или 1kbit, в некоторых случаях 1kbps).
Сколько бит в Мегабайте в степени?
Мегабайт в Бит
| 1 Мегабайт = 8388608 Бит | 10 Мегабайт = Бит |
|---|---|
| 2 Мегабайт = Бит | 20 Мегабайт = Бит |
| 3 Мегабайт = Бит | 30 Мегабайт = Бит |
| 4 Мегабайт = Бит | 40 Мегабайт = Бит |
| 5 Мегабайт = Бит | 50 Мегабайт = Бит |
Как найти килобайт?
Чтобы узнать, сколько бит в байте, необходимо, количество бит разделить на 8. Далее полученное число (байты) разделить 1024, таким образом, мы получим количество байтов в килобайте. Для получения количества килобайтов в мегабайтах, необходимо число килобайтов поделить на 1024.
Что такое бит байт килобайт?
Как уже можно догадаться, как байт состоит из битов, так и килобайт состоит из байтов. В одном килобайте используется 1024 байта. Чтобы выяснить, почему именно 1024, а не 1000, необходимо окунутся в истоки создания вычислительной техники.
Сколько символов можно закодировать с помощью 1 байта?
Для кодирования одного символа клавиатуры используют 8 бит — один байт. Байт — это наименьшая единица обработки информации. С помощью одного байта можно закодировать 28=256 символов.
Как найти информационный объем?
- Чтобы вычислить информационный объем сообщения надо количество символов умножить на число бит, которое требуется для хранения одного символа …
- Чтобы перевести биты в байты надо число бит поделить на 8. …
- Задача. …
- Задача. …
- Задача.
С++ — На каких платформах есть что-то кроме 8-битного символа?
спросил
Изменено 11 месяцев назад
Просмотрено 25 тысяч раз
Время от времени кто-то из SO указывает, что char (иначе «байт») не обязательно 8 бит.
Кажется, что 8-битный char почти универсален. Я бы подумал, что для основных платформ необходимо иметь 8-битный
char , чтобы обеспечить его жизнеспособность на рынке.
Как сейчас, так и исторически, какие платформы используют char , который не является 8-битным, и почему они должны отличаться от «обычных» 8-битных?
Когда вы пишете код и думаете о кросс-платформенной поддержке (например, для библиотек общего назначения), какое внимание стоит уделять платформам с не8-битной символ ?
В прошлом я сталкивался с некоторыми цифровыми сигнальными процессорами Analog Devices, для которых char — это 16 бит. Я полагаю, что DSP — это немного нишевая архитектура. (С другой стороны, в то время ассемблер с ручным кодированием легко превзошел то, что могли сделать доступные компиляторы C, поэтому у меня не было большого опыта работы с C на этой платформе.)
9
символ также является 16-битным на процессорах DSP Texas Instruments C54x, которые появились, например, в OMAP2.
char . По-моему, я даже слышал о 24-битном DSP, но не могу вспомнить о чем, так что, возможно, мне это показалось. Другое соображение заключается в том, что POSIX требует CHAR_BIT == 8 . Так что, если вы используете POSIX, вы можете это предположить. Если кому-то позже понадобится перенести ваш код на почти реализацию POSIX, так получилось, что у него есть функции, которые вы используете, но другой размер 9.0011 char , это их невезение.
В общем, я думаю, что почти всегда легче обойти проблему, чем думать о ней. Просто введите CHAR_BIT . Если вам нужен точный 8-битный тип, используйте int8_t . Ваш код с шумом не скомпилируется в реализациях, которые его не предоставляют, вместо того, чтобы молча использовать размер, которого вы не ожидали. По крайней мере, если бы я столкнулся со случаем, когда у меня была веская причина предполагать это, я бы утверждал это.
10
Когда вы пишете код и думаете о кросс-платформенной поддержке (например, для библиотек общего назначения), какое внимание стоит уделять платформам с не8-битными символами?
Дело не столько в том, что «стоит задуматься», сколько в игре по правилам. В С++, например, стандарт говорит, что все байты будут иметь «по крайней мере» 8 бит. Если ваш код предполагает, что байты имеют ровно 8 бит, вы нарушаете стандарт.
В С++, например, стандарт говорит, что все байты будут иметь «по крайней мере» 8 бит. Если ваш код предполагает, что байты имеют ровно 8 бит, вы нарушаете стандарт.
Сейчас это может показаться глупым — » конечно все байты имеют 8 бит!», я слышу вы говорите. Но много очень умных людей полагались на предположения, которые не были гарантиями, и тогда все сломалось. История изобилует такими примерами.
Например, большинство Разработчики начала 90-х предполагали, что конкретная временная задержка процессора в режиме бездействия, занимающая фиксированное количество циклов, займет фиксированное количество часов, потому что большинство потребительских процессоров были примерно эквивалентны по мощности.К сожалению, компьютеры очень быстро становились быстрее.Это породило появление коробок с кнопками «Турбо», целью которых, по иронии судьбы, было замедление работы компьютера, чтобы в игры, использующие технику временной задержки, можно было играть с разумной скоростью. 0005
0005
Один комментатор спросил, где в стандарте говорится, что char должен иметь как минимум 8 бит. Он находится в разделе 5.2.4.2.1 . Этот раздел определяет CHAR_BIT , количество битов в наименьшем адресуемом объекте, и имеет значение по умолчанию 8. Он также говорит:
Их определяемые реализацией значения должны быть равны или больше по величине (абсолютное значение) показанным с тем же знаком.
Таким образом, любое число, равное 8 или выше, подходит для замены реализацией на СИМВОЛ_БИТ .
9
Машины с 36-битной архитектурой имеют 9-битные байты. Согласно Википедии, к машинам с 36-битной архитектурой относятся:
- Digital Equipment Corporation PDP-6/10
- ИБМ 701/704/709/7090/7094
- УНИВАК 1103/1103А/1105/1100/2200,
7
Некоторые из которых мне известны:
- DEC PDP-10: переменная, но чаще всего 7-битные символы, упакованные по 5 на 36-битное слово, или же 9-битные символы, по 4 на слово
- Мейнфреймы данных управления (CDC-6400, 6500, 6600, 7600, Cyber 170, Cyber 176 и т.

- Мэйнфреймы Unisys: 9 бит/байт
- Windows CE: просто вообще не поддерживает тип `char` — вместо этого требуется 16-битный wchar_t
11
Не существует полностью переносимого кода. 🙂
Да, могут быть разные размеры в байтах/символах. Да, могут быть реализации C/C++ для платформ с очень необычными значениями CHAR_BIT и UCHAR_MAX . Да, иногда можно написать код, не зависящий от размера символа.
Однако практически любой реальный код не является автономным. Например. возможно, вы пишете код, который отправляет двоичные сообщения в сеть (протокол не важен). Вы можете определить структуры, содержащие необходимые поля. Чем вы должны его сериализовать. Просто бинарное копирование структуры в выходной буфер не переносимо: обычно вы не знаете ни порядка байтов для платформы, ни выравнивания членов структуры, поэтому структура просто хранит данные, но не описывает, как данные должны быть сериализованы .
Хорошо. Вы можете выполнять преобразования порядка байтов и перемещать элементы структуры (например, uint32_t или аналогичные), используя memcpy в буфер. Почему memcpy ? Потому что на многих платформах невозможно записать 32-битные (16-битные, 64-битные — без разницы), когда целевой адрес не выровнен должным образом.
Итак, вы уже много сделали для достижения переносимости.
А теперь последний вопрос. У нас есть буфер. Данные с него отправляются в сеть TCP/IP. Такая сеть предполагает 8-битные байты. Вопрос: какого типа должен быть буфер? Если ваши символы 9-кусочек? Если они 16-битные? 24? Может быть, каждый символ соответствует одному 8-битному байту, отправленному в сеть, и используются только 8 бит? Или, может быть, несколько сетевых байтов упакованы в 24/16/9-битные символы? Это вопрос, и трудно поверить, что есть один ответ, который подходит для всех случаев. Многое зависит от реализации сокета для целевой платформы.
Итак, о чем я. Обычно код можно относительно легко сделать переносимым до определенной степени . Это очень важно сделать, если вы предполагаете использовать код на разных платформах. Однако Повышение переносимости сверх этой меры требует больших усилий и часто дает мало , так как реальный код почти всегда зависит от другого кода (реализация сокета в приведенном выше примере). Я уверен, что примерно для 90% кода возможность работать на платформах с байтами, отличными от 8-битных, почти бесполезна, так как использует среду, привязанную к 8-битной. Просто проверьте размер байта и выполните утверждение времени компиляции. Вам почти наверняка придется многое переписать для очень необычной платформы.
Но если ваш код очень «автономный» — почему бы и нет? Вы можете написать его так, чтобы он допускал разные размеры байтов.
1
Оказывается, IM6100 (то есть PDP-8 на чипе) все еще можно купить со склада. Это 12-битная архитектура.
Это 12-битная архитектура.
Многие микросхемы DSP имеют 16- или 32-битные символы . Например, TI регулярно производит такие чипы.
0
Языки программирования C и C++, например, определяют байт как «адресуемую единицу данных, достаточно большую, чтобы содержать любой элемент базового набора символов среды выполнения» (пункт 3.6 стандарта C). Поскольку целочисленный тип данных C char должен содержать не менее 8 бит (пункт 5.2.4.2.1), байт в C может содержать как минимум 256 различных значений. Различные реализации C и C++ определяют байт как 8, 9, 16, 32 или 36 бит
Цитата из http://en.wikipedia.org/wiki/Byte#History
Насчет других языков не уверен.
http://en.wikipedia.org/wiki/IBM_7030_Stretch#Data_Formats
Определяет байт на этой машине как переменную длину
1
Семейство DEC PDP-8 имело 12-битное слово, хотя для вывода обычно использовался 8-битный ASCII (в основном на телетайпе). Однако существовал также 6-битный символьный код, который позволял кодировать 2 символа в одном 12-битном слове.
Однако существовал также 6-битный символьный код, который позволял кодировать 2 символа в одном 12-битном слове.
Во-первых, символы Юникода длиннее 8 бит. Как упоминалось ранее, спецификация C определяет типы данных по их минимальным размерам. Используйте sizeof и значения в limit.h , если вы хотите опросить свои типы данных и узнать, какой именно размер они имеют для вашей конфигурации и архитектуры.
По этой причине я стараюсь придерживаться типов данных, таких как uint16_t , когда мне нужен тип данных определенной длины в битах.
Редактировать: Извините, я изначально неправильно понял ваш вопрос.
Спецификация C говорит, что объект char «достаточно велик, чтобы хранить любой член набора символов выполнения». limit.h перечисляет минимальный размер 8 бит, но определение оставляет открытым максимальный размер char .
Таким образом, длина символа a не меньше длины самого большого символа из исполняемого набора вашей архитектуры (обычно округляется до ближайшей 8-битной границы). Если ваша архитектура имеет более длинные коды операций, ваш размер
Если ваша архитектура имеет более длинные коды операций, ваш размер char может быть больше.
Исторически длина кода операции платформы x86 составляла один байт, поэтому char изначально было 8-битным значением. Текущие платформы x86 поддерживают коды операций длиннее одного байта, но char имеет длину 8 бит, поскольку это то, к чему приучены программисты (и большие объемы существующего кода x86).
Думая о многоплатформенной поддержке, используйте типы, определенные в stdint.h . Если вы используете (например) uint16_t, вы можете быть уверены, что это значение является 16-битным значением без знака на любой архитектуре, соответствует ли это 16-битное значение char , short , int , или что-то другое. Большая часть тяжелой работы уже проделана людьми, которые написали ваш компилятор/стандартные библиотеки.
Если вам нужно знать точный размер символа , потому что вы выполняете какие-то низкоуровневые аппаратные манипуляции, требующие этого, я обычно использую тип данных, достаточно большой для хранения символа на всех поддерживаемых платформах ( обычно достаточно 16 бит) и запустить значение через процедуру convert_to_machine_char , когда мне нужно точное машинное представление. Таким образом, специфичный для платформы код ограничивается функцией интерфейса, и большую часть времени я могу использовать обычный
Таким образом, специфичный для платформы код ограничивается функцией интерфейса, и большую часть времени я могу использовать обычный uint16_t .
3
какое внимание стоит уделять платформам с не 8-битными символами?
встречаются магические числа напр. при переключении;
с большинством из них можно справиться довольно просто с помощью CHAR_BIT и, например. UCHAR_MAX вместо 8 и 255 (или подобных).
надеюсь, ваша реализация определяет их 🙂
это «общие» проблемы…..
другая косвенная проблема, скажем, у вас есть:
struct xyz {
чар баз;
чар бла;
учар кайф;
}
это может занять (в лучшем случае) 24 бита на одной платформе, но может взять, например. 72 бита в другом месте…..
, если каждый uchar содержал «битовые флаги» и каждый uchar имел только 2 «значащих» бита или флага, которые
вы использовали в настоящее время, и вы только организовали их в 3 символа для «ясности»,
тогда это может быть относительно «более расточительно», например. на платформе с 24-битными учами…..
на платформе с 24-битными учами…..
битовые поля ничего не могут решить, но у них есть другие вещи, на которые стоит обратить внимание для ….
в этом случае всего одно перечисление может быть способом получить «самый маленький» целочисленный размер, который вам действительно нужен….
возможно не реальный пример, но подобные вещи «кусали» меня при портировании/игрании с каким-то кодом…..
просто тот факт, что если uchar в три раза больше как то, что «обычно» ожидается, 100 таких структур могут тратить много памяти на некоторых платформах….. где «обычно» это не имеет большого значения…..
, так что все еще может быть «сломано» или, в этом случае, «очень быстро тратить много памяти» из-за к предположению, что uchar «не очень расточительный» на одной платформе по сравнению с доступной оперативной памятью, чем на другой платформе…..
проблема может быть более заметной, например. для целых чисел или других типов,
например у вас есть некоторая структура, которой нужно 15 бит, поэтому вы вставляете ее в int,
но на какой-то другой платформе int составляет 48 бит или что-то еще. ….
….
«обычно» вы можете разбить его на 2 символа, но, например. с 24-битным uchar вам нужен только один…..
, поэтому перечисление может быть лучшим «общим» решением….
зависит от того, как вы обращаетесь к этим битам 🙂
, поэтому могут быть «ошибки дизайна», которые поднимают голову…. даже если код все еще может работать/работать нормально, независимо от размером с учар или uint…
есть такие вещи, на которые стоит обратить внимание, хотя в вашем коде нет «магических чисел»…
надеюсь, это имеет смысл 🙂
1
Самым странным, что я видел, были компьютеры CDC. 6-битные символы, но с кодировками 65 . [Было также более одного набора символов — вы выбираете кодировку при установке ОС.]
Если слово из 60 заканчивалось 12, 18, 24, 30, 36, 40 или 48 битами нуля, это было символ конца строки (например, '\n' ).
Поскольку 00 (восьмеричный) символ был : в некоторых кодовых наборах, это означало, что BNF, который использовал ::= , был неудобен, если :: попал не в ту колонку. [Это задолго до C++ и других распространенных применений
[Это задолго до C++ и других распространенных применений :: .]
целые числа раньше были 16-битными (pdp11 и т. д.). Переход на 32-битные архитектуры был трудным. Люди становятся лучше: вряд ли кто-то предполагает, что указатель теперь будет помещаться в длинное число (вы не правы?). Или файловые смещения, или временные метки, или…
8-битные символы — это уже какой-то анахронизм. Нам уже нужно 32 бита для хранения всех мировых наборов символов.
4
Серия Univac 1100 имела два режима работы: 6-битные FIELDATA и 9-битный ASCII, упаковывающие 6 или 4 символа соответственно в 36-битные слова. Вы выбираете режим во время выполнения программы (или во время компиляции). Прошло много лет с тех пор, как я действительно работал над ними.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
С++ — Система, в которой 1 байт! = 8 бит?
На этот вопрос уже есть ответы здесь :
На каких платформах есть что-то кроме 8-битного символа? (14 ответов)
Закрыта 8 лет назад.
Все время читаю предложения типа
не полагайтесь на то, что 1 байт имеет размер 8 бит
использовать
CHAR_BITвместо 8 в качестве константы для преобразования между битами и байтами
и так далее. Какие реальные системы существуют сегодня, где это верно?
(Я не уверен, есть ли различия между C и C++ в этом отношении, или это на самом деле не зависит от языка. Пожалуйста, перемаркируйте, если необходимо.) 33-процессорная архитектура
23
На старых машинах коды размером менее 8 бит были довольно распространены, но большинство из них устарели уже много лет. C и C++ предписывают минимум из 8 бит для Однако существуют современные машины (в основном DSP), где наименьший тип больше 8 бит — минимум 12, 14 или даже 16 бит довольно распространен. Windows CE делает примерно то же самое: его наименьший тип (по крайней мере, с компилятором Microsoft) составляет 16 бит. Они делают , а не , однако обрабатывают
8
СЕГОДНЯ в мире C++ на процессорах x86 вполне безопасно полагаться на то, что один байт равен 8 битам. Процессоры, в которых размер слова не является степенью двойки (8, 16, 32, 64), очень редки . ТАК БЫЛО НЕ ВСЕГДА. Центральный процессор Control Data 6600 (и его собратьев) использовал 60-битное слово и мог адресовать только слово за раз. В каком-то смысле «байт» на CDC 6600 составлял 60 бит. Аппаратный указатель байтов DEC-10 работал с байтами произвольного размера. Указатель байта включает размер байта в битах. Я не помню, могут ли байты пересекать границы слов; Я думаю, что они не могли, а это означало, что у вас будет несколько ненужных битов на слово, если размер байта не будет 3, 4, 9 или 18 бит. (В DEC-10 использовалось 36-битное слово.)
4
Если вы не пишете код, который может быть полезен для DSP, вы имеете полное право считать байты 8-битными. Весь мир может не быть VAX (или Intel), но весь мир должен общаться, обмениваться данными, устанавливать общие протоколы и так далее. Мы живем в век Интернета, основанного на протоколах, построенных на октетах, и любой реализации C, где байты не являются октетами, будет очень трудно использовать эти протоколы. Также стоит отметить, что и POSIX, и Windows имеют (и предписывают) 8-битные байты. Это покрывает 100% интересных невстроенных машин, а в наши дни также большую часть встроенных систем без DSP.
12
Из Википедии: Размер байта был сначала
выбираются как кратные существующим
телетайпные коды, особенно
6-битные коды, используемые армией США
(Филдата) и флот. В 1963, до конца
использование несовместимого телетайпа
коды по разным отраслям
правительство США, ASCII, 7-битный код,
был принят в качестве Федерального информационного
Стандарт обработки, делающий 6-битным
байт коммерчески устарели. в
В начале 1960-х AT&T представила цифровую
телефония первая на междугородней магистрали
линии. Они использовали 8-битный µ-закон
кодирование. Эта крупная инвестиция
пообещали сократить расходы на передачу
для 8-битных данных. Использование 8-битных кодов
для цифровой телефонии также вызвало
8-битные «октеты» данных должны быть приняты как
основная единица данных раннего
Интернет.
1
Как средний программист на основных платформах, вы , а не должны слишком беспокоиться о том, что один байт не является 8-битным. Тем не менее, я бы по-прежнему использовал константу (я не знаю ни одной соответствующей платформы, где это не соответствует действительности).
2
Во-первых, количество битов в Во-вторых, есть несколько встроенных платформ, где
8
Я много встраиваю и в настоящее время работаю над кодом DSP с CHAR_BIT из 16
1
В истории существовало множество странных архитектур, в которых не использовались исходные размеры слов, кратные 8. Если вы когда-нибудь столкнетесь с какой-либо из них сегодня, дайте мне знать. Размер байта исторически
зависит от аппаратного обеспечения и не
существуют окончательные стандарты, которые
указать размер. Это может быть полезно иметь в виду, если вы делаете много встроенных вещей. char , по крайней мере, еще в стандарте C89. [Редактировать: например, C90, §5.2.4.2.1 требует CHAR_BIT >= 8 и UCHAR_MAX >= 255. C89 использует другой номер раздела (я считаю, что будет §2. 2.4.2.1) но одинаковое содержание]. Они рассматривают «символ» и «байт» как по существу синонимы [Редактировать: например,
2.4.2.1) но одинаковое содержание]. Они рассматривают «символ» и «байт» как по существу синонимы [Редактировать: например, CHAR_BIT описывается как: «количество битов для наименьшего объекта, который не является битовым полем (байтом)».] char как 16 бит — вместо этого они используют (несоответствующий) подход, просто не поддерживая тип с именем 9.0011 символ вообще. 

CHAR_BIT в своем коде и assert (или лучше static_assert ) в любых местах, где вы полагаетесь на 8-битные байты. Это должно вас обезопасить. char формально не зависит ни от «системы», ни от «машины», хотя эта зависимость обычно подразумевается здравым смыслом. Количество битов в char зависит только от реализации (т.е. от компилятора). Нет проблем с реализацией компилятора, который будет иметь более 8 битов в char для любой «обычной» системы или машины.
sizeof(char) == sizeof(short) == sizeof(int) , каждая из которых имеет 16 бит (точное название этих платформ я не помню). Кроме того, известные машины Cray имели схожие свойства: все эти типы имели 32 бита.
