Расшифровать QR, EAN_13, ISBN, CODE_39 и CODE_128 онлайн
Хотите знать что скрывается под графическими кодами QR, EAN_13, ISBN, CODE_39 и CODE_128
Воспользуйтесь нашим бесплатным онлайн инструментом.
Достаточно загрузить изображения на сервер и получить результат.
 Все просто и бесплатно. Достаточно подключения к сети интернет.
Все просто и бесплатно. Достаточно подключения к сети интернет.
Не имеет значения какая ОС у вас установлена. Также работа приложения доступна с планшета, ноутбука и мобильного телефона.
Ваши данные под защитой. Мы не храним их. Через некоторое время файлы удаляются с сервера.
JPEGsnoop — Утилита расшифровки JPEG файла
JPEGsnoop это свободно распространяемое приложение для Windows, которое изучает и декодирует внутреннюю информацию JPEG и MotionJPEG AVI файлов. Утилиту можно использовать для определения источника JPEG файла, то есть изображения, и соответственно тем самым проверить его подлинность.
Утилиту можно использовать для определения источника JPEG файла, то есть изображения, и соответственно тем самым проверить его подлинность.
Каждое цифровой фото содержит в себе большое количество скрытых данных. Данная программа была создана с целью раскрытия этих деталей, чтобы тех, кто интересуется.
Она позволить определить всевозможные характеристики, которые использовались в цифровом фотоаппарате при фотосъемке (информацию записываемая по стандарту EXIF, IPTC), а также позволяет извлечь данные, которые могут указать на уровень и характер сжатия изображения JPEG, используемого фотоаппарата при сохранении в файл. Каждая цифровая фотокамера определяет уровень сжатия. Разные камеры определяют сжатие по разному, в связи с этим у одних аппаратов сжатие лучше, у других хуже. Имеется введу больше или меньше размер файла.
Что она позволяет сделать?
Одна из последних возможностей в программе это внутренняя база данных, благодаря которой появляется возможность сравнивания снимков с большим количеством подписей сжатия. Можно узнать о том, какой фотоаппарат или какое программное обеспечение использовалось при создании файла. Это полезная функция, которая позволит узнать был ли отредактирован снимок или нет, то есть подделано изображение или нет. Если подпись сжатия говорит о Photoshop, то можно сказать со 100% точностью, что фотография была отредактирована!
Можно узнать о том, какой фотоаппарат или какое программное обеспечение использовалось при создании файла. Это полезная функция, которая позволит узнать был ли отредактирован снимок или нет, то есть подделано изображение или нет. Если подпись сжатия говорит о Photoshop, то можно сказать со 100% точностью, что фотография была отредактирована!
JPEGsnoop сообщает большое количество данных, включая: цветность и яркость, цветность подвыборки, оценивает Качество JPEG настройки, параметры разрешения в формате JPEG, данные записанные по стандарту EXIF и многое другое. Отображается большая часть маркеров JPEG JFIF.
Прочие возможные применения: определение параметров качества, которое использовалось Photoshop.
Как пытаться восстановить или Unformat ваши фотографии?
Если вы заинтересованы в попытке восстановить удаленные / поврежденные фотографии, посмотрите мои новую страницу на восстановления удаленных фотографий .
Поддерживаемые типы файлов
JPEGsnoop откроет и попытаться декодировать любой файл, который имеет встроенное JPEG изображение, например: JPG, THM, AVI, DNG, CRW, CR2, NEF, MOV, PDF.
Обратите внимание, что форматы видеофайлов (например,. AVI и MOV.) Являются контейнеры, которые могут включать видеопотоки, закодированные в одном из самых разнообразных кодеков. JPEGsnoop можно только интерпретировать эту видеозапись, если кодек используется основана на Motion JPEG.
Язык: Английский
Лицензия: GNU GPL v2Протестировано на ОС: Windows 7 x64, Windows 10 x64
Заявлена совместимость с ОС: Windows XP / Vista / 8 / 10
Официальный сайт: www.impulseadventure.com
Перейти в каталог загрузки на github
Внимание, резервная копия обновляется очень редко, так как нужна на случай удаления дистрибутива с официального сайта.
Резервная копия на Google Drive, версия 1.7.5
Похожие материалы:
Распознать почерк врача онлайн по фото – бесплатно, онлайн
Большинство врачей заполняет бланки с рецептами очень неразборчивым почерком, понять который зачастую не в состоянии даже работники аптек. Распознать подобные записи можно с помощью специальных приложений и инструментов, предназначенных для расшифровки почерка в режиме онлайн по фото.
Распознать подобные записи можно с помощью специальных приложений и инструментов, предназначенных для расшифровки почерка в режиме онлайн по фото.
ScreenOCR – простой онлайн-сканер рецептов врачей по фото
ScreenOCR – приложение для мобильных телефонов, работающих под управлением ОС Android. Создано для сканирования документации и расшифровки почерка из фотографий и цифровых изображений. С помощью ScreenOCR можно без труда распознать рукописный текст на двадцати языках. Главные особенности приложения:
- опция автоматического определения;
- экспорт результатов в форматы .pdf и .txt;
- сверка результатов с исходными изображениями/фотографиями;
- история сканирований.
Для того, чтобы распознать почерк врача, необходимо запустить ScreenOCR и нажать на кнопку «Загрузить изображение» или сделать снимок, наведя объектив камеры на нужный участок. Программа отличается широким спектром настроек и наличием встроенного редактора. Бесплатная версия обладает рядом ограничений, стоимость платной подписки – 9,99 $ в месяц.
Простой OCR
Простой OCR имеет сходный функционал с описанным выше приложением, и функционирует на базе «умного» алгоритма, распознающего написанный от руки почерк. Ключевые особенности программы:
- возможность загружать изображения из галереи смартфона;
- высокая точность расшифровки;
- поддержка более 60 языков;
- синхронизация с Google Drive и другими облачными online-сервисами;
- распознавание pdf-документов и конвертирование в различные форматы;
- извлечение номеров телефонов, адресов электронной почты и URL-ссылок;
- опция пакетной обработки данных;
- встроенный экстрактор.
Простой OCR умеет распознавать текст, написанный на поврежденном куске бумаги и с пропущенными символами. Для дешифровки врачебного почерка нужно навести объектив камеры на бланк или лист бумаги и кликнуть по клавише «Screen», после чего снимок автоматически сохранится в галерее мобильного телефона. Делиться результатами можно через Google +, Google Hangouts и другие популярные приложения и мессенджеры.
Единственный минус «Простой OCR» – в том, что программа не сканирует документы и изображения без доступа к сети.
«Сканер текста» – помощник в расшифровке почерка врача
OCR Text Scanner – считается одним из лучших сканеров текста. Существуют разные версии (бесплатная и премиальная), при этом для большинства задач хватает бесплатной. Среди главных особенностей программы:
- высокая скорость считывания информации;
- поддержка более 50 языков;
- опция распознавания рукописного ввода;
- синхронизация с Google Hangouts, Google Keep, Google Drive и Google+.
Для дешифровки с помощью «Сканера текста» нужно выполнить такие действия:
- Запустить приложение, после чего автоматически активируется камера. Здесь можно настроить zoom (масштаб), а также параметры яркости с помощью бегунков, расположенных в нижней части экрана.
- В случае съемки при условиях плохого освещения стоит включить вспышку.
- Если бланк с рецептом врача находится во внутренней памяти смартфона, можно загрузить фотографию из галереи.

После загрузки изображения автоматически запустится функция распознавания почерка. Через несколько секунд на экране отобразится текст в печатном виде. Его можно редактировать и конвертировать в различные форматы.
Text Scanner – сканирование и распознавание любого рукописного текста по фото
Условно бесплатная программа Text Scanner, обладающая довольно высоким рейтингом и большим количеством положительных отзывов. С помощью данного приложения можно без труда расшифровать непонятный врачебный почерк и трудночитаемый текст. Алгоритм работы с Text Scanner выглядит следующим образом:
- После инсталляции потребуется предоставить приложению все нужные разрешения.
- На стартовой странице находятся: клавиша с изображением фотоаппарата (в правой нижней части) и кнопка «Галерея» (в верхней левой части). Первая кнопка предназначена для съемки текста, вторая – для загрузки фотографий из галереи.
- Когда фото будет загружено, можно нажать на клавишу «Crop» для обрезки нужного фрагмента.
 Фото должно содержать только бланк рецепта, выписанный врачом. Обрезка выполняется посредством перетаскивания рамки. В программе есть встроенный набор инструментов, позволяющих поворачивать и редактировать изображения.
Фото должно содержать только бланк рецепта, выписанный врачом. Обрезка выполняется посредством перетаскивания рамки. В программе есть встроенный набор инструментов, позволяющих поворачивать и редактировать изображения.
Остается кликнуть по клавише «Scan» и дождаться результатов дешифровки почерка.
Для того, чтобы распознать почерк врача без регистрации и установки сторонних приложений, можно воспользоваться онлайн-сервисом PDF24 Tools. Данный способ подходит для ноутбуков, компьютеров, планшетов и мобильных телефонов. Алгоритм работы с PDF24 Tools:
- Нужно зайти в любой удобный браузер, перейти по ссылке tools.pdf24.org/ru/ocr-pdf и нажать на кнопку «Выбрать файлы».
- После загрузки фотографии откроется раздел дополнительных опций. Потребуется активировать «Рукописные страницы» и внести коррективы в настройки (по собственному усмотрению). Нажатие на клавишу «Начать OCR» запустит процесс распознавания текста.
Когда процесс распознавания завершится, можно сохранить обработанный документ в PDF-формате.
Заключение
Несмотря на обилие приложений и инструментов, позволяющих распознать особенности почерка врачей в режиме онлайн по фото, не стоит забывать о рисках, касающихся расшифровки. Даже полновесная программа для ПК Fine Reader допускает ошибки при сканировании текста. Поскольку рецепт, выписанный доктором, является важным документом, его неверная интерпретация способна привести к весьма плачевным последствиям.
Почему фото на документы всегда ужасны • Расшифровка эпизода • Arzamas
Содержание второй лекции Альберта Байбурина из курса «Зачем нужны паспорт, ФИО, подпись и фото на документы»Документы создаются бюрократическими инстанциями, но с нашим участием. Человек оставляет в них свои следы, к числу которых относятся фотография и подпись. В этой лекции речь пойдет о фотографии для документов, образцом для которой чаще всего является паспортная фотография.
В этой лекции речь пойдет о фотографии для документов, образцом для которой чаще всего является паспортная фотография.
Специфичность паспортной фотографии вполне осознается, о чем свидетельствуют разговорные клише вроде «Есть фотографии, а есть фотографии на паспорт». Если обычные фотографии делаются главным образом на память, то у паспортной фотографии вполне определенная прагматика: она предназначена для идентификации личности.
В службах, имеющих дело с идентификацией по фотографиям, считается, что для этих целей лучше всего подходят фотографии, на которых человек выглядит по возможности естественно. С этой точки зрения фотографии на документы оказываются менее всего пригодными, поскольку их владельцы, осознанно или нет, прилагают все усилия для того, чтобы выглядеть на них иначе, чем в обычной жизни. Считается, что для фотографии, предназначенной для документов, нужно как минимум принять определенную позу, сделать серьезное выражение лица и замереть, к чему их призывают и фотографы.
Мы провели целый ряд интервью с людьми разного возраста. И вот, по словам одного информанта, женщины 1945 года рождения, «как-то на всех паспортах моих друзей и знакомых, родственников все они выглядят гораздо хуже, чем на самом деле». Больше всего результат поражает самих создателей своего паспортного образа. Так, на одном из форумов можно прочитать: «Кто-нибудь может мне дать толковое объяснение — почему фотографии на паспорт ВСЕГДА получаются уродскими?»
Характерно, что фотографирование без изменения своего облика (то есть его, условно говоря, улучшения) даже не обсуждается — во всяком случае, среди женщин. При этом собственно идентификационные возможности фотографий мало заботят владельцев документов. Предполагается, что эта проблема относится на первой стадии к компетенции фотографа, а затем — тех, кто проверяет паспорт и «устанавливает личность». Забота «оригинала» — выглядеть в соответствии с теми социально значимыми образцами, на которые он или она ориентируются.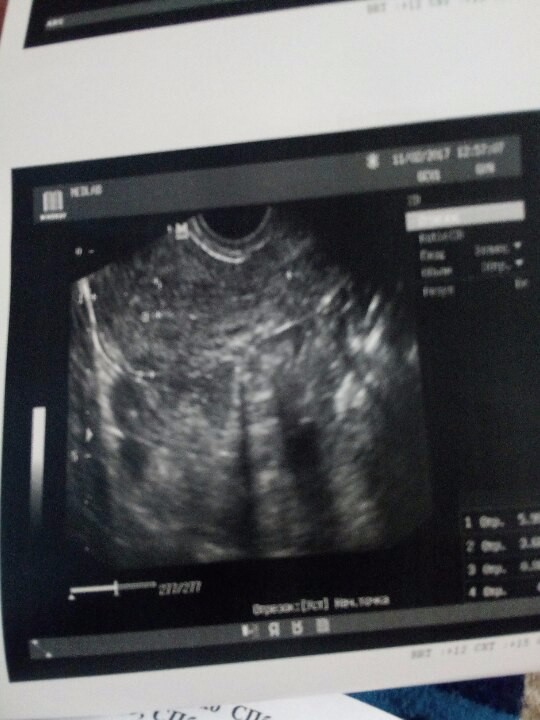 Как сложилась эта своеобразная практика создания особого облика для «главного документа» и каким образом создавался этот «документный другой»?
Как сложилась эта своеобразная практика создания особого облика для «главного документа» и каким образом создавался этот «документный другой»?
Формальных требований к паспортной фотографии, введенной в 1937 году, было совсем немного: она должна быть размером 3 на 3,5 см, четкой и анфас.
Ближайшим аналогом были, видимо, требования к фотографиям объявленных в розыск и осужденных, сформулированные еще в царское время: фотографируемый должен быть без головного убора, волосы не должны закрывать лоб и уши. Однако фотографировать их полагалось не только в фас, но и в профиль, да и размер фотографии был гораздо крупнее.
Так или иначе, отчетливого прототипа советской паспортной фотографии не было, и традиция формировалась практически на пустом месте, особенно если учесть беспрецедентный масштаб нововведения: за два года, 1937-й и 1938-й, сфотографироваться должны были около 50 миллионов человек, и для многих это была первая и единственная фотография.
Отсутствие официальных требований к внешнему виду и правилам фотографирования расценивалось, видимо, как результат недостаточной осведомленности, чреватый возможными неприятностями. Естественно, никто не знал какими, но бюрократическая машина приучила остерегаться малейшего несоблюдения ее предписаний. Следует иметь в виду, что отсутствие необходимой официальной информации — привычное состояние советского человека.
Воображаемый пробел в знаниях компенсировался на ходу создаваемыми неписаными правилами, которым придавался характер полуофициальных инструкций. Вот что рассказывает еще один информант, женщина 1940 года рождения:
«Ну, тогда говорили, что строго должен быть одет, как бы не ярко, не броско… …Ну, я не буду это утверждать, но мне казалось, что сначала же приглашали, заявление писал ты.
И потом, значит, что: надо сфотографироваться. Ну, какие размеры фотографии. И тогда и говорили, что вот одет должен быть вот так. То есть что-то такое, светленький какой-то там воротничок и темненькое платьице такое…»
Даже если этот сюжет придуман информантом, показательно стремление иметь такие правила. Необходимая степень их легитимации достигается тем, что они приписываются официальным лицам, работникам паспортных столов. Но чаще их авторство приписывалось фотографам, которые представлялись носителями необходимых официальных знаний. Женщина 1953 года рождения говорит:
«Ну, фотограф, короче, знает. Ты приходишь в фотографию и говоришь: „Мне на паспорт“. И они делают то, что тебе надо. Если у тебя кофточки нет такой как надо, тебя оденут. Ну, обычно заранее узнавал, что там надо, одеваешь».
Другая женщина 1940 года рождения:
«Ну и, соответственно, когда ты приходил, нам говорили: „Никаких улыбок, это должно быть как бы такое спокойное строгое лицо“».

Из воспоминаний мужчины 1939 года рождения и женщины 1946 года рождения. Мужчина: «По-моему, насколько я тоже помню, была одна фотография. Причем небольшая совершенно, не так, как сейчас вот». Женщина: «Нет, это абсолютно точно. Маленькая одна фотография, вот на всю жизнь, на всю». Действительно, на всю жизнь — даже на могильных памятниках нередко была увеличенная паспортная фотография.
Причем небольшая совершенно, не так, как сейчас вот». Женщина: «Нет, это абсолютно точно. Маленькая одна фотография, вот на всю жизнь, на всю». Действительно, на всю жизнь — даже на могильных памятниках нередко была увеличенная паспортная фотография.
Их не просто помнят, но и подчеркивают особый характер. Как говорит еще одна женщина, 1951 года рождения:
«Ну, в принципе, фотография на паспорт особенная, необычная. Нужно обязательно, чтобы присутствовала светлая блузка и темный пиджак. <…> Там, где я фотографировалась, там даже висел пиджак на всякий пожарный случай, чтобы можно было надеть, если у тебя нет, и сфотографироваться».
Судя по подобным высказываниям, можно подумать, что вся необычность паспортной фотографии заключается в том, что человек фотографируется в другой, не повседневной, более строгой одежде (блузка, темный пиджак), но вместе с тем такая одежда довольно однозначно указывала на парадно-официальный контекст.
Информант: …Раз идешь [фотографироваться] на паспорт, значит, как бы и одета… Ну, не в яркое что-то такое, и выражение лица строгое должно быть, никаких улыбок как бы. Как бы это уже в крови было. Раз паспорт, значит, полный… полный официоз. (Смеется.)
Собиратель: Получается, это заранее человек знает?
Информант: Ну конечно. Да, заранее, потому что паспорт — это всё, соответственно, да, по форме должно быть. Как принято.
Это «как принято» — одна из ключевых формул советского образа жизни, существенной частью которого являются разнообразные практики, связанные с документами.
Любопытно, что если для современной паспортной и особенно визовой фотографии требуется своего рода «обнажение сущности», что предполагает снятие всех «культурных наслоений» (имеются в виду украшения, головные уборы, макияж), то для советской паспортной фотографии важной оказывалась «доработка» своего облика до уровня значимых образцов, в облике которых должны просматриваться такие черты, как скромность, сдержанность, аккуратность и тому подобное./GettyImages-177676958-56a772765f9b58b7d0ea9785.jpg)
Еще один парадокс паспортной фотографии заключается в том, что рассказы о ней крутятся главным образом вокруг одежды (обязательный пиджак, блузка), но ее-то практически и не видно на фотографии. В лучшем случае на крохотной фотографии видны кусочек воротника и одно плечо. Только те информанты, кто не был озабочен тем, чтобы «одеться красиво», и знали особенности паспортной фотографии, отмечали это обстоятельство (преимущественно мужчины).
Сконструированная регламентация распространялась и на выражение лица. Основное требование можно было бы сформулировать как недопущение «избыточной мимики» (ему соответствует требование отсутствия «искажающей мимики» для современного паспорта). Женщина 1967 года рождения:
«Я помню, как я удивилась, когда первый раз увидела иностранный паспорт: у нас же были черно-белые фотографии… а там цветная фотография, человек смеется. Улыбается от уха до уха. Вот эта улыбка меня поразила больше всего.
Потому что, чтоб человек на паспорте улыбался, я никогда в жизни не видела».
Любопытно, что появляющийся в некоторых интервью мотив узнавания имеет особый смысл. По мнению информантов-женщин, достижение эффекта узнавания гарантировано в том случае, если фотография получится красивой, то есть понравится «оригиналу».
В официальном регистре «узнаванию» придается несколько иной смысл, в частности в связи с установленным сроком годности паспорта, основанным на официальных представлениях о сроке накопления изменений, которые меняют облик человека до неузнаваемости. Общая тенденция — увеличение этого срока. Первые паспорта выдавались на три года; по Положению 1940 года — на 5 лет; паспорта образца 1953 года выдавались на 10 лет, после чего подлежали обмену; паспорта образца 1974 года были бессрочными, но по достижении владельцем возраста 25 и 45 лет вклеивались новые фотографии. Получается, что срок возможности узнавания постоянно увеличивался, но это, наверное, не значит, что люди стали меньше меняться. Скорее меняются официальные представления об идентификационных свойствах паспортной фотографии, что выглядит достаточно странно, например, на фоне постоянного уменьшения срока годности визовых фотографий, годность которых прежде действовала в течение года, а сейчас — полгода.
Скорее меняются официальные представления об идентификационных свойствах паспортной фотографии, что выглядит достаточно странно, например, на фоне постоянного уменьшения срока годности визовых фотографий, годность которых прежде действовала в течение года, а сейчас — полгода.
Как видим, паспортная фотография за короткий срок обросла стереотипными представлениями об, условно говоря, «положенной» визуальной презентации себя в официальном публичном пространстве. Эти представления вырабатывались в процессе своего рода диалога с воображаемой сферой официального, в котором человек делегирует «партнеру» ведущую роль, конструируя от его имени правила, которым сам и подчиняется. Получавшаяся в результате фотография обретала черты, позволяющие и сейчас безошибочно узнавать в ней фотографию на паспорт, а сам паспорт описывать через эту фотографию. Как говорится: «Если фотоальбомчик маленький и тоненький, а фотография одна и страшненькая, то это паспорт». С остальными документами примерно та же история.
Правила, об отсутствии которых тосковали советские граждане, появились для современных паспортов. В основном они касаются размеров, но не только. Тем, кто постоянно носит очки, фотографироваться тоже нужно в очках. Ну и главное: «Выражение лица на фотографии должно быть нейтральным: с закрытым ртом и открытыми глазами». Можно сказать, что бюрократия учла некоторые из стихийно выработанных норм и включила их в свой арсенал.
Расшифровка водительского удостоверения нового образца 2021 года
С 2017 года российские автомобилисты могут получить водительское удостоверение нового образца. В статье поговорим о том, чем документ отличается от прав старого образца и представим расшифровку содержащихся в нем данных.
Водительское удостоверение образца 2019 года
Вследствие изменений законодательства в области ПДД, были приняты и утверждены водительские права нового образца. Изменения коснулись не только внешнего вида документа, но и указанных в нем данных:
- Новые водительские удостоверения отвечают международным стандартам, что позволяет использовать их не только в России, но и на территории большинства европейских стран.

- В 2019 году водительское удостоверение изготавливают из прочного пластика, который не реагирует на солнечный ультрафиолет, и надписи на документе не выгорают в течение всего срока действия.
- Улучшена защита от подделки: на удостоверение наносится специальный рисунок на основе сетчатого переплетения тонких линий и сложных узоров. С обратной стороны на поверхность ВУ нанесен штрих-код, содержащий всю информацию о владельце из базы ГИБДД.
Расшифровка информации ВУ
На лицевой стороне прав по-прежнему нанесены фотография и личные данные владельца.
Вверху документа указано его название – водительское удостоверение, в левом верхнем углу — страна, выдавшая ВУ («RUS»), а ниже — цветная фотография владельца без головного убора и солнцезащитных очков.
Справа от фотографии указывается вся информация о владельце документа, взятая из гражданского паспорта водителя, на двух языках – кириллицей и латиницей:
- Место и дата рождения;
- Дата выдачи и срок действия документа;
- Информация о подразделении ГИБДД, выдавшем права;
- Серия и номер ВУ;
- Регион регистрации водителя;
- Доступные категории.

В момент получения документа водитель ставит под фотографией личную подпись.
На оборотной стороне размещена таблица актуальных категорий с отметками об открытых допусках к управлению ТС.
После последних изменений законодательства в водительских правах были добавлены 2 новые категории для управления общественным транспортом. В общей сложности в правах образца 2019 года насчитывается 16 различных категорий.Основные семь категорий ТС обозначаются буквами латинского алфавита, остальные указываются в виде комбинаций этих букв и цифр.
Напротив категорий ТС, к управлению которыми допущен водитель, указывается дата открытия и окончания действия разрешения. Если водителю запрещено получать права на управление ТС определенной категории, то напротив нее ставится надпись ML.
Кроме категорий, на обратной стороне водительского удостоверения могут располагаться другие важные отметки:
- При определенных проблемах со здоровьем, ставится отметка «Медсправка обязательна».
Это значит, что при встрече с инспектором ГИБДД, водитель обязан предъявить ему ВУ и справку, выданную лечебным учреждением.
- В 14 графе указывается общий стаж вождения, сведения о ранее выданном документе и общие ограничения. При наличии проблем со зрением в этой же графе ставится отметка GCL (водитель имеет право управлять машиной только в очках или контактных линзах).
- Также на оборотной стороне документа продублирована серия и номер документа.
Актуальные категории транспортных средств 2019 года
Все транспортные средства делятся на различные категории в зависимости от типа ТС, мощности, количества колес и прочее. Для управления той или иной группой ТС требуются различные знания и навыки. После последних изменений законодательства в водительских правах были добавлены 2 новые категории для управления общественным транспортом.
В общей сложности в правах образца 2019 года насчитывается 16 различных категорий.
Возрастные ограничения по категориям
Чтобы получить право управлять транспортными средствами той или иной категории, нужно не только сдать соответствующий экзамен в ГИБДД, но и соответствовать возрастным требованиям.
Возраст, при достижении которого можно получить права | Категория ТС |
16 лет | M, A1 |
18 лет | A, B1, B, BE, C1, C1E, C, CE |
21 год | Tb, Tm, D1, D1E, D, DE |
Отличия от прав старого образца
Удостоверения старого образца изготавливались из плотной бумаги и ламинировалось. Информация указывалась только кириллицей и не дублировалась буквами латинского алфавита (исключение – ФИО водителя).
В старых ВУ отсутствовал штрих-код с информацией о водителе из базы данных ГИБДД. Кроме того, было ограниченное количество категорий (раньше их было всего 5, вместо 16 в 2019 году).
Отличалась и степень защиты от фальсификации документа: в старых правах использовались только водяные знаки в виде надписи «RUS» и переливающиеся на солнце вкрапленные волокна.
Заключение
В 2019 году водительские права претерпели несколько важных изменений, которые коснулись внешнего вида, объема указываемой информации и уровня защиты документа от подделок. Новые права соответствую международным стандартам, что делает возможным их использование не только в России, но и за рубежом.
Кроме того, на самом удостоверении указана подробная информация об их владельце. А, благодаря штрих-коду, инспектор может быстро зайти в базу данных ГИБДД и получить максимальный объем информации о гражданине.
Копрограмма: что это за исследование?
ВАЖНО!
Информацию из данного раздела нельзя использовать для самодиагностики и самолечения. В случае боли или иного обострения заболевания диагностические исследования должен назначать только лечащий врач. Для постановки диагноза и правильного назначения лечения следует обращаться к Вашему лечащему врачу.
Напоминаем вам, что самостоятельная интерпретация результатов недопустима, приведенная ниже информация носит исключительно справочный характер.
Показания к назначению исследования
Копрограмма – это лабораторное исследование кала, с помощью которого оцениваются его различные характеристики и выявляются некоторые заболевания желудочно-кишечного тракта (ЖКТ), включая воспалительные процессы и дисбактериоз микрофлоры кишечника.
При отсутствии патологий ЖКТ вся пища, которую употребляет человек, проходя через желудочно-кишечный тракт, подвергается интенсивному воздействию желудочного сока, желчи, пищеварительных ферментов и т.д. В результате пищевые продукты расщепляются на простейшие вещества, которые всасываются через слизистую оболочку кишечника в кровь и лимфу. В толстый кишечник попадают непереваренные пищевые остатки, где из них частично всасывается вода. В норме в прямую кишку попадают каловые массы, примерно на 70% состоящие из воды и на 30% из сухих пищевых остатков.
Если нарушается какая-либо функция органов желудочно-кишечного тракта, начинаются сбои в процессе всасывания пищевых продуктов, что отражается на характеристиках кала.
Таким образом, общий анализ кала назначают для диагностики заболеваний органов желудочно-кишечного тракта (патологии печени, желудка, поджелудочной железы, двенадцатиперстной, тонкой и толстой кишки, желчного пузыря и желчевыводящих путей), при подозрении на кишечные инфекции, для оценки результатов терапии заболеваний ЖКТ, в ходе диагностики злокачественных новообразований и генетических патологий, а также для установления непереносимости различных продуктов.Подготовка к процедуре
Подготовка к копрограмме требует соблюдения некоторых рекомендаций, которые позволяют получить корректный результат исследования.
- Исключить прием слабительных, ферментативных препаратов, сорбентов, введение ректальных свечей, масел.
- По возможности сдавать общий анализ кала не ранее, чем через семь дней после окончания приема антибиотиков.

- Ограничить прием лекарственных препаратов и продуктов, способных изменить цвет кала за трое суток до сдачи анализа.
-
Накануне исследования не проводить диагностические процедуры, оказывающие раздражающее действие на анальное отверстие и прямую кишку (клизмы, ректороманоскопию, колоноскопию).
- После рентгенологического исследования желудка и кишечника анализ кала следует сдавать не ранее, чем через двое суток.
- При необходимости выявления скрытых кровотечений желудочно-кишечного тракта необходима 4-5-дневная диета с исключением мяса, рыбы, яиц и зеленых овощей, а также препаратов железа, магния и висмута.
Специальный контейнер для сбора кала вы можете взять в любом медицинском офисе ИНВИТРО или купить в аптеке. Его использование позволит предотвратить загрязнение собираемого биоматериала.
Забор кала можно выполнить самостоятельно в домашних условиях после самостоятельного акта дефекации (а не после клизмы). Для этого лучше использовать медицинское судно или горшок, предварительно тщательно вымытые, или одноразовую пеленку.
Для этого лучше использовать медицинское судно или горшок, предварительно тщательно вымытые, или одноразовую пеленку.
Непосредственно после акта дефекации следует набрать шпателем каловые массы в контейнер, заполнив его примерно на 30%. Важно, чтобы в собираемый биоматериал не попали следы мочи, менструальных выделений или воды из унитаза.
Полученный биоматериал нужно доставить в лабораторию в день сбора, хранить контейнер можно в холодильнике при температуре от +4 до +8°С не более 6-8 часов.
Контейнер для сбора биоматериалаСрок исполнения
До 4 рабочих дней (не включая день взятия биоматериала).
Что может повлиять на результаты
- Несоблюдение рекомендаций по питанию, применение клизмы, выполнение незадолго до сдачи анализа рентгеноскопического или эндоскопического исследования.
- Нарушение правил сбора кала, включающее использование нестерильного контейнера для сбора биоматериала или сбор непосредственно из унитаза, в результате чего в него попали чужеродные микроорганизмы из мочи, выделений половых органов, воды из унитаза и т.
 д.
д. - Несоблюдение условий хранения и транспортировки кала (биоматериал доставлен в лабораторию позже максимально установленного времени с момента сбора).
Если результат копрограммы кажется вам некорректным, анализ лучше сдать еще раз, придерживаясь всех рекомендаций по подготовке и правилам сбора.
Копрограмма, общий анализ кала
Сдать копрограмму вы можете в ближайшем медицинском офисе ИНВИТРО. Список офисов, где принимается биоматериал для лабораторного исследования, представлен в разделе «Адреса». Интерпретация результатов исследования содержит информацию для лечащего врача и не является диагнозом. Информацию из этого раздела нельзя использовать для самодиагностики и самолечения. Точный диагноз ставит врач, используя как результаты данного обследования, так и нужную информацию из других источников: анамнеза, результатов других обследований и т. д.Нормальные значения
| Показатель | Значение |
| Макроскопическое исследование | |
| Консистенция | Плотная |
| Форма | Оформленный |
| Цвет | Коричневый |
| Запах | каловый, нерезкий |
| pH | 6 – 8 |
| Слизь | Отсутствует |
| Кровь | Отсутствует |
| Остатки непереваренной пищи | Отсутствуют |
| Химическое исследование | |
| Реакция на скрытую кровь | Отрицательная |
| Реакция на белок | Отрицательная |
| Реакция на стеркобилин | Положительная |
| Реакция на билирубин | Отрицательная |
| Микроскопическое исследование | |
| Мышечные волокна с исчерченностью | Отсутствуют |
| Мышечные волокна без исчерченности |
ед. |
| Соединительная ткань | Отсутствует |
| Жир нейтральный | Отсутствует |
| Жирные кислоты | Отсутствует |
| Соли жирных кислот | незначительное количество |
| Растительная клетчатка переваренная | ед. в препарате |
| Растительная клетчатка непереваренная | ед. в препарате |
| Крахмал внутриклеточный | Отсутствует |
| Крахмал внеклеточный | Отсутствует |
| Йодофильная флора нормальная | ед. в препарате |
| Йодофильная флора патологическая | Отсутствует |
| Кристаллы | Отсутствуют |
| Слизь | Отсутствует |
| Эпителий цилиндрический | Отсутствует |
| Эпителий плоский | Отсутствует |
| Лейкоциты | Отсутствуют |
| Эритроциты | Отсутствуют |
| Простейшие | Отсутствуют |
| Яйца глистов | Отсутствуют |
| Дрожжевые грибы | Отсутствуют |
Расшифровка показателей
Консистенция
Жидкие каловые массы могут говорить об излишне активной перистальтике кишечника, колите, наличии протозойной инвазии.

Слишком тугие каловые массы свидетельствует об избыточном всасывании жидкости в кишечнике, запорах, обезвоживании организма.
Пенистый кал возникает при недостаточности функции поджелудочной железы или нарушении секреторной функции желудка.
Кашицеобразный кал может говорить о диспепсии, колите или ускоренной эвакуации каловых масс из толстого отдела кишечника.
Форма
Горохообразный кал бывает при геморрое, трещинах ануса, язвах, голоданиях, микседеме (слизистом отеке).
Кал в виде тонкой ленты отмечается при стенозе тонкого отдела кишечника, а также при наличии в нем новообразований.
Цвет
Черный цвет (цвет дегтя) каловым массам может придавать употребление в пищу некоторых продуктов (смородины, аронии, вишни), прием препаратов с висмутом или железом, а также кровотечение в желудке или двенадцатиперстной кишке, цирроз печени.
Красный оттенок появляется при кровотечении в толстом отделе кишечника.
Светло-коричневый цвет кала возникает при печеночной недостаточности или закупорке желчных протоков.
Светло-желтый цвет кала бывает при патологиях поджелудочной железы и вследствие чрезмерного употребления молочных продуктов.
Темно-коричневый цвет говорит об избытке мяса в рационе питания, а также о повышении секреторной функции в толстом отделе кишечника.
Зеленый кал – признак брюшного тифа.
Запах
Гнилостный запах возникает из-за образования в кишечнике сероводорода и говорит о наличии язвенного колита или о распаде тканей, туберкулезе, гнилостной диспепсии.
Кислый запах говорит об усилении процессов брожения.
Зловонный запах свидетельствует о нарушении в работе поджелудочной железы, недостатке желчи, поступающей в кишечник.
Кислотность
Повышение pH наблюдается у грудных детей на искусственном вскармливании, у взрослых — при гнилостной диспепсии, а также при высокой активности кишечной микрофлоры.
Снижение pH происходит в случае нарушения процесса всасывания в тонком отделе кишечника, при чрезмерном употреблении в пищу углеводов, при усилении процессов брожения.
Слизь
Слизь может находиться как на поверхности кала, так и внутри него, обнаруживается при язвенном колите и запорах.
Кровь
Кровь в кале определяется при кровотечениях в ЖКТ, вызванных новообразованиями, полипами, язвами, геморроем, воспалительными процессами.
Избыточное количество бактерий и грибов может стать причиной ложноположительного ответа.
Остатки непереваренной пищи
Непереваренная пища в кале (лиенторея) свидетельствует о нарушении функции поджелудочной железы, хроническом гастрите, ускоренной перистальтике.
Непереваренные пищевые волокна в анализе кала
Белок
Наличие в кале белка говорит о патологиях двенадцатиперстной кишки или желудка, колите, энтерите, геморрое и некоторых других заболеваниях ЖКТ.
Стеркобилин
Отсутствие или значительное уменьшение стеркобилина в кале (реакция на стеркобилин отрицательная) указывает на закупорку желчного протока или резкое снижение функциональной активности печени.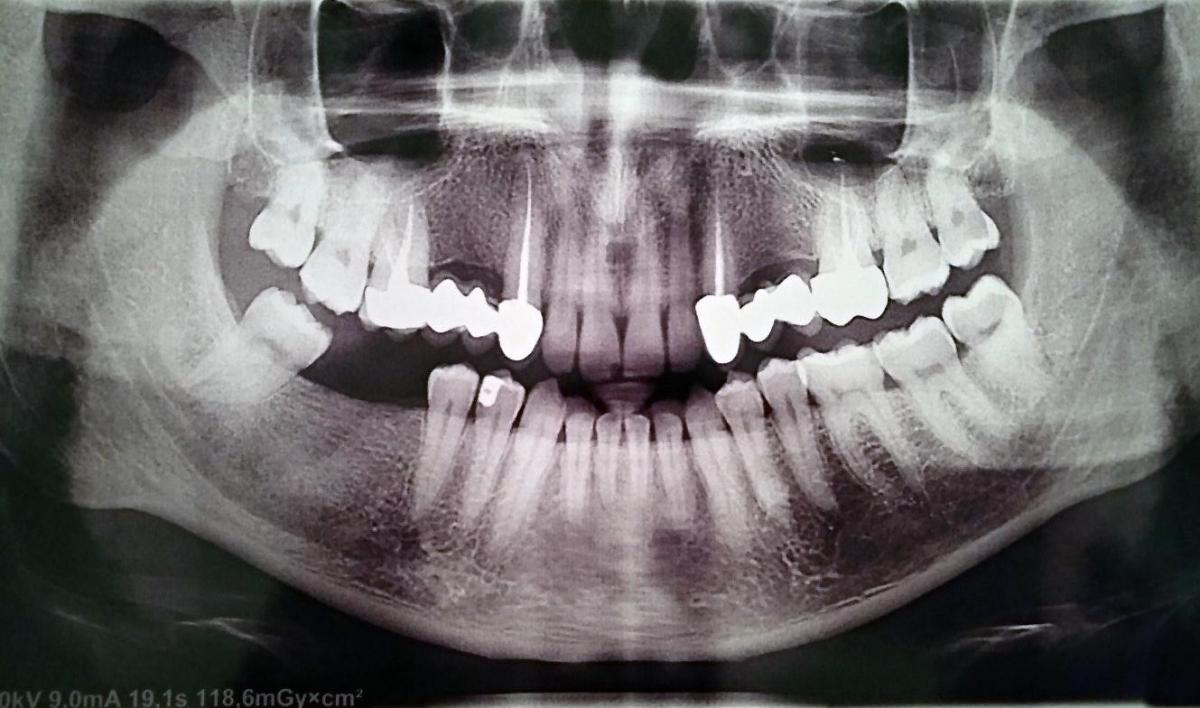 Увеличение количества стеркобилина в каловых массах наблюдается при усиленном желчеотделении, гемолитической желтухе.
Увеличение количества стеркобилина в каловых массах наблюдается при усиленном желчеотделении, гемолитической желтухе.
Билирубин
Обнаружение в кале взрослого человека билирубина указывает на нарушение процесса его восстановления в кишечнике под действием микрофлоры. Это говорит о дисбактериозе кишечника, об усилении перистальтики или о приеме антибактериальных препаратов во время подготовки к сдаче анализа или незадолго до этого.
Соединительная ткань и мышечные волокна
Являются недопереваренными остатками мяса и встречаются при недостатке ферментов поджелудочной железы.
Жир
Жир в кале – один из признаков недостаточной функции поджелудочной железы или нарушения отделения желчи.
Избыточное количество жира в кале (стеаторея)
Растительная клетчатка
Большое количество переваренной растительной клетчатки в кале свидетельствует о быстром прохождении пищи через желудок из-за снижения его секреторной функции, отсутствия в нем соляной кислоты, а также об избыточном количестве бактерий в толстом кишечнике и их проникновении в отделы тонкого кишечника. Непереваренная клетчатка диагностического значения не имеет, так как в ЖКТ нет ферментов для ее расщепления.
Непереваренная клетчатка диагностического значения не имеет, так как в ЖКТ нет ферментов для ее расщепления.
Крахмал
Повышенное содержание крахмала в кале, появляющееся при недостатке процессов переваривания в желудке, тонкой кишке и нарушении функции поджелудочной железы, называется амилореей. Кроме того, много крахмала может обнаруживаться во время диареи.
Внутриклеточные гранулы крахмала в анализе кала
Йодофильная флора (патологическая)
Присутствие патологической микрофлоры (стафилококков, энтерококков, кишечной палочки и пр.) свидетельствует об уменьшении количества полезных бактерий в кишечнике и, соответственно, о дисбактериозе. При потреблении большого количества углеводов начинают усиленно размножаться клостридии, вызывая бродильный дисбиоз.
Кристаллы
Кристаллы оксалата кальция в кале говорят о недостаточности функции желудка, глистных инвазиях, аллергии.
Кристаллы триппельфосфатов свидетельствуют об усиленном гниении белков в толстой кишке.
Эпителий
Значительное количество цилиндрического эпителия в кале обнаруживается при острых и хронических колитах. Наличие клеток плоского эпителия диагностического значения не имеет.
Лейкоциты
Лейкоциты в каловых массах появляются при колитах и энтеритах кишечника, дизентерии, туберкулезе кишечника.
Эритроциты
Эритроциты появляются в каловых массах при геморрое, трещинах прямой кишки, язвенных процессах в толстом отделе кишечника, при распаде опухолей.
Простейшие
Непатогенные простейшие присутствуют у здоровых людей. Патогенных можно обнаружить в каловых массах, доставленных в лабораторию не позднее двух часов после сбора биоматериала. Их наличие говорит об инвазии.
Яйца глистов
Яйца гельминтов в кале указывают на глистную инвазию.
Личинки круглых червей рода Strongyloides в кале
Дрожжевые грибы
Могут присутствовать в кале при проведении терапии кортикостероидами или антибактериальными препаратами. Наличие грибка Candida albicans говорит о поражении кишечника.
Наличие грибка Candida albicans говорит о поражении кишечника.
Источники
- Номенклатура медицинских услуг (новая редакция). Утверждена приказом Министерства здравоохранения и социального развития Российской Федерации от 13 октября 2017 года № 804н. Действует с 01.01.2018. В редакции Приказа Минздрава России от 5 марта 2020 года N 148н (в т.ч. с изменениями вст. в силу 18.04.2020).
- Шакова Х.Х. Оценка достоверности копрологического исследования в зависимости от времени хранения материала. Успехи современного естествознания, журнал. 2003. № 8. С. 131-131.
- Бугеро Н.В., Немова И.С., Потатуркина-Нестерова И.И. Факторы персистенции простейших фекальной флоры при дисбиозе кишечника. Вестник новых медицинских технологий, журнал. Т. XVIII. № 3. С. 28-31.
ВАЖНО!
Информацию из данного раздела нельзя использовать для самодиагностики и самолечения. В случае боли или иного обострения заболевания диагностические исследования должен назначать только лечащий врач. Для постановки диагноза и правильного назначения лечения следует обращаться к Вашему лечащему врачу.
Для постановки диагноза и правильного назначения лечения следует обращаться к Вашему лечащему врачу.
ОКПД Код 74.2 — Услуги в области фотографии, расшифровка
74.20 Услуги в области фотографии
74.20.1 Фотопластинки и фотопленки, кроме кинопленок, экспонированные
74.20.11 Фотопластинки и фотопленки, экспонированные, но не проявленные
74.20.11.000 Фотопластинки и фотопленки, экспонированные, но не проявленные
74.20.12 Фотопластинки и фотопленки, экспонированные и проявленные, для полиграфического воспроизведения
74.20.12.000 Фотопластинки и фотопленки, экспонированные и проявленные, для полиграфического воспроизведения
74.20.19 Прочие фотопластинки и фотопленки, экспонированные и проявленные
74. 20.19.000 Прочие фотопластинки и фотопленки, экспонированные и проявленные
20.19.000 Прочие фотопластинки и фотопленки, экспонированные и проявленные
74.20.2 Услуги специализированные в области фотографии Эта группировка также включает: — услуги фотожурналистов
74.20.21 Услуги портретной фотографии Эта группировка включает: — услуги по изготовлению фотоснимков людей или прочих объектов в студии или в прочих местах, например в офисе или дома у заказчика Как правило, в такие услуги включаются проявление и печать таких фотографий в соответствии с требованиями заказчика: фотографий для паспорта или удостоверения личности, портретов младенцев и детей, семейных или военных портретов, студийных фотографий моделей, корпоративных фотопортретов
74.20.21.000 Услуги в области портретной фотографии
74.20.22 Услуги в области фотографии для рекламы и аналогичных целей Эта группировка включает: — услуги по фотосъемке: товаров, промышленных продуктов, модной и прочей одежды, машин и оборудования, зданий и сооружений, людей и прочих объектов для целей связи с общественностью; — услуги по фотографированию для рекламных витрин, брошюр, газетных объявлений, каталогов
74. 20.22.000 Услуги фотографии для рекламы и аналогичных целей
20.22.000 Услуги фотографии для рекламы и аналогичных целей
74.20.23.000 Услуги в области фото- и видеосъемки событий
74.20.24.000 Услуги в области аэрофотосъемки
74.20.29.000 Услуги специализированные в области фотографии прочие
74.20.3 Услуги в области фотографии прочие
74. 20.31 Услуги по обработке фотоматериалов
Эта группировка включает:
— услуги, состоящие, как правило, в проявлении негативов и печати фотоснимков, предназначенных для других лиц, в соответствии с требованиями заказчика: увеличение негативов или слайдов, черно-белая обработка, печатание цветных снимков;
— изготовление дубликатов слайдов и негативов, их копий и т.п.;
— услуги, состоящие в проявлении фотопленок как для фотографов-любителей, так и для коммерческих заказчиков;
— услуги по подготовке фотографических слайдов;
— услуги по изготовлению копий фотопленок;
— перенос фотоизображений и фотопленок на другие носители
Эта группировка не включает:
— услуги по обработке кинопленок и услуги, связанные с постпроизводством, см. Код ОКПД 59.12.1
20.31 Услуги по обработке фотоматериалов
Эта группировка включает:
— услуги, состоящие, как правило, в проявлении негативов и печати фотоснимков, предназначенных для других лиц, в соответствии с требованиями заказчика: увеличение негативов или слайдов, черно-белая обработка, печатание цветных снимков;
— изготовление дубликатов слайдов и негативов, их копий и т.п.;
— услуги, состоящие в проявлении фотопленок как для фотографов-любителей, так и для коммерческих заказчиков;
— услуги по подготовке фотографических слайдов;
— услуги по изготовлению копий фотопленок;
— перенос фотоизображений и фотопленок на другие носители
Эта группировка не включает:
— услуги по обработке кинопленок и услуги, связанные с постпроизводством, см. Код ОКПД 59.12.1
74.20.31.000 Услуги по обработке фотоматериалов
74.20.32 Услуги по восстановлению и ретушированию фотографий Эта группировка включает: — услуги по восстановлению старых фотографий; — ретуширование и обработку фотоснимков с применением прочих специальных фотографических эффектов
74. 20.32.000 Услуги по восстановлению и ретушированию фотографий
20.32.000 Услуги по восстановлению и ретушированию фотографий
74.20.39.000 Услуги в области фотографии прочие, не включенные в другие группировки
Декодер изображенийBase64 — онлайн-инструмент
Base64Термин Base64 происходит от определенной кодировки передачи содержимого MIME. По сути, Base64 — это набор связанных конструкций кодирования, которые представлять двоичную информацию в формате ASCII путем ее преобразования в представление base64.
Схемы кодирования Base64 обычно используются, когда есть необходимость кодировать двоичную информацию, которую необходимо хранить и передавать над носителями, разработанными для работы с текстовыми Информация.Это гарантирует, что данные остается неизменным без изменений во время передачи. Base64 обычно используется в ряде приложений, включая электронную почту. через MIME и хранение сложной информации в XML.
Конкретный набор символов, выбранный для 64
символы, необходимые для базы, могут различаться в зависимости от реализации. Общая концепция состоит в том, чтобы выбрать набор из 64 символов, который одновременно
часть подмножества, типичного для большинства кодировок. Эта смесь
делает невозможным изменение данных при транспортировке через
информационные системы, такие как электронная почта, обычно не были 8-битными.Реализация Base64 в MIME использует буквы a-z, A-Z и 0-9 для первых 62 значений.
Другие варианты Base64 имеют то же свойство, но используют разные символы.
в последних двух значениях.
Общая концепция состоит в том, чтобы выбрать набор из 64 символов, который одновременно
часть подмножества, типичного для большинства кодировок. Эта смесь
делает невозможным изменение данных при транспортировке через
информационные системы, такие как электронная почта, обычно не были 8-битными.Реализация Base64 в MIME использует буквы a-z, A-Z и 0-9 для первых 62 значений.
Другие варианты Base64 имеют то же свойство, но используют разные символы.
в последних двух значениях.
Таблица индексов Base64:
| Значение | Char | Значение | Char | Значение | Char | Значение | Char | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | А |
16 | Q |
32 | г |
48 | Вт |
|||
| 1 | В |
17 | R |
33 | ч |
49 | х |
|||
| 2 | С |
18 | S |
34 | и |
50 | y |
|||
| 3 | Д |
19 | т |
35 | j |
51 | z |
|||
| 4 | E |
20 | U |
36 | к |
52 | 0 |
|||
| 5 | Ф |
21 | В |
37 | л |
53 | 1 |
|||
| 6 | г |
22 | Вт |
38 | м |
54 | 2 |
|||
| 7 | H |
23 | х |
39 | нет |
55 | 3 |
|||
| 8 | Я |
24 | Y |
40 | или |
56 | 4 |
|||
| 9 | Дж |
25 | Z |
41 | п. |
57 | 5 |
|||
| 10 | К |
26 | а |
42 | q |
58 | 6 |
|||
| 11 | л |
27 | б |
43 | р |
59 | 7 |
|||
| 12 | М |
28 | с |
44 | с |
60 | 8 |
|||
| 13 | N |
29 | г |
45 | т |
61 | 9 |
|||
| 14 | O |
30 | e |
46 | u |
62 | + |
|||
| 15 | п. |
31 | f |
47 | в |
63 | / |


Источник: Base64 в Википедии
Расшифровка изображений в Интернете
Что такое декодирование
Декодирование изображения — это процесс преобразования закодированного изображения обратно в несжатое растровое изображение, которое затем может быть отображено на экране.Это включает в себя этапы, прямо противоположные этапам кодирования изображения. Например, для JPEG это включает следующие шаги: —
- Данные проходят процесс декодирования Хаффмана.
- Затем результат проходит через процесс обратного дискретного косинусного преобразования (IDCT) и деквантования, чтобы вернуть изображение из частотного пространства в цветовое пространство. Применяется
- Chroma Upsampling.
- Наконец, изображение конвертируется из формата YCbCr в RGB.
После того, как изображение декодировано, оно сохраняется браузером во внутреннем кэше. Когда пользователь прокручивает страницу, браузер декодирует необходимые изображения и начинает рисовать на экране. Декодированное изображение может занимать довольно много памяти. Например, простое изображение в формате PNG размером 300×400 (с каналами RGBA) займет 4 * 300 * 400 = 480 000 байтов. И это как раз то место, которое требуется для хранения одного изображения в памяти. Учитывая, что современные веб-страницы могут легко содержать 20 или 30 изображений, это может быстро накапливаться.Здесь браузеры должны делать обычный компромисс между хранением и вычислениями — хранение большего количества изображений в памяти означает, что браузеру не нужно выполнять дорогостоящую операцию декодирования каждый раз, когда его нужно нарисовать на экране, но приводит к более высокому ОЗУ. Применение. Поскольку браузер может повторно декодировать изображение в любое время, он может вернуть эту память обратно операционной системе, когда в ней не хватает памяти.
Когда пользователь прокручивает страницу, браузер декодирует необходимые изображения и начинает рисовать на экране. Декодированное изображение может занимать довольно много памяти. Например, простое изображение в формате PNG размером 300×400 (с каналами RGBA) займет 4 * 300 * 400 = 480 000 байтов. И это как раз то место, которое требуется для хранения одного изображения в памяти. Учитывая, что современные веб-страницы могут легко содержать 20 или 30 изображений, это может быстро накапливаться.Здесь браузеры должны делать обычный компромисс между хранением и вычислениями — хранение большего количества изображений в памяти означает, что браузеру не нужно выполнять дорогостоящую операцию декодирования каждый раз, когда его нужно нарисовать на экране, но приводит к более высокому ОЗУ. Применение. Поскольку браузер может повторно декодировать изображение в любое время, он может вернуть эту память обратно операционной системе, когда в ней не хватает памяти.
Факторы, влияющие на время декодирования
На время декодирования изображения влияют разные аспекты. Конечно, время декодирования будет зависеть от количества ресурсов, доступных браузеру, таких как CPU и RAM . Вот почему декодирование изображения может занять даже несколько сотен мс на мобильных устройствах с ограниченными ресурсами.
Конечно, время декодирования будет зависеть от количества ресурсов, доступных браузеру, таких как CPU и RAM . Вот почему декодирование изображения может занять даже несколько сотен мс на мобильных устройствах с ограниченными ресурсами.
Одним из наиболее важных факторов, влияющих на время декодирования, является размер изображения . Помимо увеличения использования ОЗУ, для декодирования больших изображений также требуется больше времени. Это одна из причин, почему обслуживание правильно масштабированных ресурсов в браузере имеет решающее значение.Правильно масштабированные ресурсы загружаются быстрее из-за меньшего количества байтов, отправляемых по сети, но также браузеру легче декодировать и масштабировать их на устройстве.
Формат изображения также влияет на время декодирования изображения. Такие форматы, как JPEG и PNG, существуют уже очень давно, и для этих форматов доступны очень эффективные декодеры для множества различных архитектур платформ. С другой стороны, более современные форматы, такие как JPEGXR и WebP, не имеют столь же эффективных декодеров.Даже если ваши изображения, закодированные в формате JPEGXR, могут быть меньше, чем JPEG, и загружаться быстрее, если фактический процесс декодирования JPEGXR на клиентском устройстве занимает больше времени, кодирование изображений в этом формате может оказаться не лучшим решением. Это именно то, что Trivago нашел для пользователей своего сайта!
С другой стороны, более современные форматы, такие как JPEGXR и WebP, не имеют столь же эффективных декодеров.Даже если ваши изображения, закодированные в формате JPEGXR, могут быть меньше, чем JPEG, и загружаться быстрее, если фактический процесс декодирования JPEGXR на клиентском устройстве занимает больше времени, кодирование изображений в этом формате может оказаться не лучшим решением. Это именно то, что Trivago нашел для пользователей своего сайта!
Браузеры уже используют графический процессор для декодирования изображений на основе определенного набора эвристик. Графические процессоры уже используются для окончательного рендеринга веб-страницы. С некоторыми форматами, такими как JPEG, браузеры также передают закодированные данные непосредственно на графический процессор.Это также помогает сэкономить память, поскольку графический процессор может хранить данные в формате YCbCr и преобразовывать их только в цветовое пространство RGBA для рендеринга только при необходимости.
Измерение декодирования изображения
Для браузеров, похожих на Chrome, вы можете увидеть, сколько времени тратит браузер на декодирование изображения с помощью инструментов разработчика. Чтобы получить эту информацию, перейдите на вкладку «Производительность» в инструментах разработчика и запишите график. Совет: нажмите CMD + Shift + E (или CRTL + Shift + E), чтобы перезагрузить страницу и начать запись новой временной шкалы, когда страница начнет загружаться.
На моем Mac это показывает, что для декодирования этого соответствующего изображения потребовалось 134 мс. Щелкните событие, чтобы выделить узел DOM, содержащий изображение, соответствующее этому событию декодирования. Вы также можете включить регулирование ЦП, чтобы имитировать, сколько времени займет декодирование изображения на более медленных устройствах.
Вы также можете получить гораздо более подробную информацию на ужасной странице трассировки chrome: //. Убедитесь, что вы выбрали категорию «Рендеринг», когда записываете новую трассу таким образом. Задача, соответствующая декодированию изображения, — это decodeAndScale, которая должна иметь информацию о времени декодирования изображения.
Задача, соответствующая декодированию изображения, — это decodeAndScale, которая должна иметь информацию о времени декодирования изображения.
Вы также можете записать трассировку на различных устройствах и в разных условиях с помощью Webpagetest, а затем импортировать ее в chrome: // tracing. Файл трассировки — это простой массив JSON, который вы также можете писать сценарии для анализа и обработки. Ознакомьтесь с форматом трассировки Chrome, если вы хотите узнать больше о каждом поле в файле трассировки.
Аналогичную информацию о времени декодирования также можно получить из Microsoft Edge, но Firefox и Safari не предоставляют эту информацию в данный момент.
Асинхронное декодирование с использованием атрибута декодирования
Обычно декодирование изображений происходит в основном потоке или в растровом потоке (по крайней мере, в Chrome). Если декодирование изображения занимает много времени, остальные задачи в потоке растеризации задерживаются. Рисование других элементов на экране, например текста, будет отодвинуто назад и приведет к задержке, поскольку браузер не может рисовать со скоростью 60 кадров в секунду. Если декодирование изображения происходит асинхронно, растеризация или основной поток остается свободным для других задач.
Рисование других элементов на экране, например текста, будет отодвинуто назад и приведет к задержке, поскольку браузер не может рисовать со скоростью 60 кадров в секунду. Если декодирование изображения происходит асинхронно, растеризация или основной поток остается свободным для других задач.
Например, на этой демонстрационной странице изображение декодируется синхронно, а временная шкала выглядит следующим образом. Поскольку в этом случае декодирование изображения занимает 167 мс (намного больше, чем бюджет кадра в 16 мс), это приводит к резкому поведению.
В тег изображения добавлен новый атрибут, который позволяет больше влиять на то, как выполняется процесс декодирования в браузерах.
Установив для атрибута декодирования значение async, вы предполагаете, что декодирование изображения можно отложить.Установив для него значение auto или пропустив атрибут, вы позволяете браузеру полностью решить, когда следует выполнять декодирование.
Обратите внимание, что этот атрибут действует только как подсказка для браузера и может по-прежнему выполнять то, что, по его мнению, лучше всего для пользователя, исходя из других факторов.
Например, на этой демонстрационной странице я установил для атрибута декодирования значение async. После установки этого атрибута временная шкала выглядит намного лучше! Растровый поток (или основной поток, если там происходит декодирование) блокирует намного меньше.Теперь изображения декодируются в отдельном потоке (в изображении называется ThreadPoolForegroundWorker).
Предварительное декодирование с помощью .decode ()
На этой странице вы могли заметить мерцание при загрузке изображения с более высоким разрешением. Это потому, что когда запускается событие onload тега изображения, изображение просто загружается и не полностью декодируется. Таким образом, вы видите вспышку экрана, когда браузер декодирует новое изображение перед тем, как нарисовать его на экране.
В тегах изображений Chrome есть новая функция, называемая decode, которая позволяет асинхронно декодировать тег изображения и возвращает обещание, которое разрешается после завершения декодирования.
Таким образом, предыдущий пример можно обновить, чтобы использовать этот API, который предотвратил бы мерцание страницы, так как декодирование полностью завершено до того, как изображение отобразится на экране. Вы можете найти обновленный пример здесь
Будьте в курсе, потому что #perfmatters!
Пожалуйста, включите JavaScript, чтобы просматривать комментарии от Disqus.Понимание и декодирование изображения JPEG с использованием Python
Всем привет! 👋 Сегодня мы собираемся понять алгоритм сжатия JPEG.Многие люди не знают, что JPEG — это не формат, а алгоритм. Изображения JPEG, которые вы видите, в основном находятся в формате JFIF (формат обмена файлами JPEG), который внутренне использует алгоритм сжатия JPEG. К концу этой статьи вы гораздо лучше поймете, как алгоритм JPEG сжимает данные и как вы можете написать собственный код Python для его распаковки. Мы не будем рассматривать все нюансы формата JPEG (например, прогрессивную развертку), а будем рассматривать только базовый формат при написании нашего декодера.
Введение
Зачем писать еще одну статью о JPEG, если в Интернете уже есть сотни статей? Что ж, обычно, когда вы читаете статьи о JPEG, автор просто дает вам подробную информацию о том, как выглядит этот формат. Вы не реализуете код для фактической распаковки и декодирования. Даже если вы пишете код, он будет на C / C ++ и недоступен для широкой группы людей. Я планирую изменить это, показав вам, как базовый декодер JPEG работает с использованием Python 3.Я буду основывать свой декодер на этом лицензионном коде MIT, но буду сильно модифицировать его для повышения читабельности и простоты понимания. Вы можете найти измененный код для этой статьи в моем репозитории GitHub.
Различные части JPEG
Начнем с этого красивого изображения Анж Альбертини. В нем перечислены все различные части простого файла JPEG. Взгляни на это. Мы будем исследовать каждый сегмент. Возможно, вам придется несколько раз ссылаться на это изображение во время чтения этого руководства.
На самом базовом уровне почти каждый двоичный файл содержит пару маркеров (или заголовков). Вы можете думать об этих маркерах как о закладках. Они очень важны для понимания файла и используются такими программами, как file (в Mac / Linux), чтобы сообщить нам подробности о файле. Эти маркеры определяют, где хранится определенная информация в файле. За большинством маркеров следует информация длины для конкретного сегмента маркера.Это говорит нам, какова длина этого конкретного сегмента.
Начало и конец файла
Самый первый маркер, который нас интересует, — это FF D8 . Он говорит нам, что это начало изображения. Если мы его не видим, то можем предположить, что это какой-то другой файл. Другой не менее важный маркер — FF D9 . Он сообщает нам, что мы достигли конца файла изображения. За каждым маркером, кроме FFD0 от до FFD9 и FF01 , сразу же следует спецификатор длины, который даст вам длину этого сегмента маркера. Что касается маркеров начала и конца файла изображения, то каждый из них всегда будет иметь длину два байта.
Что касается маркеров начала и конца файла изображения, то каждый из них всегда будет иметь длину два байта.
На протяжении этого урока мы будем работать с этим изображением:
Давайте напишем код для идентификации этих маркеров.
из struct import unpack
marker_mapping = {
0xffd8: «Начало изображения»,
0xffe0: «Заголовок приложения по умолчанию»,
0xffdb: «Таблица квантования»,
0xffc0: «Начало кадра»,
0xffc4: «Определить таблицу Хаффмана»,
0xffda: «Начало сканирования»,
0xffd9: «Конец изображения»
}
класс JPEG:
def __init __ (self, image_file):
с open (image_file, 'rb') как f:
я.img_data = f.read ()
def decode (сам):
data = self.img_data
в то время как (Истина):
маркер, = распаковать ("> H", данные [0: 2])
печать (marker_mapping.get (маркер))
если маркер == 0xffd8:
данные = данные [2:]
маркер elif == 0xffd9:
вернуть
маркер elif == 0xffda:
данные = данные [-2:]
еще:
lenchunk, = unpack ("> H", данные [2: 4])
данные = данные [2 + lenchunk:]
если len (data) == 0:
перерыв
если __name__ == "__main__":
img = JPEG ('profile. jpg ')
img.decode ()
# ВЫВОД:
# Начало изображения
# Заголовок приложения по умолчанию
# Таблица квантования
# Таблица квантования
# Начало кадра
# Стол Хаффмана
# Стол Хаффмана
# Стол Хаффмана
# Стол Хаффмана
# Начало сканирования
# Конец изображения
jpg ')
img.decode ()
# ВЫВОД:
# Начало изображения
# Заголовок приложения по умолчанию
# Таблица квантования
# Таблица квантования
# Начало кадра
# Стол Хаффмана
# Стол Хаффмана
# Стол Хаффмана
# Стол Хаффмана
# Начало сканирования
# Конец изображения
Мы используем структуру для распаковки байтов данных изображения. > H сообщает struct обрабатывать данные как прямой порядок байтов и тип unsigned short . Данные в формате JPEG хранятся в формате big-endian. Только данные EXIF могут быть с прямым порядком байтов (даже если это необычно).И короткий имеет размер 2, поэтому мы предоставляем unpack два байта из нашего img_data . Вы можете спросить себя, откуда мы узнали, что это короткий . Что ж, мы знаем, что маркеры в JPEG — это 4 шестнадцатеричные цифры: ffd8 . Одна шестнадцатеричная цифра равна 4 битам ( 1 ⁄ 2 байта), поэтому 4 шестнадцатеричных цифры будут равны 2 байтам, а короткая — 2 байтам.
За разделом «Начало сканирования» следуют данные сканирования изображения, длина которых не указана.Это продолжается до тех пор, пока не будет найден маркер «конца файла», поэтому сейчас мы вручную «ищем» маркер EOF всякий раз, когда видим маркер SOC.
Теперь, когда у нас есть базовая структура, давайте продолжим и выясним, что же содержат остальные данные изображения. Сначала мы рассмотрим некоторую необходимую теорию, а затем перейдем к кодированию.
Кодирование JPEG
Сначала я объясню некоторые основные концепции и методы кодирования, используемые JPEG, а затем из этого, естественно, последует декодирование как обратное.По моему опыту, попытка непосредственно понять смысл декодирования немного сложна.
Несмотря на то, что изображение ниже не будет иметь большого значения для вас прямо сейчас, оно даст вам некоторые привязки, за которые можно держаться, пока мы пройдем весь процесс кодирования / декодирования. Он показывает этапы процесса кодирования JPEG: (src)
Цветовое пространство JPEG
Согласно спецификации JPEG (ISO / IEC 10918-6: 2013 (E), раздел 6. 1):
1):
- Изображения, закодированные только с одним компонентом, считаются данными в градациях серого, в которых 0 — черный, а 255 — белый.
- Предполагается, что изображения, закодированные с помощью трех компонентов, являются данными RGB, закодированными как YCbCr, если изображение не содержит сегмент маркера APP14, как указано в 6.5.3, и в этом случае цветовая кодировка рассматривается как RGB или YCbCr в соответствии с данными приложения APP14 сегмент маркера. Связь между RGB и YCbCr определяется, как указано в Рек. ITU-T T.871 | ИСО / МЭК 10918-5.
- Предполагается, что изображения, закодированные с четырьмя компонентами, имеют формат CMYK , где (0,0,0,0) указывает белый цвет, если изображение не содержит сегмент маркера APP14, как указано в 6.5.3, и в этом случае цветовая кодировка рассматривается либо CMYK , либо YCCK в соответствии с данными приложения сегмента маркера APP14. Связь между CMYK и YCCK определяется, как указано в разделе 7.

Большинство реализаций алгоритма JPEG используют яркость и цветность (кодирование YUV) вместо RGB. Это очень полезно в JPEG, поскольку человеческий глаз довольно плохо видит высокочастотные изменения яркости на небольшой площади, поэтому мы можем существенно уменьшить частоту, и человеческий глаз не сможет различить разницу.Результат? Сильно сжатое изображение без видимого снижения качества.
Так же, как каждый пиксель в цветовом пространстве RGB состоит из 3 байтов цветовых данных (красный, зеленый, синий), каждый пиксель в YUV также использует 3 байта, но то, что каждый байт представляет, немного отличается. Компонент Y определяет яркость цвета (также называемую яркостью или яркостью), а компоненты U и V определяют цвет (также известный как цветность). Компонент U относится к количеству синего цвета, а компонент V относится к количеству красного цвета.
Этот цветовой формат был изобретен, когда цветные телевизоры не были широко распространены, и инженеры хотели использовать один формат кодирования изображения как для цветных, так и для черно-белых телевизоров. YUV можно было безопасно отображать на черно-белом телевизоре, если цвет был недоступен. Вы можете узнать больше о его истории в Википедии.
YUV можно было безопасно отображать на черно-белом телевизоре, если цвет был недоступен. Вы можете узнать больше о его истории в Википедии.
Дискретное косинусное преобразование и квантование
JPEG преобразует изображение в блоки размером 8×8 пикселей (называемые MCU или минимальные единицы кодирования), изменяет диапазон значений пикселей так, чтобы они располагались в центре на 0, а затем применяет дискретное косинусное преобразование к каждому блоку, а затем использует квантование для сжатия получившийся блок.Давайте разберемся, что означают все эти термины.
Дискретное косинусное преобразование — это метод преобразования дискретных точек данных в комбинацию косинусоидальных волн. Кажется довольно бесполезным тратить время на преобразование изображения в набор косинусов, но это имеет смысл, когда мы понимаем DCT в сочетании с тем, как работает следующий шаг. В JPEG DCT возьмет блок изображения 8×8 и расскажет нам, как его воспроизвести, используя матрицу косинусных функций 8×8. Подробнее здесь)
Подробнее здесь)
Матрица косинусных функций 8×8 выглядит так:
Мы применяем DCT к каждому компоненту пикселя отдельно.Результатом применения DCT является матрица коэффициентов 8×8, которая сообщает нам, какой вклад каждая функция косинуса (из 64 общих функций) вносит во входную матрицу 8×8. Матрица коэффициентов DCT обычно содержит большие значения в верхнем левом углу матрицы коэффициентов и меньшие значения в нижнем правом углу. Верхний левый угол представляет функцию косинуса самой низкой частоты, а нижний правый угол представляет функцию косинуса самой высокой частоты.
Это говорит нам о том, что большинство изображений содержат огромное количество низкочастотной информации и небольшое количество высокочастотной информации.Если мы установим нижние правые компоненты каждой матрицы DCT на 0, результирующее изображение все равно будет таким же, потому что, как я уже упоминал, люди плохо наблюдают высокочастотные изменения. Это именно то, что мы делаем на следующем шаге.
Нашел замечательное видео на эту тему. Смотрите, если DCT не имеет особого смысла.
Мы все слышали, что JPEG — это алгоритм сжатия с потерями, но пока мы не сделали ничего с потерями. Мы только преобразовали блоки 8×8 компонентов YUV в блоки функций косинуса 8×8 без потери информации.Часть с потерями приходит на этапе квантования.
Квантование — это процесс, в котором мы берем пару значений в определенном диапазоне и превращаем их в дискретное значение. В нашем случае это просто причудливое название для преобразования более высоких частотных коэффициентов в выходной матрице DCT в 0. Когда вы сохраняете изображение в формате JPEG, большинство программ редактирования изображений спрашивают вас, какое сжатие вам нужно. Указанный вами процент влияет на то, сколько применяется квантование и сколько теряется высокочастотная информация. Здесь применяется сжатие с потерями. Если вы потеряете высокочастотную информацию, вы не сможете воссоздать точное исходное изображение из полученного изображения JPEG.
Здесь применяется сжатие с потерями. Если вы потеряете высокочастотную информацию, вы не сможете воссоздать точное исходное изображение из полученного изображения JPEG.
В зависимости от требуемого уровня сжатия используются некоторые общие матрицы квантования (интересный факт: у большинства поставщиков есть патенты на построение таблиц квантования). Мы поэлементно делим матрицу коэффициентов DCT с матрицей квантования, округляем результат до целого числа и получаем квантованную матрицу. Давайте рассмотрим пример.
Если у вас есть эта матрица DCT:
Эта (общая) матрица квантования:
Тогда результирующая квантованная матрица будет такой:
Даже если люди не видят высокочастотную информацию, если удалить слишком много информации из фрагментов изображения 8×8, все изображение будет выглядеть блочно. В этой квантованной матрице самое первое значение называется значением постоянного тока, а остальные значения — значениями переменного тока. Если бы мы взяли значения DC из всех квантованных матриц и сгенерировали новое изображение, мы, по сути, получим миниатюру с разрешением 1/8 от исходного изображения.
Если бы мы взяли значения DC из всех квантованных матриц и сгенерировали новое изображение, мы, по сути, получим миниатюру с разрешением 1/8 от исходного изображения.
Также важно отметить, что, поскольку мы применяем квантование при декодировании, мы должны убедиться, что цвета попадают в диапазон [0,255]. Если они выходят за пределы этого диапазона, нам придется вручную ограничить их этим диапазоном.
Зигзаг
После квантования JPEG использует зигзагообразное кодирование для преобразования матрицы в 1D (img src):
Давайте представим, что у нас есть квантованная матрица:
Результат зигзагообразного кодирования будет следующим:
[15 14 13 12 11 10 9 8 0... 0]
Это кодирование является предпочтительным, потому что большая часть низкочастотной (наиболее важной) информации сохраняется в начале матрицы после квантования, а зигзагообразное кодирование сохраняет все это в начале 1D-матрицы. Это полезно для сжатия, которое происходит на следующем шаге.
Это полезно для сжатия, которое происходит на следующем шаге.
Длина прогона и дельта-кодирование
Кодирование длин серий используется для сжатия повторяющихся данных. В конце зигзагообразного кодирования мы увидели, что большинство одномерных массивов с зигзагообразной кодировкой имеют в конце столько нулей.Кодирование длин серий позволяет нам вернуть все потраченное впустую пространство и использовать меньше байтов для представления всех этих нулей. Представьте, что у вас есть такие данные:
10 10 10 10 10 10 10
Кодирование длин серий преобразует его в:
7 10
Нам удалось успешно сжать 7 байтов данных только до 2 байтов.
Дельта-кодирование — это метод, используемый для представления байта относительно байта перед ним. Это легче понять на примере.Допустим, у вас есть следующие данные:
10 11 12 13 10 9
Вы можете использовать дельта-кодировку, чтобы сохранить это так:
10 1 2 3 0 -1
В JPEG каждое значение DC в матрице коэффициентов DCT кодируется дельта относительно предшествующего ему значения DC. Это означает, что если вы измените самый первый коэффициент DCT вашего изображения, все изображение будет испорчено, но если вы измените первое значение последней матрицы DCT, это повлияет только на очень маленькую часть вашего изображения.Это полезно, потому что первое значение DC в вашем изображении обычно наиболее разнообразно и, применяя дельта-кодирование, мы приближаем остальные значения DC к 0, что приводит к лучшему сжатию на следующем этапе кодирования Хаффмана.
Это означает, что если вы измените самый первый коэффициент DCT вашего изображения, все изображение будет испорчено, но если вы измените первое значение последней матрицы DCT, это повлияет только на очень маленькую часть вашего изображения.Это полезно, потому что первое значение DC в вашем изображении обычно наиболее разнообразно и, применяя дельта-кодирование, мы приближаем остальные значения DC к 0, что приводит к лучшему сжатию на следующем этапе кодирования Хаффмана.
Кодировка Хаффмана
КодированиеХаффмана — это метод сжатия информации без потерь. Хаффман однажды спросил себя: «Какое наименьшее количество битов я могу использовать для хранения произвольного фрагмента текста?». Этот формат кодирования был его ответом.Представьте, что вам нужно сохранить этот текст:
а б в г д
В обычном сценарии каждый символ занимает 1 байт пространства:
а: 01100001
б: 01100010
c: 01100011
d: 01100100
e: 01100101
Это основано на преобразовании ASCII в двоичное. Но что, если бы мы могли придумать собственное отображение?
Но что, если бы мы могли придумать собственное отображение?
# Отображение
000: 01100001
001: 01100010
010: 01100011
100: 01100100
011: 01100101
Теперь мы можем сохранить тот же текст, используя меньшее количество бит:
а: 000
б: 001
c: 010
г: 100
e: 011
Это все хорошо, но что, если мы хотим занимать еще меньше места? Что, если бы мы могли сделать что-то вроде этого:
# Отображение
0: 01100001
1: 01100010
00: 01100011
01: 01100100
10: 01100101
а: 0
б: 1
c: 00
г: 01
e: 10
Кодирование Хаффмана позволяет нам использовать такого рода отображение переменной длины.Он принимает некоторые входные данные, сопоставляет наиболее часто встречающиеся символы с меньшими битовыми шаблонами, а наименее частые символы — с большими битовыми шаблонами и, наконец, организует отображение в двоичное дерево. В формате JPEG мы храним информацию о DCT (дискретном косинусном преобразовании) с использованием кодирования Хаффмана. Помните, я говорил вам, что использование дельта-кодирования для значений DC помогает в кодировании Хаффмана? Надеюсь, теперь вы понимаете почему. После дельта-кодирования мы получаем меньше «символов» для сопоставления, и общий размер нашего дерева Хаффмана уменьшается.
Помните, я говорил вам, что использование дельта-кодирования для значений DC помогает в кодировании Хаффмана? Надеюсь, теперь вы понимаете почему. После дельта-кодирования мы получаем меньше «символов» для сопоставления, и общий размер нашего дерева Хаффмана уменьшается.
У Тома Скотта есть замечательное видео с анимацией о том, как в целом работает кодирование Хаффмана. Посмотрите его, прежде чем двигаться дальше.
JPEG содержит до 4 таблиц Хаффмана, которые хранятся в разделе «Определить таблицу Хаффмана» (начиная с 0xffc4 ). Коэффициенты DCT хранятся в 2 разных таблицах Хаффмана. Один содержит только значения постоянного тока из зигзагообразных таблиц, а другой — значения переменного тока из зигзагообразных таблиц. Это означает, что в нашем декодировании нам придется объединить значения DC и AC из двух отдельных матриц. Информация DCT для канала яркости и цветности хранится отдельно, поэтому у нас есть 2 набора информации DC и 2 набора информации переменного тока, что дает нам в общей сложности 4 таблицы Хаффмана.
Информация DCT для канала яркости и цветности хранится отдельно, поэтому у нас есть 2 набора информации DC и 2 набора информации переменного тока, что дает нам в общей сложности 4 таблицы Хаффмана.
В изображении в градациях серого у нас будет только 2 таблицы Хаффмана (1 для постоянного тока и 1 для переменного тока), потому что нас не волнует цвет. Как вы уже понимаете, у двух изображений могут быть очень разные таблицы Хаффмана, поэтому важно хранить эти таблицы внутри каждого JPEG.
Итак, мы знаем основные детали того, что содержит изображение JPEG.Начнем с расшифровки!
декодирование JPEG
Мы можем разбить декодирование на несколько этапов:
- Извлечь таблицы Хаффмана и декодировать биты
- Извлечь коэффициенты DCT, отменив кодирование длины серии и дельты
- Используйте коэффициенты DCT для объединения косинусных волн и восстановления значений пикселей для каждого блока 8×8
- Преобразование YCbCr в RGB для каждого пикселя
- Показать результирующее изображение RGB
Стандарт JPEG поддерживает 4 формата сжатия:
- Исходный
- Расширенная последовательная
- прогрессивный
- без потерь
Мы собираемся работать со сжатием Baseline и, согласно стандарту, baseline будет содержать ряд блоков 8×8, расположенных рядом друг с другом. Другие форматы сжатия размещают данные немного иначе. Для справки я раскрасил разные сегменты шестнадцатеричного содержимого изображения, которое мы используем. Вот как это выглядит:
Другие форматы сжатия размещают данные немного иначе. Для справки я раскрасил разные сегменты шестнадцатеричного содержимого изображения, которое мы используем. Вот как это выглядит:
Мы уже знаем, что JPEG содержит 4 таблицы Хаффмана. Это последний шаг в процедуре кодирования, поэтому он должен быть первым шагом в процедуре декодирования. Каждый раздел DHT содержит следующую информацию:
| Поле | Размер | Описание |
|---|---|---|
| Идентификатор маркера | 2 байта | 0xff, 0xc4 для идентификации маркера DHT |
| Длина | 2 байта | Определяет длину таблицы Хаффмана |
| HT информация | 1 байт | бит 0..3: номер HT (0..3, иначе ошибка) бит 4: тип HT, 0 = таблица постоянного тока, 1 = таблица переменного тока бит 5..7: не используется, должно быть 0 |
| Количество символов | 16 байт | Количество символов с кодами длиной 1. .16, сумма (n) этих байтов — это общее количество кодов, которое должно быть <= 256 .16, сумма (n) этих байтов — это общее количество кодов, которое должно быть <= 256 |
| Обозначения | n байтов | Таблица, содержащая символы в порядке увеличения длины кода (n = общее количество кодов). |
Предположим, у вас есть таблица DH, подобная этой (src):
| Обозначение | код Хаффмана | Длина кода |
|---|---|---|
| а | 00 | 2 |
| б | 010 | 3 |
| с | 011 | 3 |
| г | 100 | 3 |
| e | 101 | 3 |
| f | 110 | 3 |
| г | 1110 | 4 |
| ч | 11110 | 5 |
| i | 111110 | 6 |
| j | 1111110 | 7 |
| к | 11111110 | 8 |
| л | 111111110 | 9 |
Он будет храниться в файле JFIF примерно так (они будут храниться в двоичном формате. Я использую ASCII только для иллюстрации):
Я использую ASCII только для иллюстрации):
0 1 5 1 1 1 1 1 1 0 0 0 0 0 0 0 а б в г д е е ж з и к л
0 означает, что не существует кода Хаффмана длины 1. 1 означает, что существует 1 код Хаффмана длины 2. И так далее. В разделе DHT всегда есть 16 байтов данных длины сразу после информации о классе и идентификаторе. Давайте напишем код для извлечения длин и элементов в DHT.
класс JPEG:
# ...
def decodeHuffman (себя, данные):
смещение = 0
заголовок, = распаковать ("B", данные [смещение: смещение + 1])
смещение + = 1
# Извлекаем 16 байтов, содержащих данные о длине
lengths = unpack ("BBBBBBBBBBBBBBBB", данные [смещение: смещение + 16])
смещение + = 16
# Извлечь элементы после начальных 16 байтов
elements = []
для длины i:
elements + = (unpack ("B" * i, data [offset: offset + i]))
смещение + = я
print ("Заголовок:", заголовок)
print ("длина:", длина)
print ("Элементы:", len (элементы))
data = data [смещение:]
def decode (сам):
данные = себя. img_data
в то время как (Истина):
# ---
еще:
len_chunk, = unpack ("> H", данные [2: 4])
len_chunk + = 2
кусок = данные [4: len_chunk]
если маркер == 0xffc4:
self.decodeHuffman (кусок)
data = данные [len_chunk:]
если len (data) == 0:
перерыв
img_data
в то время как (Истина):
# ---
еще:
len_chunk, = unpack ("> H", данные [2: 4])
len_chunk + = 2
кусок = данные [4: len_chunk]
если маркер == 0xffc4:
self.decodeHuffman (кусок)
data = данные [len_chunk:]
если len (data) == 0:
перерыв
Если вы запустите код, он должен выдать следующий результат:
Начало изображения
Заголовок приложения по умолчанию
Таблица квантования
Таблица квантования
Начало кадра
Стол Хаффмана
Заголовок: 0
длины: (0, 2, 2, 3, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0)
Элементов: 10
Стол Хаффмана
Заголовок: 16
длины: (0, 2, 1, 3, 2, 4, 5, 2, 4, 4, 3, 4, 8, 5, 5, 1)
Элементов: 53
Стол Хаффмана
Заголовок: 1
длины: (0, 2, 3, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
Элементов: 8
Стол Хаффмана
Заголовок: 17
длины: (0, 2, 2, 2, 2, 2, 1, 3, 3, 1, 7, 4, 2, 3, 0, 0)
Элементов: 34
Начало сканирования
Конец изображения
Sweet! У нас есть длина и элементы. Теперь нам нужно создать собственный класс таблицы Хаффмана, чтобы мы могли воссоздать двоичное дерево из этих элементов и длин. Я бессовестно копирую отсюда этот код:
Теперь нам нужно создать собственный класс таблицы Хаффмана, чтобы мы могли воссоздать двоичное дерево из этих элементов и длин. Я бессовестно копирую отсюда этот код:
класс Хаффмана Таблица:
def __init __ (сам):
self.root = []
self.elements = []
def BitsFromLengths (self, root, element, pos):
если isinstance (корень, список):
если pos == 0:
если len (корень) <2:
root.append (элемент)
вернуть True
return False
для i в [0,1]:
если len (root) == i:
корень.добавить ([])
если self.BitsFromLengths (root [i], element, pos-1) == True:
вернуть True
return False
def GetHuffmanBits (self, lengths, elements):
self.elements = элементы
ii = 0
для i в диапазоне (len (длина)):
для j в диапазоне (lengths [i]):
self. BitsFromLengths (self.root, elements [ii], i)
ii + = 1
def Найти (self, st):
r = self.root
в то время как isinstance (r, list):
r = r [ст.GetBit ()]
вернуть г
def GetCode (self, st):
в то время как (Истина):
res = self.Find (st)
если res == 0:
возврат 0
elif (res! = -1):
вернуть res
класс JPEG:
# -----
def decodeHuffman (себя, данные):
# ----
hf = Таблица Хаффмана ()
hf.GetHuffmanBits (длины, элементы)
data = data [смещение:]
BitsFromLengths (self.root, elements [ii], i)
ii + = 1
def Найти (self, st):
r = self.root
в то время как isinstance (r, list):
r = r [ст.GetBit ()]
вернуть г
def GetCode (self, st):
в то время как (Истина):
res = self.Find (st)
если res == 0:
возврат 0
elif (res! = -1):
вернуть res
класс JPEG:
# -----
def decodeHuffman (себя, данные):
# ----
hf = Таблица Хаффмана ()
hf.GetHuffmanBits (длины, элементы)
data = data [смещение:]
GetHuffmanBits принимает длину и элементы, выполняет итерацию по всем элементам и помещает их в корневой список .Этот список содержит вложенные списки и представляет собой двоичное дерево. Вы можете прочитать в Интернете, как работает дерево Хаффмана и как создать свою собственную структуру данных дерева Хаффмана в Python. Для нашего первого DHT (используя изображение, которое я связал в начале этого урока) у нас есть следующие данные, длина и элементы:
Для нашего первого DHT (используя изображение, которое я связал в начале этого урока) у нас есть следующие данные, длина и элементы:
Шестнадцатеричные данные: 00 02 02 03 01 01 01 00 00 00 00 00 00 00 00 00
Длина: (0, 2, 2, 3, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0)
Элементы: [5, 6, 3, 4, 2, 7, 8, 1, 0, 9]
После вызова GetHuffmanBits по этому поводу корневой список будет содержать следующие данные:
[[5, 6], [[3, 4], [[2, 7], [8, [1, [0, [9]]]]]]]
Таблица Хаффмана также содержит метод GetCode , который проходит за нас по дереву и возвращает нам декодированные биты с использованием таблицы Хаффмана.Этот метод ожидает на входе битовый поток. Битовый поток — это просто двоичное представление данных. Например, типичный битовый поток abc будет 011000010110001001100011 . Сначала мы конвертируем каждый символ в его код ASCII, а затем конвертируем этот код ASCII в двоичный. Давайте создадим собственный класс, который позволит нам преобразовывать строку в биты и читать биты один за другим. Вот как мы это реализуем:
Давайте создадим собственный класс, который позволит нам преобразовывать строку в биты и читать биты один за другим. Вот как мы это реализуем:
класс Stream:
def __init __ (себя, данные):
я.данные = данные
self.pos = 0
def GetBit (сам):
b = self.data [self.pos >> 3]
s = 7- (self.pos & 0x7)
self.pos + = 1
возврат (b >> s) & 1
def GetBitN (self, l):
val = 0
для i в диапазоне (l):
val = val * 2 + self.GetBit ()
вернуть val
Мы передаем этому классу некоторые двоичные данные во время его инициализации, а затем используем методы GetBit и GetBitN для их чтения.
Декодирование таблицы квантования
Раздел «Определить таблицу квантования» содержит следующие данные:
| Поле | Размер | Описание |
|---|---|---|
| Идентификатор маркера | 2 байта | 0xff, 0xdb идентифицирует DQT |
| Длина | 2 байта | Это дает длину QT. |
| Информация QT | 1 байт | бит 0..3: номер QT (0..3, иначе ошибка) бит 4..7: точность QT, 0 = 8 бит, иначе 16 бит |
| байта | n байтов | Это дает значения QT, n = 64 * (точность + 1) |
Согласно стандарту JPEG, в изображении JPEG есть 2 таблицы квантования по умолчанию. Один для яркости и один для цветности. Эти таблицы начинаются с маркера 0xffdb .В исходном коде, который мы написали, мы уже видели, что результат содержал два маркера 0xffdb . Давайте расширим код, который у нас уже есть, и добавим возможность декодировать таблицы квантования:
def GetArray (тип, l, длина):
s = ""
для i в диапазоне (длина):
s = s + тип
список возврата (unpack (s, l [: length]))
класс JPEG:
# ------
def __init __ (self, image_file):
self.huffman_tables = {}
self.quant = {}
с open (image_file, 'rb') как f:
я. img_data = f.read ()
def DefineQuantizationTables (self, data):
hdr, = unpack ("B", данные [0: 1])
self.quant [hdr] = GetArray ("B", данные [1: 1 + 64], 64)
данные = данные [65:]
def decodeHuffman (себя, данные):
# ------
для длины i:
elements + = (GetArray ("B", data [off: off + i], i))
смещение + = я
# ------
def decode (сам):
# ------
в то время как (Истина):
# ----
еще:
# -----
если маркер == 0xffc4:
я.decodeHuffman (чанк)
маркер elif == 0xffdb:
self.DefineQuantizationTables (блок)
data = данные [len_chunk:]
если len (data) == 0:
перерыв
img_data = f.read ()
def DefineQuantizationTables (self, data):
hdr, = unpack ("B", данные [0: 1])
self.quant [hdr] = GetArray ("B", данные [1: 1 + 64], 64)
данные = данные [65:]
def decodeHuffman (себя, данные):
# ------
для длины i:
elements + = (GetArray ("B", data [off: off + i], i))
смещение + = я
# ------
def decode (сам):
# ------
в то время как (Истина):
# ----
еще:
# -----
если маркер == 0xffc4:
я.decodeHuffman (чанк)
маркер elif == 0xffdb:
self.DefineQuantizationTables (блок)
data = данные [len_chunk:]
если len (data) == 0:
перерыв
Мы сделали здесь пару вещей. Сначала я определил метод GetArray . Это просто удобный метод для декодирования переменного количества байтов из двоичных данных. Я заменил код в методе
Я заменил код в методе decodeHuffman , чтобы использовать эту новую функцию.После этого я определил метод DefineQuantizationTables . Этот метод просто считывает заголовок раздела таблицы квантования, а затем добавляет данные квантования в словарь со значением заголовка в качестве ключа. Значение заголовка будет 0 для яркости и 1 для цветности. Каждый раздел таблицы квантования в JFIF содержит 64 байта данных QT (для нашей матрицы квантования 8×8).
Если мы напечатаем матрицы квантования для нашего изображения. Они будут выглядеть так:
3 2 2 3 2 2 3 3
3 3 4 3 3 4 5 8
5 5 4 4 5 10 7 7
6 8 12 10 12 12 11 10
11 11 13 14 18 16 13 14
17 14 11 11 16 22 16 17
19 20 21 21 21 12 15 23
24 22 20 24 18 20 21 20
3 2 2 3 2 2 3 3
3 2 2 3 2 2 3 3
3 3 4 3 3 4 5 8
5 5 4 4 5 10 7 7
6 8 12 10 12 12 11 10
11 11 13 14 18 16 13 14
17 14 11 11 16 22 16 17
19 20 21 21 21 12 15 23
24 22 20 24 18 20 21 20
Декодирование начала кадра
Раздел «Начало кадра» содержит следующую информацию (src):
| Поле | Размер | Описание |
|---|---|---|
| Идентификатор маркера | 2 байта | 0xff, 0xc0 для идентификации маркера SOF0 |
| Длина | 2 байта | Это значение равно 8 + компоненты * 3 значение |
| Точность данных | 1 байт | Это бит / отсчет, обычно 8 (12 и 16 не поддерживаются большинством программ). |
| Высота изображения | 2 байта | Это должно быть> 0 |
| Ширина изображения | 2 байта | Это должно быть> 0 |
| Количество деталей | 1 байт | Обычно 1 = шкала серого, 3 = цвет YcbCr или YIQ |
| Каждый компонент | 3 байта | Прочитать 3 байта данных каждого компонента. Он содержит (компонент Id (1 байт) (1 = Y, 2 = Cb, 3 = Cr, 4 = I, 5 = Q), коэффициенты выборки (1 байт) (биты 0-3 по вертикали., 4-7 горизонт.), Номер таблицы квантования (1 байт)). |
Из этих данных нас интересует лишь несколько вещей. Мы извлечем ширину и высоту изображения, а также номер таблицы квантования каждого компонента. Ширина и высота будут использоваться, когда мы начнем декодирование фактических сканированных изображений из раздела «Начало сканирования». Поскольку мы собираемся в основном работать с изображением YCbCr, мы можем ожидать, что количество компонентов будет равно 3, а типы компонентов будут равны 1, 2 и 3 соответственно. Напишем код для декодирования этих данных:
Напишем код для декодирования этих данных:
класс JPEG:
def __init __ (self, image_file):
self.huffman_tables = {}
self.quant = {}
self.quantMapping = []
с open (image_file, 'rb') как f:
self.img_data = f.read ()
# ----
def BaselineDCT (self, data):
hdr, self.height, self.width, components = unpack ("> BHHB", data [0: 6])
print ("size% ix% i"% (self.width, self.height))
для i в диапазоне (компоненты):
id, samp, QtbId = unpack ("BBB", data [6 + i * 3: 9 + i * 3])
я.QuantMapping.append (QtbId)
def decode (сам):
# ----
в то время как (Истина):
# -----
маркер elif == 0xffdb:
self.DefineQuantizationTables (блок)
маркер elif == 0xffc0:
self.BaselineDCT (чанк)
data = данные [len_chunk:]
если len (data) == 0:
перерыв
Мы добавили атрибут списка QuantMapping в наш класс JPEG и представили метод BaselineDCT . Метод
Метод BaselineDCT декодирует необходимые данные из раздела SOF и помещает номера таблиц квантования каждого компонента в список QuantMapping . Мы воспользуемся этим отображением, когда начнем читать раздел «Начало сканирования». Вот как выглядит QuantMapping для нашего изображения:
Количественное сопоставление: [0, 1, 1]
Декодирование Начало сканирования
Sweet! Нам осталось декодировать только один раздел. Это основа изображения в формате JPEG и содержит фактические данные «изображения».Это также самый сложный шаг. Все остальное, что мы декодировали до сих пор, можно рассматривать как создание карты, которая помогает нам ориентироваться и декодировать реальное изображение. Этот раздел содержит само изображение (хотя и в закодированном виде). Мы прочитаем этот раздел и воспользуемся данными, которые мы уже декодировали, чтобы разобраться в изображении.
Все маркеры, которые мы видели до сих пор, начинаются с 0xff .
0xff также может быть частью данных сканирования изображения, но если 0xff присутствует в данных сканирования, он всегда будет выполняться с помощью 0x00 .Это то, что кодировщик JPEG делает автоматически и называется байтовым заполнением. Обязанность декодера — удалить эту обработку 0x00 . Давайте запустим метод SOS-декодера с этой функции и избавимся от 0x00 , если он присутствует. В примере изображения, который я использую, в данных сканирования изображения нет 0xff , но это, тем не менее, полезное дополнение.
def RemoveFF00 (данные):
datapro = []
я = 0
в то время как (Истина):
b, bnext = unpack ("BB", data [i: i + 2])
если (b == 0xff):
если (bnext! = 0):
перерыв
датапро.добавить (данные [i])
я + = 2
еще:
datapro.append (данные [i])
я + = 1
вернуть datapro, я
класс JPEG:
# ----
def StartOfScan (self, data, hdrlen):
данные, lenchunk = RemoveFF00 (данные [hdrlen:])
вернуть lenchunk + hdrlen
def decode (сам):
data = self. img_data
в то время как (Истина):
маркер, = распаковать ("> H", данные [0: 2])
печать (marker_mapping.get (маркер))
если маркер == 0xffd8:
данные = данные [2:]
маркер elif == 0xffd9:
вернуть
еще:
len_chunk, = unpack ("> H", данные [2: 4])
len_chunk + = 2
кусок = данные [4: len_chunk]
если маркер == 0xffc4:
я.decodeHuffman (чанк)
маркер elif == 0xffdb:
self.DefineQuantizationTables (блок)
маркер elif == 0xffc0:
self.BaselineDCT (чанк)
маркер elif == 0xffda:
len_chunk = self.StartOfScan (данные, len_chunk)
data = данные [len_chunk:]
если len (data) == 0:
перерыв
img_data
в то время как (Истина):
маркер, = распаковать ("> H", данные [0: 2])
печать (marker_mapping.get (маркер))
если маркер == 0xffd8:
данные = данные [2:]
маркер elif == 0xffd9:
вернуть
еще:
len_chunk, = unpack ("> H", данные [2: 4])
len_chunk + = 2
кусок = данные [4: len_chunk]
если маркер == 0xffc4:
я.decodeHuffman (чанк)
маркер elif == 0xffdb:
self.DefineQuantizationTables (блок)
маркер elif == 0xffc0:
self.BaselineDCT (чанк)
маркер elif == 0xffda:
len_chunk = self.StartOfScan (данные, len_chunk)
data = данные [len_chunk:]
если len (data) == 0:
перерыв
Раньше я вручную пытался добраться до конца файла всякий раз, когда встречал маркер 0xffda , но теперь, когда у нас есть необходимые инструменты для систематического просмотра всего файла, я переместил условие маркера внутрь else Пункт .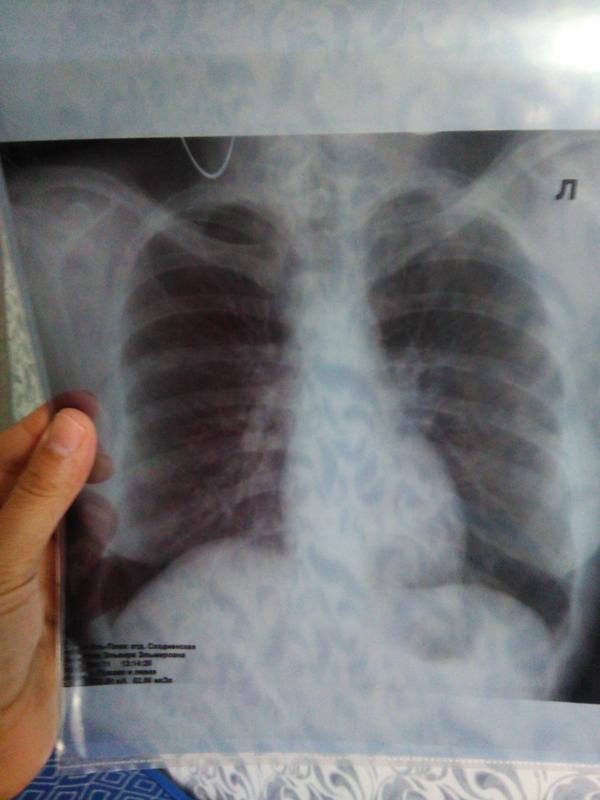 Функция
Функция RemoveFF00 просто прерывается всякий раз, когда она наблюдает за чем-то, кроме 0x00 после 0xff . Следовательно, он выйдет из цикла при обнаружении 0xffd9 , и таким образом мы сможем безопасно перейти к концу файла без каких-либо сюрпризов. Если вы запустите этот код сейчас, на терминал не будет выводиться ничего нового.
Напомним, что JPEG разбил изображение на матрицу 8×8. Следующим шагом для нас является преобразование данных сканирования изображения в битовый поток и обработка потока блоками данных 8×8.Давайте добавим еще немного кода в наш класс:
класс JPEG:
# -----
def StartOfScan (self, data, hdrlen):
данные, lenchunk = RemoveFF00 (данные [hdrlen:])
st = поток (данные)
oldlumdccoeff, oldCbdccoeff, oldCrdccoeff = 0, 0, 0
для y в диапазоне (self.height // 8):
для x в диапазоне (self.width // 8):
matL, oldlumdccoeff = self. BuildMatrix (st, 0, self.quant [self.quantMapping [0]], oldlumdccoeff)
matCr, oldCrdccoeff = self.BuildMatrix (st, 1, self.квант [self.quantMapping [1]], oldCrdccoeff)
matCb, oldCbdccoeff = self.BuildMatrix (st, 1, self.quant [self.quantMapping [2]], oldCbdccoeff)
DrawMatrix (x, y, matL.base, matCb.base, matCr.base)
вернуть lenchunk + hdrlen
BuildMatrix (st, 0, self.quant [self.quantMapping [0]], oldlumdccoeff)
matCr, oldCrdccoeff = self.BuildMatrix (st, 1, self.квант [self.quantMapping [1]], oldCrdccoeff)
matCb, oldCbdccoeff = self.BuildMatrix (st, 1, self.quant [self.quantMapping [2]], oldCbdccoeff)
DrawMatrix (x, y, matL.base, matCb.base, matCr.base)
вернуть lenchunk + hdrlen
Мы начинаем с преобразования наших данных сканирования в битовый поток. Затем мы инициализируем oldlumdccoeff , oldCbdccoeff , oldCrdccoeff до 0. Это необходимо, потому что помните, мы говорили о том, как элемент DC в матрице квантования (первый элемент матрицы) кодируется дельта относительно предыдущего элемента DC. ? Это поможет нам отслеживать значение предыдущих элементов DC, и 0 будет значением по умолчанию, когда мы встретим первый элемент DC.
Цикл для может показаться немного странным. self. говорит нам, сколько раз мы можем разделить высоту на 8. То же самое касается  height // 8
height // 8 self.width // 8 . Это вкратце говорит нам, на сколько матриц 8×8 разделено изображение.
BuildMatrix примет таблицу квантования и некоторые дополнительные параметры, создаст матрицу обратного дискретного косинусного преобразования и выдаст нам матрицы Y, Cr и Cb. Фактическое преобразование этих матриц в RGB будет происходить в функции DrawMatrix .
Давайте сначала создадим наш класс IDCT, а затем мы можем приступить к конкретизации метода BuildMatrix .
импорт математики
класс IDCT:
"" "
Класс обратного дискретного косинусного преобразования
"" "
def __init __ (сам):
self.base = [0] * 64
self.zigzag = [
[0, 1, 5, 6, 14, 15, 27, 28],
[2, 4, 7, 13, 16, 26, 29, 42],
[3, 8, 12, 17, 25, 30, 41, 43],
[9, 11, 18, 24, 31, 40, 44, 53],
[10, 19, 23, 32, 39, 45, 52, 54],
[20, 22, 33, 38, 46, 51, 55, 60],
[21, 34, 37, 47, 50, 56, 59, 61],
[35, 36, 48, 49, 57, 58, 62, 63],
]
я. idct_precision = 8
self.idct_table = [
[
(self.NormCoeff (u) * math.cos (((2.0 * x + 1.0) * u * math.pi) / 16.0))
для x в диапазоне (self.idct_precision)
]
для вас в диапазоне (self.idct_precision)
]
def NormCoeff (self, n):
если n == 0:
вернуть 1.0 / math.sqrt (2.0)
еще:
возврат 1.0
def reinrange_using_zigzag (сам):
для x в диапазоне (8):
для y в диапазоне (8):
я.зигзаг [x] [y] = self.base [self.zigzag [x] [y]]
вернуть self.zigzag
def perform_IDCT (сам):
out = [список (диапазон (8)) для i в диапазоне (8)]
для x в диапазоне (8):
для y в диапазоне (8):
local_sum = 0
для u в диапазоне (self.idct_precision):
для v в диапазоне (self.idct_precision):
local_sum + = (
self.zigzag [v] [u]
* self.
idct_precision = 8
self.idct_table = [
[
(self.NormCoeff (u) * math.cos (((2.0 * x + 1.0) * u * math.pi) / 16.0))
для x в диапазоне (self.idct_precision)
]
для вас в диапазоне (self.idct_precision)
]
def NormCoeff (self, n):
если n == 0:
вернуть 1.0 / math.sqrt (2.0)
еще:
возврат 1.0
def reinrange_using_zigzag (сам):
для x в диапазоне (8):
для y в диапазоне (8):
я.зигзаг [x] [y] = self.base [self.zigzag [x] [y]]
вернуть self.zigzag
def perform_IDCT (сам):
out = [список (диапазон (8)) для i в диапазоне (8)]
для x в диапазоне (8):
для y в диапазоне (8):
local_sum = 0
для u в диапазоне (self.idct_precision):
для v в диапазоне (self.idct_precision):
local_sum + = (
self.zigzag [v] [u]
* self. idct_table [u] [x]
* сам.idct_table [v] [y]
)
out [y] [x] = local_sum // 4
self.base = out
idct_table [u] [x]
* сам.idct_table [v] [y]
)
out [y] [x] = local_sum // 4
self.base = out
Давайте попробуем разобраться в этом классе IDCT шаг за шагом. Как только мы извлечем MCU из JPEG, базовый атрибут этого класса сохранит его. Затем мы перегруппируем матрицу MCU, отменив зигзагообразное кодирование с помощью метода correrange_using_zigzag . Наконец, мы отменим дискретное косинусное преобразование, вызвав метод perform_IDCT .
Если вы помните, таблица дискретного косинуса фиксирована. То, как работают фактические вычисления для DCT, выходит за рамки этого руководства, поскольку это больше математика, чем программирование. Мы можем сохранить эту таблицу как глобальную переменную, а затем запросить в ней значения на основе пар x, y. Я решил поместить таблицу и ее расчет в класс IDCT для удобства чтения. Каждый отдельный элемент переупорядоченной матрицы MCU умножается на значения idc_variable , и в конечном итоге мы получаем обратно значения Y, Cr и Cb.
Это станет более понятным, если мы напишем метод BuildMatrix .
Если вы измените таблицу зигзага на что-то вроде этого:
[[0, 1, 5, 6, 14, 15, 27, 28],
[2, 4, 7, 13, 16, 26, 29, 42],
[3, 8, 12, 17, 25, 30, 41, 43],
[20, 22, 33, 38, 46, 51, 55, 60],
[21, 34, 37, 47, 50, 56, 59, 61],
[35, 36, 48, 49, 57, 58, 62, 63],
[9, 11, 18, 24, 31, 40, 44, 53],
[10, 19, 23, 32, 39, 45, 52, 54]]
У вас будет следующий результат (обратите внимание на небольшие артефакты):
А если хватит смелости, можно еще больше изменить зигзагообразную таблицу:
[[12, 19, 26, 33, 40, 48, 41, 34,],
[27, 20, 13, 6, 7, 14, 21, 28,],
[0, 1, 8, 16, 9, 2, 3, 10,],
[17, 24, 32, 25, 18, 11, 4, 5,],
[35, 42, 49, 56, 57, 50, 43, 36,],
[29, 22, 15, 23, 30, 37, 44, 51,],
[58, 59, 52, 45, 38, 31, 39, 46,],
[53, 60, 61, 54, 47, 55, 62, 63]]
Это приведет к следующему результату:
Теперь завершим наш метод BuildMatrix :
def DecodeNumber (код, биты):
l = 2 ** (код-1)
если биты> = l:
биты возврата
еще:
возвращаемые биты- (2 * l-1)
класс JPEG:
# -----
def BuildMatrix (self, st, idx, Quant, olddccoeff):
я = IDCT ()
код = сам. huffman_tables [0 + idx] .GetCode (st)
bits = st.GetBitN (код)
dccoeff = DecodeNumber (код, биты) + olddccoeff
i.base [0] = (dccoeff) * Quant [0]
l = 1
пока l <64:
code = self.huffman_tables [16 + idx] .GetCode (st)
если код == 0:
перерыв
# Первая часть таблицы квантования AC
# - количество ведущих нулей
если код> 15:
l + = код >> 4
code = код & 0x0F
биты = ул.GetBitN (код)
если l <64:
coeff = DecodeNumber (код, биты)
i.base [l] = коэфф * квант [l]
l + = 1
i.rearrange_using_zigzag ()
i.perform_IDCT ()
return i, dccoeff
huffman_tables [0 + idx] .GetCode (st)
bits = st.GetBitN (код)
dccoeff = DecodeNumber (код, биты) + olddccoeff
i.base [0] = (dccoeff) * Quant [0]
l = 1
пока l <64:
code = self.huffman_tables [16 + idx] .GetCode (st)
если код == 0:
перерыв
# Первая часть таблицы квантования AC
# - количество ведущих нулей
если код> 15:
l + = код >> 4
code = код & 0x0F
биты = ул.GetBitN (код)
если l <64:
coeff = DecodeNumber (код, биты)
i.base [l] = коэфф * квант [l]
l + = 1
i.rearrange_using_zigzag ()
i.perform_IDCT ()
return i, dccoeff
Начнем с создания класса обратного дискретного косинусного преобразования ( IDCT () ). Затем мы читаем битовый поток и декодируем его, используя нашу таблицу Хаффмана.
self. и  huffman_tables [0]
huffman_tables [0] self.huffman_tables [1] относятся к таблицам постоянного тока для яркости и цветности соответственно, а self.huffman_tables [16] и self.huffman_tables [17] относятся к таблицам переменного тока для яркости и цветности соответственно.
После того, как мы декодируем битовый поток, мы извлекаем новый дельта-кодированный коэффициент DC с помощью функции DecodeNumber и добавляем к нему старый коэффициент , чтобы получить дельта-декодированный коэффициент DC.
После этого мы повторяем ту же процедуру декодирования, но для значений AC в матрице квантования. Значение кода 0 предполагает, что мы встретили маркер конца блока (EOB) и нам нужно остановиться. Более того, первая часть таблицы количественных значений AC сообщает нам, сколько у нас ведущих нулей. Помните кодировку длин серий, о которой мы говорили в первой части? Вот где это вступает в игру. Мы декодируем кодирование длин серий и пропускаем это количество битов вперед. Все пропущенные биты неявно устанавливаются в 0 в классе
Мы декодируем кодирование длин серий и пропускаем это количество битов вперед. Все пропущенные биты неявно устанавливаются в 0 в классе IDCT .
После того, как мы декодировали значения постоянного и переменного тока для MCU, мы переупорядочиваем MCU и отменяем зигзагообразное кодирование, вызывая correrange_using_zigzag , а затем выполняем обратный DCT для декодированного MCU.
Метод BuildMatrix возвращает обратную матрицу DCT и значение коэффициента DC. Помните, что эта обратная матрица DCT предназначена только для одной крошечной матрицы MCU 8x8 (Minimum Coded Unit). Мы будем делать это для всех отдельных микроконтроллеров во всем файле образа.
Отображение изображения на экране
Давайте немного изменим наш код и создадим холст Tkinter и раскрасим каждый MCU после его декодирования в методе StartOfScan .
def Зажим (столбец):
col = 255, если col> 255, иначе col
col = 0, если col <0, иначе col
return int (col)
def ColorConversion (Y, Cr, Cb):
R = Cr * (2-2 * 0,299) + Y
В = Cb * (2-2 * .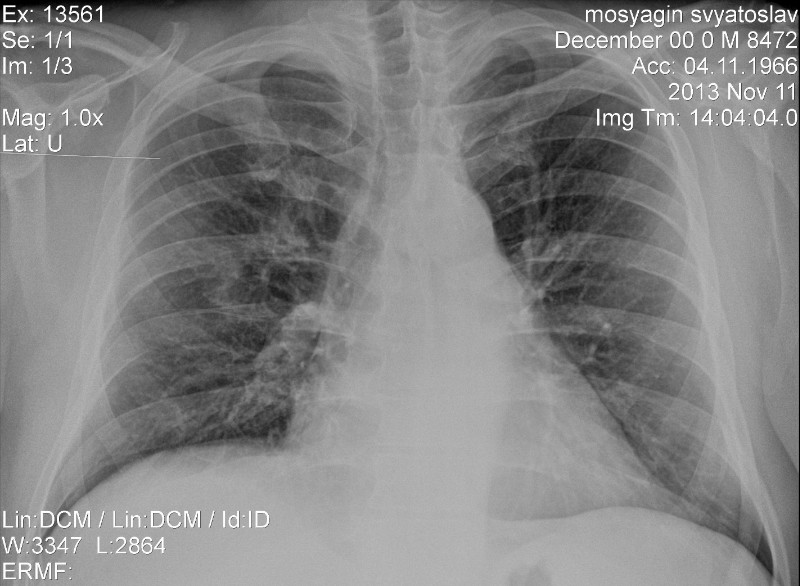 114) + Y
G = (Y - .114 * B - .299 * R) /. 587
возврат (Зажим (R + 128), Зажим (G + 128), Зажим (B + 128))
def DrawMatrix (x, y, matL, matCb, matCr):
для yy в диапазоне (8):
для xx в диапазоне (8):
c = "#% 02x% 02x% 02x"% ColorConversion (
matL [yy] [xx], matCb [yy] [xx], matCr [yy] [xx]
)
х1, у1 = (х * 8 + хх) * 2, (у * 8 + уу) * 2
x2, y2 = (x * 8 + (xx + 1)) * 2, (y * 8 + (yy + 1)) * 2
ш.create_rectangle (x1, y1, x2, y2, fill = c, контур = c)
класс JPEG:
# -----
def StartOfScan (self, data, hdrlen):
данные, lenchunk = RemoveFF00 (данные [hdrlen:])
st = поток (данные)
oldlumdccoeff, oldCbdccoeff, oldCrdccoeff = 0, 0, 0
для y в диапазоне (self.height // 8):
для x в диапазоне (self.width // 8):
matL, oldlumdccoeff = self.BuildMatrix (st, 0, self.quant [self.quantMapping [0]], oldlumdccoeff)
matCr, oldCrdccoeff = self.
114) + Y
G = (Y - .114 * B - .299 * R) /. 587
возврат (Зажим (R + 128), Зажим (G + 128), Зажим (B + 128))
def DrawMatrix (x, y, matL, matCb, matCr):
для yy в диапазоне (8):
для xx в диапазоне (8):
c = "#% 02x% 02x% 02x"% ColorConversion (
matL [yy] [xx], matCb [yy] [xx], matCr [yy] [xx]
)
х1, у1 = (х * 8 + хх) * 2, (у * 8 + уу) * 2
x2, y2 = (x * 8 + (xx + 1)) * 2, (y * 8 + (yy + 1)) * 2
ш.create_rectangle (x1, y1, x2, y2, fill = c, контур = c)
класс JPEG:
# -----
def StartOfScan (self, data, hdrlen):
данные, lenchunk = RemoveFF00 (данные [hdrlen:])
st = поток (данные)
oldlumdccoeff, oldCbdccoeff, oldCrdccoeff = 0, 0, 0
для y в диапазоне (self.height // 8):
для x в диапазоне (self.width // 8):
matL, oldlumdccoeff = self.BuildMatrix (st, 0, self.quant [self.quantMapping [0]], oldlumdccoeff)
matCr, oldCrdccoeff = self. BuildMatrix (st, 1, self.квант [self.quantMapping [1]], oldCrdccoeff)
matCb, oldCbdccoeff = self.BuildMatrix (st, 1, self.quant [self.quantMapping [2]], oldCbdccoeff)
DrawMatrix (x, y, matL.base, matCb.base, matCr.base)
вернуть lenchunk + hdrlen
если __name__ == "__main__":
из tkinter import *
master = Tk ()
w = Холст (мастер, ширина = 1600, высота = 600)
w.pack ()
img = JPEG ('profile.jpg')
img.decode ()
mainloop ()
BuildMatrix (st, 1, self.квант [self.quantMapping [1]], oldCrdccoeff)
matCb, oldCbdccoeff = self.BuildMatrix (st, 1, self.quant [self.quantMapping [2]], oldCbdccoeff)
DrawMatrix (x, y, matL.base, matCb.base, matCr.base)
вернуть lenchunk + hdrlen
если __name__ == "__main__":
из tkinter import *
master = Tk ()
w = Холст (мастер, ширина = 1600, высота = 600)
w.pack ()
img = JPEG ('profile.jpg')
img.decode ()
mainloop ()
Начнем с функций ColorConversion и Clamp . ColorConversion принимает значения Y, Cr и Cb, использует формулу для преобразования этих значений в их аналоги RGB, а затем выводит зафиксированные значения RGB. Вы можете задаться вопросом, почему мы добавляем 128 к значениям RGB. Если вы помните, прежде чем компрессор JPEG применяет DCT к MCU, он вычитает 128 из значений цвета. Если цвета изначально находились в диапазоне [0,255], JPEG помещает их в диапазон [-128, + 128]. Таким образом, мы должны отменить этот эффект, когда декодируем JPEG, и поэтому мы добавляем 128 к RGB.Что касается
Таким образом, мы должны отменить этот эффект, когда декодируем JPEG, и поэтому мы добавляем 128 к RGB.Что касается Clamp , то во время декомпрессии выходное значение может превышать [0,255], поэтому мы зажимаем их между [0,255].
В методе DrawMatrix мы перебираем каждую декодированную матрицу 8x8 Y, Cr и Cb в цикле и преобразуем каждый элемент матриц 8x8 в значения RGB. После преобразования мы рисуем каждый пиксель на холсте Tkinter , используя метод create_rectangle . Вы можете найти полный код на GitHub. Теперь, если вы запустите этот код, мое лицо появится на вашем экране
Заключение
О мальчик! Кто бы мог подумать, что потребуется 6000 слов + объяснение, чтобы показать мое лицо на экране.Я поражен тем, насколько умны некоторые из этих изобретателей алгоритмов! Надеюсь, вам понравилась эта статья так же, как мне понравилось ее писать. Я многому научился, когда писал этот декодер. Я никогда не понимал, сколько причудливой математики вкладывается в кодирование простого изображения JPEG.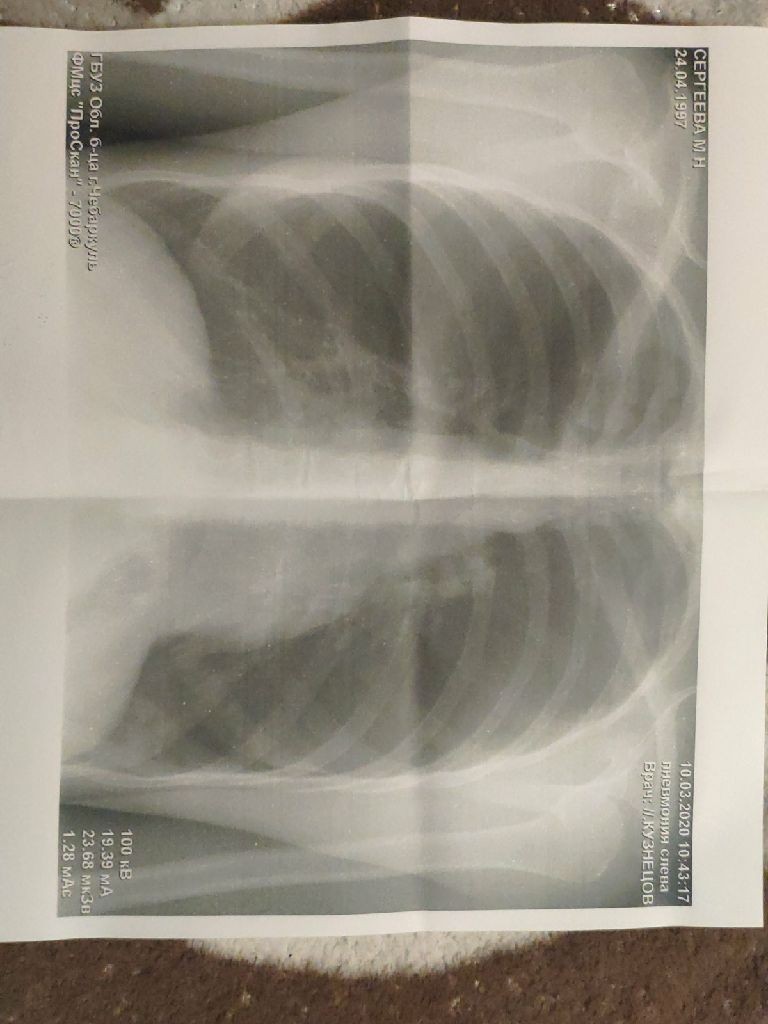 Затем я мог бы поработать над изображением PNG и попробовать написать декодер для изображения PNG. Вам также следует попробовать написать декодер для PNG (или другого формата). Я уверен, что это потребует много обучения и даже больше удовольствия от шестиугольников 😅
Затем я мог бы поработать над изображением PNG и попробовать написать декодер для изображения PNG. Вам также следует попробовать написать декодер для PNG (или другого формата). Я уверен, что это потребует много обучения и даже больше удовольствия от шестиугольников 😅
В любом случае, я устал.Я слишком долго смотрел на Хекс и думаю, что заслужил передышку. Будьте внимательны, и если у вас возникнут вопросы, напишите их в комментариях ниже. Я новичок в этом приключении по кодированию в формате JPEG, но я постараюсь ответить как можно больше 😄
Пока! 👋 ❤️
Дополнительная литература
Если вы хотите вникнуть в подробности, вы можете взглянуть на несколько ресурсов, которые я использовал при написании этой статьи. Я также добавил несколько дополнительных ссылок на некоторые интересные вещи, связанные с JPEG:
ImpulseAdventure - JPEGsnoop 1.8.0 - Утилита декодирования JPEG
Обзор
Последняя версия: 1.8.0
Введение
Каждая цифровая фотография содержит множество скрытой информации - JPEGsnoop был написан для того, чтобы раскрыть эти детали всем, кому интересно.
Можно не только определить различные настройки, которые использовались в цифровой камере при фотосъемке (метаданные EXIF, IPTC), но также можно извлечь информацию, которая указывает качество и характер сжатия изображения JPEG, используемого камерой при сохранении. файл.Каждая цифровая камера определяет уровни качества сжатия, многие из которых сильно различаются, что приводит к тому, что некоторые камеры создают гораздо лучшие изображения JPEG, чем другие.
Что я могу сделать?
Ознакомьтесь с некоторыми из множества возможных применений JPEGsnoop!
Одной из последних функций JPEGsnoop является внутренняя база данных, которая сравнивает изображение с большим количеством сигнатур сжатия. JPEGsnoop сообщает, какая цифровая камера или программное обеспечение, вероятно, использовались для создания изображения.Это чрезвычайно полезно в для определения того, была ли фотография отредактирована / подделана каким-либо образом. Если подпись сжатия соответствует Photoshop, то вы можете быть уверены, что фотография больше не является оригиналом! Этот тип анализа иногда называют баллистикой цифровых изображений / криминалистикой.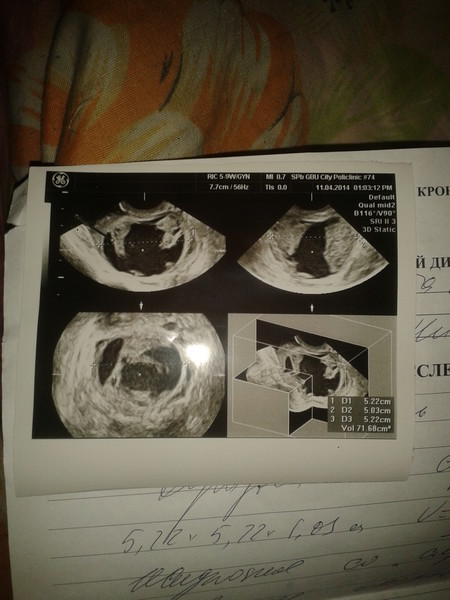
JPEGsnoop сообщает огромное количество информации, в том числе: матрицу таблицы квантования (цветность и яркость), субдискретизацию цветности, оценки настроек качества JPEG, настройки разрешения JPEG, таблицы Хаффмана, метаданные EXIF, заметки Makernotes, гистограммы RGB и т. Д.Сообщается о большинстве маркеров JPEG JFIF. Кроме того, вы можете включить полное декодирование VLC Хаффмана, что поможет тем, кто изучает сжатие JPEG, и тем, кто пишет декодер JPEG.
JPEGsnoop теперь также может анализировать и декодировать файлы Photoshop!
Другие возможности использования: определение параметров качества, используемых в Photoshop, «Сохранить как» или «Сохранить для Интернета», повышение качества сканера, поиск восстанавливаемых изображений / видео, декодирование файлов AVI, изучение файлов .THM, эскизов JPEG EXIF, извлечение встроенных изображений в документы Adobe PDF , так далее.
Пытаетесь отменить удаление или отформатировать фотографии?
Если вы заинтересованы в попытке восстановить удаленные / поврежденные фотографии, посетите мою новую страницу по восстановлению удаленных фотографий.
Поддерживаемые типы файлов
JPEGsnoop откроется и попытается декодировать любой файл, содержащий встроенное изображение JPEG, например:
- .JPG - Фотография в формате JPEG
- .THM - эскиз для файлов фото / видео в формате RAW
- .AVI * - фильмы AVI
- .DNG - Цифровое негативное фото в формате RAW
- .PSD - файлы Adobe Photoshop
- .CRW , .CR2 , .NEF , .ORF , .PEF - RAW Фото
- .MOV * - фильмы QuickTime, QTVR (виртуальная реальность / панорама 360)
- .PDF - Документы Adobe PDF
* Обратите внимание, что форматы видеофайлов (например,.AVI и .MOV) - это контейнеров , которые могут
включать видеопотоки, закодированные с помощью одного из множества кодеков. JPEGsnoop может интерпретировать это видео только в том случае, если используемый кодек основан на Motion JPEG (MJPG).
JPEGsnoop может интерпретировать это видео только в том случае, если используемый кодек основан на Motion JPEG (MJPG).
Загрузите последнюю версию JPEGsnoop!
|
Нажмите, чтобы загрузить .ZIP |
Версия: 1.8.0 История версий Дата выпуска: 26.06.2017 |
JPEGsnoop от Calvin HassСправка Поддержка JPEGsnoop DevelopmentЕсли вы нашли JPEGsnoop полезным и хотели бы поддержать его дальнейшее развитие, подумайте о том, чтобы внести небольшой вклад.Пожертвования помогут мне добавить новые интересные функции. Нашли интересное применение инструменту? Дай мне знать! |
Исходный код : JPEGsnoop теперь является открытым исходным кодом на GitHub!
Системные требования Это приложение было разработано и протестировано для работы в Windows XP / Vista / 8 / 10. Пользователи LINUX: JPEGsnoop, по-видимому, работает на LINUX под вином Пользователи Mac: JPEGsnoop работает с CrossOver Mac Условия использованияJPEGsnoop является бесплатным для личного использования и коммерческого использования . Коммерческим пользователям рекомендуется оставить мне короткое личное сообщение, чтобы я мог понять ваши потребности и сделать будущие версии более полезными. |
УстановкаУстановка не требуется.JPEGsnoop очень портативен. Просто разархивируйте загрузку и запустите! История версийДля получения информации о функциях, добавленных в предыдущих версиях JPEGsnoop, посетите страницу истории версий. Запросы функций / отчеты об ошибкахПожалуйста, не стесняйтесь добавлять свои собственные запросы функций или отчеты об ошибках, отправляя ссылки на странице источника JPEGsnoop |
 Начиная с версии v1.7, Windows XP SP1 является минимальным требованием.JPEGsnoop полностью портативен, поэтому не требует установки!
Начиная с версии v1.7, Windows XP SP1 является минимальным требованием.JPEGsnoop полностью портативен, поэтому не требует установки! Награды и признание для JPEGsnoop
|
|
 de Magazine - Chip Pick - июнь 2017 г.
de Magazine - Chip Pick - июнь 2017 г. | Главное окно |
|---|
| Гистограммы каналов |
| Сеть и позиционирование MCU |
Документация
См. Страницу параметров для получения информации о том, как использовать JPEGsnoop и других интересных вариантах использования инструмента
Последние функции
- Photoshop PSD декодирование
- Пакетная обработка файлов
- Отображение заголовка XMP APP1 и ICC
- Синтаксический анализ IPTC и Photoshop IRB / 8BIM
- Отображение метаданных EXIF GPS
- Полные подробные выходные данные декодирования Huffman VLC для тех, кто интересуется написанием декодера или изучением сжатия JPEG
- Автоматическое отображение значений блока постоянного тока YCC (16 бит)
- MCU Наложение сетки и автоматическое отображение положения MCU мыши и смещения файла в окне отображения изображения.

- Улучшена функция наложения тестов, позволяющая быстро применять и считывать двоичный код.
- Уровень масштабирования изображения от 12,5% до 800%.
- Извлечение встроенных файлов JPEG - можно использовать для извлечения эскизов, скрытых файлов JPEG, а также кадров из файлов Motion JPEG AVI.
- Обнаружение сжатия улучшено для обнаружения повернутых подписей, поля комментариев.
- Полный анализ файла AVI (для определения MotionJPEG)
- Поиск таблиц DQT в исполняемых файлах (для «хакеров»)
- Обнаружение отредактированных изображений или определение оригинальной цифровой камеры, сделавшей фотографию!
- Интегрированная база данных тысяч сигнатур сжатия (отпечатков пальцев изображения) для цифровых фотоаппаратов и программного обеспечения для редактирования
- Функция проверки наложения файлов
- Многоканальный предварительный просмотр: RGB, YCC, R / G / B, Y / Cb / Cr
- Поиск положения пикселя в смещении файла
- Изучите Motion JPEG .
 Файлы AVI или .MOV (Quicktime) (MJPG или MJPEG) и играйте!
Файлы AVI или .MOV (Quicktime) (MJPG или MJPEG) и играйте! - Изучите все фрагменты файлов, которые могут содержать изображение JPEG
- YCC to RGB Отчеты статистики цветокоррекции / обрезки
- Выполнение из командной строки
- Статистика кода Хаффмана с переменной длиной
- Расширение DHT (расширение таблицы Хаффмана в битовые строки)
- Определить коэффициент качества IJG JPEG
Справочные материалы
Если вы хотите понять некоторые технические детали, сообщаемые JPEGsnoop, я предлагаю вам прочитать мои статьи о сжатии JPEG:
Предложения
Поскольку эта работа еще не завершена, мне было бы очень интересно услышать от вас, особенно для запросов функций, предложений, комментариев, ошибок отчеты и др.Если вы в настоящее время используете JPEGsnoop и считаете его полезным, дайте мне знать!
Unraveling JPEG
JPEG-изображения повсюду в нашей цифровой жизни, но за пеленой привычки скрываются алгоритмы, удаляющие детали, невидимые человеческому глазу. Это обеспечивает высочайшее качество изображения при наименьшем размере файла - но как это выглядит? Посмотрим, чего не видят наши глаза!
Это обеспечивает высочайшее качество изображения при наименьшем размере файла - но как это выглядит? Посмотрим, чего не видят наши глаза!
Легко принять как должное, что вы можете отправить картинку другу, не беспокоясь о том, какое устройство, браузер или операционную систему они используют, но не всегда так было.К началу 1980-х годов компьютеры могли хранить и отображать цифровые изображения, но было много конкурирующих идей о том, как это лучше всего сделать. Нельзя просто отправить изображение с одного компьютера на другой и ожидать, что оно сработает.
Для решения этой проблемы Объединенная группа экспертов по фотографии (JPEG), комитет экспертов со всего мира, была создана в 1986 году совместными усилиями ISO (Международной организации по стандартизации) и IEC (Международной электротехнической комиссии). ) - две международные организации по стандартизации со штаб-квартирой в Женеве, Швейцария.
JPEG, группа людей, создала JPEG, стандарт сжатия цифровых изображений, в 1992 году. Любой, кто когда-либо пользовался Интернетом, вероятно, видел изображения в формате JPEG. Это, безусловно, наиболее распространенный способ кодирования, отправки и хранения изображений. От веб-страниц до электронной почты и социальных сетей JPEG используется миллиарды раз в день - почти каждый раз, когда мы просматриваем или отправляем изображения в Интернете. Без JPEG Интернет был бы немного менее красочным, намного медленнее и, вероятно, имел бы гораздо меньше изображений кошек!
Любой, кто когда-либо пользовался Интернетом, вероятно, видел изображения в формате JPEG. Это, безусловно, наиболее распространенный способ кодирования, отправки и хранения изображений. От веб-страниц до электронной почты и социальных сетей JPEG используется миллиарды раз в день - почти каждый раз, когда мы просматриваем или отправляем изображения в Интернете. Без JPEG Интернет был бы немного менее красочным, намного медленнее и, вероятно, имел бы гораздо меньше изображений кошек!
Эта статья о том, как декодировать изображение в формате JPEG.Другими словами, речь идет о том, что нужно для преобразования сжатых данных, хранящихся на вашем компьютере, в изображение, которое появляется на экране. Об этом стоит узнать не только потому, что важно понимать технологии, которые мы все используем каждый день, но и потому, что, распутывая уровни сжатия, мы немного узнаем о восприятии и зрении, а также о том, к каким деталям наши глаза наиболее чувствительны.
Играть с изображениями таким образом - просто весело.
Пиринг внутри JPEG
Все на компьютере хранится в виде последовательности двоичных чисел.Обычно эти биты, нули и единицы, располагаются в группах по восемь штук, известных как байты. Когда вы открываете изображение JPEG на своем компьютере, что-то (браузер, ваша операционная система или что-то еще) должно декодировать байты, чтобы восстановить исходное изображение в виде списка цветов, который затем может быть отображен.
Если вы загрузите это изображение кота и откроете его с помощью любого текстового редактора, вы увидите кучу искаженных символов.Здесь я использую Notepad ++ для просмотра файла изображения, поскольку обычные текстовые редакторы, такие как Блокнот Windows, изменят двоичное содержимое файла при его сохранении, так что он больше не является допустимым JPEG.
Открывая изображение в текстовом редакторе, вы сбиваете с толку компьютер, точно так же, как вы сбиваете с толку свой мозг, когда слишком сильно трете глаза и начинаете видеть тусклые и цветные пятна!
Эти пятна, которые вы видите, известные как фосфены, не возникают из-за каких-либо световых раздражителей, и они не являются галлюцинациями, созданными в вашем уме.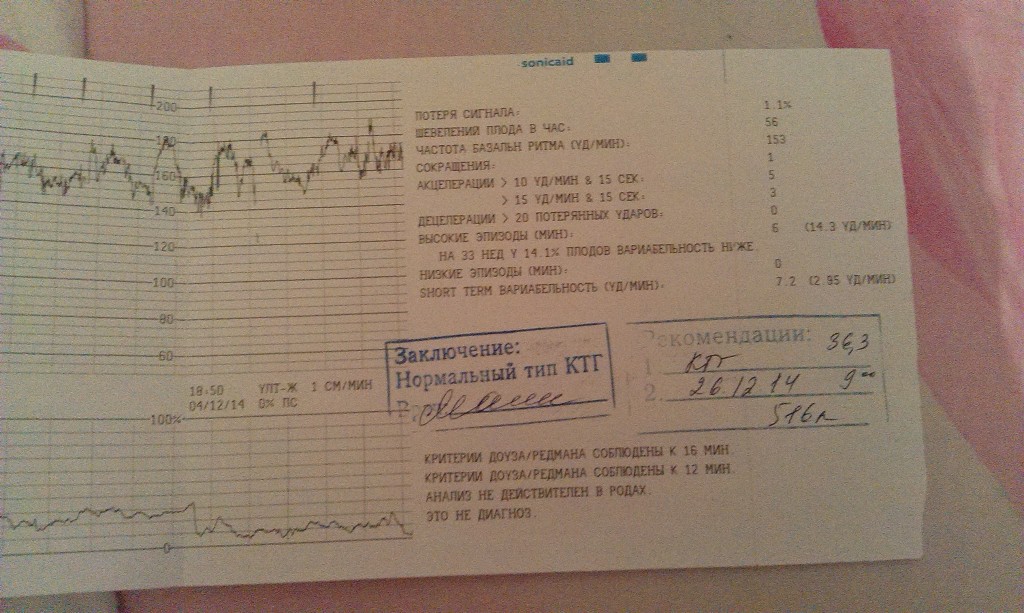 Они возникают потому, что ваш мозг предполагает, что любой электрический сигнал, проходящий через нервы в вашем глазу, передает световую информацию. Мозгу необходимо сделать это предположение, потому что невозможно узнать, является ли данный сигнал звуком, зрением или чем-то еще.Все нервы в вашем теле переносят точно такой же тип электрического импульса. Когда вы прикладываете давление, протирая глаза, вы посылаете невизуальные сигналы, которые запускают рецепторы в вашем глазу, которые ваш мозг интерпретирует - в данном случае неправильно - как зрение. Вы буквально можете увидеть давление!
Они возникают потому, что ваш мозг предполагает, что любой электрический сигнал, проходящий через нервы в вашем глазу, передает световую информацию. Мозгу необходимо сделать это предположение, потому что невозможно узнать, является ли данный сигнал звуком, зрением или чем-то еще.Все нервы в вашем теле переносят точно такой же тип электрического импульса. Когда вы прикладываете давление, протирая глаза, вы посылаете невизуальные сигналы, которые запускают рецепторы в вашем глазу, которые ваш мозг интерпретирует - в данном случае неправильно - как зрение. Вы буквально можете увидеть давление!
Забавно подумать о том, насколько компьютеры похожи на наш мозг, но это также полезная аналогия, потому что она показывает, насколько значение данных - независимо от того, переносятся ли они через тело по нервам или хранятся в компьютере - зависит от того, как вы интерпретируете Это.Все двоичные данные состоят из единиц и нулей, основных компонентов, которые могут передавать любую информацию. Ваш компьютер часто догадывается, как его интерпретировать, используя подсказки, такие как расширение файла. Здесь мы заставили его интерпретировать его как текст, потому что это то, что ожидает текстовый редактор.
Ваш компьютер часто догадывается, как его интерпретировать, используя подсказки, такие как расширение файла. Здесь мы заставили его интерпретировать его как текст, потому что это то, что ожидает текстовый редактор.
Чтобы понять, как декодируется изображение JPEG, нам нужно увидеть сами исходные сигналы - двоичные данные. Это можно сделать с помощью шестнадцатеричного редактора
. Вам не обязательно , что вам нужен шестнадцатеричный редактор .Вы можете редактировать символы как текст, сохранять файл и снова открывать его как изображение. Но поскольку наша цель - понять, как JPEG хранит изображения, полезно иметь возможность читать байты!
, или это можно сделать прямо здесь, на этой странице! Ниже показано изображение рядом со всеми его байтами. Единственное, что здесь опущено, это заголовок, который представляет собой секцию байтов в начале любого изображения JPEG, которое содержит метаданные, такие как ширина и высота. Мы вернемся к этому позже в статье.
в виде десятичных чисел. Вы можете внести изменения в байты, и он будет повторно декодировать и отображать новое отредактированное изображение по мере ввода.
Вы можете внести изменения в байты, и он будет повторно декодировать и отображать новое отредактированное изображение по мере ввода. Совет: попробуйте прокрутить вниз и удалить несколько фрагментов. Не волнуйтесь, вы всегда можете восстановить исходное изображение!
Вы можете многому научиться, просто играя с этим редактором. Например, можете ли вы определить порядок, в котором хранятся пиксели?
Что-то странное в приведенном выше примере заключается в том, что изменение некоторых чисел, похоже, вообще не влияет на изображение, тогда как установка 17 в первой строке на 0 полностью портит изображение! Другие действия, такие как установка 7 в строке 1988 на 254, изменяют цвет, но только для последующих пикселей.
Еще из параметрического пресса
Пожалуй, самое странное, что некоторые числа меняют не только цвет, но и форму изображения. Измените 70 в строке 12 на 2 и посмотрите на верхнюю строку изображения, чтобы понять, что я имею в виду. Независимо от того, какое изображение JPEG вы используете, вы всегда найдете эти загадочные узоры в виде шахматной доски при редактировании байтов.
Независимо от того, какое изображение JPEG вы используете, вы всегда найдете эти загадочные узоры в виде шахматной доски при редактировании байтов.
Трудно расшифровать, как изображение может быть реконструировано из этих байтов, играя подобным образом, потому что сжатие JPEG фактически состоит из трех различных методов сжатия, которые применяются в последовательных слоях.Мы рассмотрим каждый из этих уровней сжатия отдельно, чтобы разгадать это загадочное поведение, которое мы наблюдаем.
Три уровня сжатия JPEG
- Подвыборка цветности
- Дискретное косинусное преобразование и квантование
- Длина цикла, дельта-кодирование и кодирование Хаффмана
Чтобы дать вам представление о масштабе этого сжатия, обратите внимание, что изображение выше представлено ровно 79 819 чисел, что составляет около 79 килобайт. Если бы он был сохранен без сжатия, для каждого пикселя потребовалось бы три числа - по одному для каждого из красного, зеленого и синего компонентов. Это будет означать в общей сложности 917 700 номеров, или около 917 килобайт. При сжатии JPEG полученный файл будет более чем на в десять раз меньше !
Это будет означать в общей сложности 917 700 номеров, или около 917 килобайт. При сжатии JPEG полученный файл будет более чем на в десять раз меньше !
Фактически, этот образ можно сжать до гораздо меньшего количества байтов. Ниже приведено изображение рядом с его версией, которая была сжата до 16 килобайт, что делает его в пятьдесят семь раз меньше , чем была бы несжатая версия!
Если вы присмотритесь, то увидите, что эти изображения не идентичны. Оба изображения закодированы в формате JPEG, но то, что справа, намного меньше по размеру файла.Он также выглядит не так красиво (обратите внимание, как блочно цвета выглядят на фоне). Вот почему JPEG известен как метод сжатия с потерями ; изображение изменяется и теряет некоторые детали в результате сжатия.
1. Субдискретизация цветности
Вот изображение с примененным только первым слоем сжатия.
Подсказка: обратите внимание, что удаление одного числа портит все цвета. Но удаление ровно 6 или любого числа, кратного 6, оказывает минимальное влияние на изображение.
Но удаление ровно 6 или любого числа, кратного 6, оказывает минимальное влияние на изображение.
Теперь расшифровать немного проще. Это почти простой список цветов, в котором каждый байт изменяет ровно один пиксель, но при этом он уже почти вдвое меньше несжатого изображения (что составляет около 300 КБ для этого меньшего размера). Вы можете догадаться, почему?
Вы можете сказать, что эти числа не представляют стандартные красные, зеленые и синие компоненты, потому что замена всех чисел на 0 делает изображение зеленым (в отличие от черного).
Это потому, что эти байты представляют Y (яркость), Cb (относительную голубизну) и Cr (относительную красноту) изображения.
Почему бы просто не использовать RGB? В конце концов, именно так работают большинство современных экранов. Ваш монитор может отображать любой цвет, включая красный, зеленый и синий свет с различной интенсивностью для каждого пикселя. Белый цвет отображается при включении всех трех цветов на полную яркость, а черный отображается при их отключении.
Это тоже очень похоже на то, как работают человеческие глаза. Цветовые рецепторы в наших глазах, известные как «колбочки», делятся на три типа, каждый из которых наиболее чувствителен к красному, зеленому или синему цвету.Палочки, другой тип рецепторов наших глаз, могут обнаруживать только изменения яркости, но они гораздо более чувствительны. У нас в глазах около ста двадцати миллионов палочек по сравнению с жалкими шестью миллионами колбочек.
Это означает, что наши глаза гораздо лучше обнаруживают изменения яркости, чем изменения цвета. Если мы сможем отделить цвет от яркости, мы сможем удалить немного цвета, чтобы никто не заметил. Подвыборка цветности - это процесс представления компонентов цвета изображения с более низким разрешением, чем его компоненты яркости.В приведенном выше примере каждый пиксель имеет ровно один компонент Y, в то время как каждая дискретная группа из четырех пикселей имеет ровно один компонент Cb и один компонент Cr. Таким образом, изображение содержит только четверть цветовой информации, чем было изначально.
Таким образом, изображение содержит только четверть цветовой информации, чем было изначально.
Вот почему удаление одного числа из вышеприведенного редактора полностью портит цвет. Здесь хранятся компоненты.
Как правило, изображения в формате JPEG не нуждаются в хранении компонентов в каком-либо определенном порядке. Они могут чередоваться, как в этом примере, или могут быть сохранены все компоненты Y изображения, за которыми следуют все Cb и т. Д. Заголовок JPEG - это то, что сообщает нам, как хранятся компоненты.
как Y Y Y Y Cb Cr . Удаление первого числа приводит к тому, что значение Cb интерпретируется как Y, Cr как Cb, и создает эффект пульсации, который переворачивает все цвета на изображении.
В спецификации JPEG нет ничего, что говорило бы, что вы должны использовать YCbCr. В большинстве изображений JPEG, которые вы найдете, он используется, потому что после субдискретизации он дает изображения более высокого качества по сравнению с RGB. Однако не стоит принимать это как должное. Вы можете сами увидеть в таблице ниже, как выглядит субдискретизация каждого компонента индивидуально по RGB, а также YCbCr.
Процент субдискретизации: 15%
Переместите ползунок, чтобы отрегулировать количество применяемой субдискретизации.
Удаление немного синего не так заметно, как удаление красного или зеленого.Это связано с шестью миллионами колбочек в ваших глазах, около 64% наиболее чувствительны к красному, 32% - к зеленому и только 2% - к синему.
Субдискретизация компонента Y (внизу слева) имеет наибольшее влияние на качество изображения. Даже крохотный кусочек уже заметен. Вы можете переместить ползунок, чтобы увидеть, как удаление большего процента каждого компонента влияет на изображение.
Преобразование изображения из RGB в YCbCr не уменьшает размер файла, но облегчает поиск менее заметных деталей для удаления.Это второй этап, на котором происходит фактическое сжатие с потерями. Эта идея поиска новых способов представления данных, чтобы сделать их более сжимаемыми, лежит в основе того, что делает следующий слой.
2. Дискретное косинусное преобразование и квантование
Этот уровень сжатия в значительной степени является определяющей особенностью JPEG. После преобразования цветов в YCbCr компоненты сжимаются по отдельности, так что мы можем сосредоточиться только на компоненте Y до конца статьи. Вот как выглядят байты для компонента Y после применения этого слоя.
Подсказка: попробуйте щелкнуть любой пиксель изображения, чтобы увидеть строку в редакторе, которая его представляет. Попробуйте убрать числа с конца или добавить несколько нулей к любому отдельному числу, чтобы сделать его эффект более очевидным.
На первый взгляд это кажется очень плохим сжатием. На этом изображении 100 000 пикселей, и все же для представления яркости каждого пикселя требуется 102 400 чисел - это хуже, чем его вообще не сжимать!
На этом изображении 100 000 пикселей, и все же для представления яркости каждого пикселя требуется 102 400 чисел - это хуже, чем его вообще не сжимать!
Но обратите внимание, что большинство из этих значений равны 0.Фактически, все эти завершающие нули можно удалить без изменения изображения. Остается около 26 000 номеров, что делает его примерно в четыре раза меньше!
В этом слое кроется секрет узоров шахматной доски. В отличие от других эффектов, которые мы видели, появление этих паттернов не является ошибкой. Фактически, они являются строительными блоками всего изображения. Каждая строка в редакторе выше содержит ровно 64 числа, известных как коэффициенты дискретного косинусного преобразования (DCT), которые соответствуют интенсивности 64 уникальных паттернов.
Эти паттерны образованы косинусоидальными волнами. Вот как выглядят некоторые из них:
Это 8 из 64 коэффициентов дискретного косинусного преобразования. Предоставлено: Джез Суонсон. Ниже приведено изображение, на котором показаны все 64 из них по отдельности.
Эти узоры особенные, потому что они составляют основу изображений 8x8. Если вы не знакомы с линейной алгеброй, это означает, что любое изображение 8x8, все, что вы можете себе представить, может быть создано из этих 64-х конкретных шаблонов.Дискретное косинусное преобразование - это процесс разбиения изображения на блоки 8x8 и преобразования каждого блока в комбинацию этих 64 коэффициентов. Вот как вы могли бы сформировать круг, комбинируя эти узоры, или морду кошки. Вы можете нажать здесь, чтобы вернуться к сетке из 64 узоров.
Кажется волшебством сказать, что любое изображение может быть представлено с помощью 64 определенных шаблонов. Но это то же самое, что сказать, что любое место на Земле может быть представлено только двумя числами: долготой и широтой.Мы часто рассматриваем поверхность Земли как двумерную, поэтому нужны только два числа. Изображение 8x8 является шестидесяти четырехмерным, поэтому нам нужно шестьдесят четыре числа.
Что касается сжатия, не ясно, как это нам помогает. Если нам нужно шестьдесят четыре числа для представления изображения 8x8, почему это лучше, чем сохранение шестидесяти четырех компонентов яркости? Мы делаем это по той же причине, по которой мы преобразовали три числа RGB в три числа YCbCr: это позволяет нам удалить менее заметные детали.
Если нам нужно шестьдесят четыре числа для представления изображения 8x8, почему это лучше, чем сохранение шестидесяти четырех компонентов яркости? Мы делаем это по той же причине, по которой мы преобразовали три числа RGB в три числа YCbCr: это позволяет нам удалить менее заметные детали.
Трудно точно увидеть, как выглядят детали, которые удаляются на этом этапе сжатия, потому что JPEG применяет дискретное косинусное преобразование только к блокам размером 8x8 пикселей за раз. Однако нет причин, по которым мы не можем применить его ко всему изображению. Вот как выглядит применение DCT к компоненту Y всего изображения:
Мы можем удалить более 60 000 чисел с конца без каких-либо заметных изменений. Но обратите внимание, что если мы установим только первые пять чисел на ноль (игнорируя первое, потому что оно просто делает изображение темнее), уже будет очевидная разница.
Получение обновлений с параметрического пресса
Цифры в начале представляют изменения с более низкой частотой в изображении, которые наши глаза лучше распознают. Цифры в конце обозначают более частые изменения, которые нам труднее увидеть, поэтому мы не замечаем, когда они исчезают. Чтобы увидеть «то, что не видят наши глаза», мы можем выделить эти высокочастотные детали, установив первые 5000 чисел равными нулю.
Цифры в конце обозначают более частые изменения, которые нам труднее увидеть, поэтому мы не замечаем, когда они исчезают. Чтобы увидеть «то, что не видят наши глаза», мы можем выделить эти высокочастотные детали, установив первые 5000 чисел равными нулю.
Здесь вы видите все области изображения, которые больше всего изменяются от одного пикселя к другому.Выделяются кошачьи глаза, усы, пушистое одеяло и тени в левом нижнем углу. Это можно сделать еще дальше, установив первые 10 000 чисел в ноль; 20,000; 40 000 или 60 000.
Эти высокочастотные детали - это то, что JPEG удаляет на этом этапе сжатия. Преобразование цветов в коэффициенты DCT не является операцией с потерями. Это этап квантования с потерями, когда удаляются значения с высокой частотой, близкие к нулю или и то, и другое. Когда вы выбираете параметр более низкого качества при создании изображения JPEG, он увеличивает порог того, сколько из этих значений удаляется, что приводит к меньшему размеру файла, но к более блочному изображению. Поэтому вариант изображения в первом разделе, который был в 57 раз меньше, выглядел блочно. Каждый блок 8x8 был представлен гораздо меньшим количеством DCT-коэффициентов по сравнению с версией более высокого качества.
Поэтому вариант изображения в первом разделе, который был в 57 раз меньше, выглядел блочно. Каждый блок 8x8 был представлен гораздо меньшим количеством DCT-коэффициентов по сравнению с версией более высокого качества.
Одна действительно крутая вещь, которую вы можете сделать с помощью этой техники, - это постепенная потоковая передача изображений. Представьте, что вы видите размытую версию всего изображения и постепенно видите, как оно становится все более и более детализированным по мере того, как загрузка прогрессирует и становятся доступными все больше коэффициентов DCT. На самом деле это возможно сделать с JPEG, но не так часто.
Просто для удовольствия, вот как это выглядит с использованием всего 24 000 чисел или всего 5000 чисел. Довольно размыто, но почти узнаваемо!
3. Длина серии, дельта-кодирование и кодирование Хаффмана
Все шаги сжатия до сих пор выполнялись с потерями. Этот последний слой, напротив, не содержит потерь. Он не удаляет никакой информации, но значительно уменьшает размер файла.
Как сжать что-нибудь, не выбрасывая информацию? Подумайте, как бы вы изобразили простое сплошное черное изображение.
JPEG использует около 5000 чисел, чтобы представить это, но мы можем сделать это намного лучше. Можете ли вы придумать схему кодирования для представления этого изображения с использованием как можно меньшего количества байтов?
Наименьшее, что я мог придумать, было четыре байта: три байта для указания цвета и один для указания количества пикселей этого цвета. Идея краткого выражения всех повторяющихся значений таким способом называется кодированием длин серий . Это без потерь, потому что мы можем восстановить закодированные данные точно так, как это было раньше.
Размер файла сплошного черного изображения JPEG намного превышает четыре байта, потому что помните, что на уровне DCT сжатие применяется к блокам 8x8 за раз. Таким образом, нам потребуется как минимум один коэффициент DCT для каждого блока из 64 пикселей. Нам нужен только один, потому что вместо хранения одного DCT-коэффициента, за которым следуют 63 нуля для этого изображения, кодирование длин серий позволяет нам просто сохранить одно число и сказать «остальные равны нулю».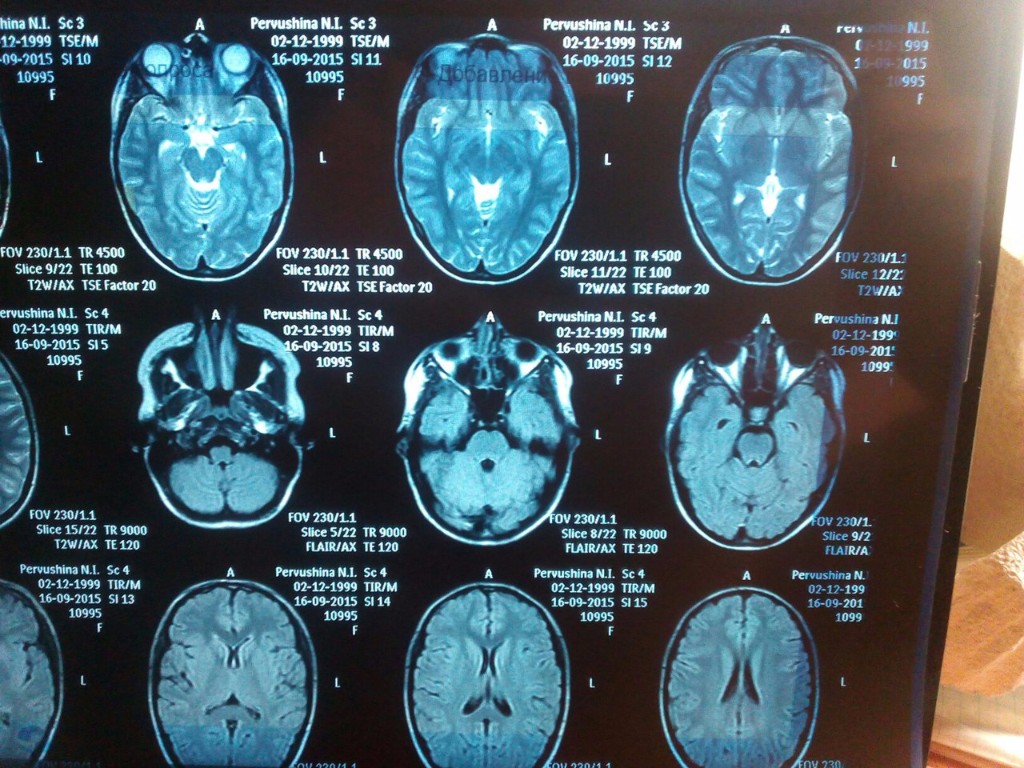
Дельта-кодирование - это метод сохранения каждого байта как относительного значения по сравнению с чем-то до него вместо сохранения его абсолютного значения.Это причина, по которой редактирование определенных байтов изменит цвет всех последующих пикселей. Например, вместо сохранения:
12 13 14 14 14 13 13 14 Вы бы начали с 12, а оттуда просто запомните, сколько вам нужно добавить или вычесть, чтобы получить следующее число. Таким образом, после дельта-кодирования приведенная выше последовательность становится:
12 1 1 0 0 -1 0 1 Еще раз, преобразованные данные не меньше исходных, но более сжимаемые.Применение дельта-кодирования до длины прогона может очень помочь, оставаясь при этом этапом сжатия без потерь.
Дельта-кодирование - один из немногих методов, который применяется за пределами блоков 8x8. Из 64 коэффициентов DCT первый - это просто постоянная волновая функция (вы видите его сплошным цветом). Он представляет собой среднюю яркость каждого блока для компонентов яркости или среднюю голубизну для компонентов Cb и т. Д. Это первое значение в каждом блоке DCT называется значением DC, и каждое значение DC кодируется дельта относительно предыдущих значений. .Таким образом, изменение яркости самого первого блока повлияет на все блоки изображения.
Он представляет собой среднюю яркость каждого блока для компонентов яркости или среднюю голубизну для компонентов Cb и т. Д. Это первое значение в каждом блоке DCT называется значением DC, и каждое значение DC кодируется дельта относительно предыдущих значений. .Таким образом, изменение яркости самого первого блока повлияет на все блоки изображения.
Все это оставляет одну последнюю загадку: как изменение всего лишь одного числа может полностью испортить изображение? Пока это не было свойством ни одного из слоев сжатия. Ответ кроется в заголовке JPEG. Это первые 500 или около того байтов, которые содержат метаданные об изображении, такие как его ширина и высота, и до сих пор не были включены во все редакторы байтов.
Ниже исходное изображение с заголовком.
Без заголовка практически невозможно (или, по крайней мере, очень сложно) декодировать изображение JPEG. Это было бы так, как если бы я пытался описать вам картину и начал придумывать слова, чтобы передать то, что я видел. Вероятно, это будет очень краткое описание, поскольку я могу определить слова, которые означают именно то, что я хочу сообщить, но это будет бессмысленно для кого-либо, кроме меня.
Вероятно, это будет очень краткое описание, поскольку я могу определить слова, которые означают именно то, что я хочу сообщить, но это будет бессмысленно для кого-либо, кроме меня.
Это может показаться нелепым, но именно это здесь и происходит. Каждое изображение JPEG сжимается с помощью кода, специфичного для этого конкретного изображения.Эти коды определены в словаре, хранящемся в заголовке. Этот метод называется кодированием Хаффмана , а словарь называется таблицей Хаффмана. Эта таблица отмечена в заголовке двумя байтами: 255, за которыми идет 196. Каждый компонент цвета может иметь свою собственную таблицу Хаффмана.
Изменения в этих таблицах Хаффмана окажут наиболее сильное влияние на любое изображение. Хорошим примером является изменение второй 1 на 12 в строке 15. Изменение чего-либо после 125 в этой строке тоже работает.
Таблицы Хаффмана оказывают такое сильное влияние на изображение, потому что они говорят нам, как читать отдельные биты. До сих пор мы имели дело только с двоичными числами в десятичной системе счисления. Это скрывает тот факт, что если вы хотите сохранить число 1 в байте, оно будет выглядеть как 00000001 , потому что каждый байт должен иметь ровно восемь бит, даже если ему нужен только один бит.
До сих пор мы имели дело только с двоичными числами в десятичной системе счисления. Это скрывает тот факт, что если вы хотите сохранить число 1 в байте, оно будет выглядеть как 00000001 , потому что каждый байт должен иметь ровно восемь бит, даже если ему нужен только один бит.
Это потенциально огромная трата памяти, если у вас много маленьких номеров. Кодирование Хаффмана - это метод, который позволяет нам ослабить требование, согласно которому каждое число должно занимать восемь бит. Это означает, что если вы видите два байта:
234 115 На основе таблицы Хаффмана это может быть три значения.Чтобы извлечь их, вам нужно сначала разбить их на отдельные биты:
11101010 01110011
Используя эти знания, вы можете сделать один изящный трюк - вырезать заголовок из изображения JPEG и сохранить его отдельно. По сути, вы делаете это так, чтобы только вы могли его прочитать. Facebook на самом деле делает это, чтобы делать изображения JPEG еще меньше.
Еще одна вещь, которую вы можете сделать, - это немного изменить таблицу Хаффмана. Для кого-то еще это выглядит как испорченный образ. Но только вы знаете, какое волшебное редактирование необходимо, чтобы исправить это.
Затем следуйте таблице, чтобы выяснить, как их сгруппировать. Например, это могут быть первые шесть бит (111010), то есть 58 в десятичной системе, за которыми следуют еще пять бит (10011), то есть 19, и, наконец, последние четыре бита (0011), то есть три.
Вот почему очень трудно разобраться в байтах на этом уровне сжатия. Байты на самом деле не представляют то, что они представляют. Я не буду вдаваться в подробности того, как извлечь таблицу Хаффмана и перевести биты в этой статье, но есть много хороших ресурсов по этому поводу, если вам интересно.Итак, чтобы подвести итог, что всего нужно для декодирования изображения JPEG? Вам необходимо:
- Извлечь таблицу (ы) Хаффмана из заголовка и декодировать биты.
- Извлеките коэффициенты дискретного косинусного преобразования для каждого компонента цвета / яркости для каждого блока 8x8, отменив кодирование длины серии и дельта.

- Объедините косинусные волны на основе коэффициентов, чтобы вернуть значения пикселей для каждого блока 8x8 (это известно как обратное дискретное косинусное преобразование).
- Увеличьте масштаб компонентов цветности, если они были субдискретизированы (эта информация содержится в заголовке).
- Преобразует результирующий YCbCr каждого пикселя в RGB.
- Покажите изображение!
Чтобы просмотреть простую картинку с кошкой, потребуется много труда! Но что мне нравится в этом, так это то, что вы можете видеть, насколько технология JPEG ориентирована на человека. Он полагается на причуды нашего восприятия для достижения гораздо большей степени сжатия, чем это возможно с помощью методов общего назначения. И теперь, когда вы понимаете, как работает JPEG, вы можете представить, сколько из этих методов можно распространить на другие области.Например, применение дельта-кодирования к видео может привести к значительному уменьшению размера файла, поскольку часто есть области, которые вообще не меняются между кадрами (например, фон).
Весь код для этой статьи имеет открытый исходный код и включает инструкции по замене изображений в этих байтовых редакторах на свои собственные.
Омар Шехата - программист графики в Cesium, работающий над 3D-картами с открытым исходным кодом в Интернете. Он вырос в Александрии, Египет, и в настоящее время живет в Филадельфии, штат Пенсильвания.
Отредактировали Мэтью Конлен и Виктория Урен.
Прочтите следующую статью
Миф о беспристрастной машине
→
Декодирование изображений - SpinetiX Support Wiki
Введение
Проигрыватель изначально поддерживает следующие форматы изображений:
Другие типы изображений (BMP, BPG, ICO, PBM, TIF, WebP и т. Д.) Не поддерживаются проигрывателем и должны быть преобразованы в форматы, указанные выше. Это делается прозрачно при импорте этих изображений в Elementi / HMD; при обходе механизма импорта требуется ручное преобразование, в противном случае изображение не отображается на экране (вместо него отображается синий x ).
Форматы
JPEG
JPEG - это широко используемый метод сжатия цифровых изображений с потерями, особенно изображений, созданных цифровой фотографией. Степень сжатия можно регулировать, что позволяет выбирать компромисс между размером хранилища и качеством изображения. JPEG обычно обеспечивает сжатие 10: 1 с незначительной потерей качества изображения.
JPEG лучше всего подходит для фотографий и картин с реалистичными сценами с плавными вариациями тона и цвета.JPEG / Exif также является наиболее распространенным форматом, сохраняемым цифровыми камерами. С другой стороны, JPEG может не так хорошо подходить для штриховых рисунков и другой текстовой или графической графики, где резкие контрасты между соседними пикселями могут вызвать заметные артефакты. Такие изображения лучше сохранять в графическом формате без потерь, таком как PNG.
Термин «JPEG» является аббревиатурой от «Joint Photographic Experts Group», которая создала стандарт. Файлы JPEG обычно имеют расширение .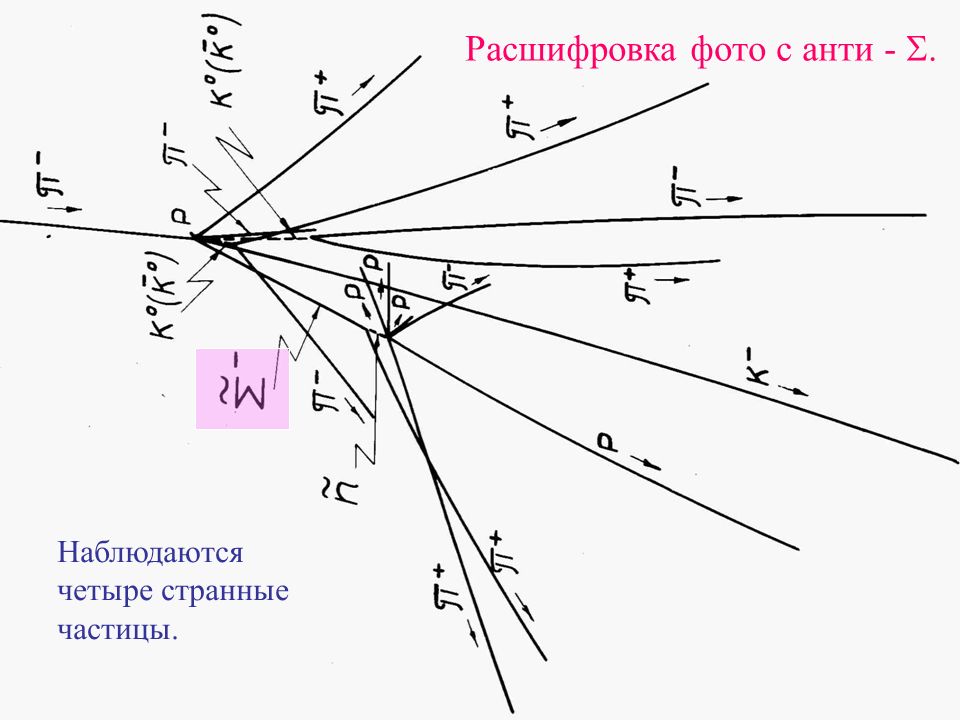 jpg или.jpeg.
jpg или.jpeg.
Банкноты
- HMP поддерживает изображения JPEG с одним (с оттенками серого) или тремя компонентами (YCbCr или RGB).
- Рекомендуемый формат - YcbCr 4: 2: 0.
PNG
Portable Network Graphics (PNG) - это формат файлов растровой графики, который поддерживает сжатие данных без потерь и предлагает множество вариантов прозрачности. PNG был создан как улучшенная, не запатентованная (бесплатная, с открытым исходным кодом) замена формата обмена графическими данными (хотя GIF сам теперь свободен от патентов), а также может заменить многие распространенные варианты использования TIFF.
PNG - наиболее часто используемый в Интернете формат сжатия изображений без потерь. PNG был разработан для передачи изображений в Интернете, а не для печати графики профессионального качества, и поэтому не поддерживает цветовые пространства, отличные от RGB, такие как CMYK. Формат PNG разработан для работы в приложениях для просмотра в Интернете, таких как веб-браузеры, и его можно полностью транслировать с помощью опции прогрессивного отображения. PNG является надежным, обеспечивая как полную проверку целостности файла, так и простое обнаружение распространенных ошибок передачи.
PNG является надежным, обеспечивая как полную проверку целостности файла, так и простое обнаружение распространенных ошибок передачи.
По сравнению с JPEG, PNG лучше, если изображение имеет большие однородные по цвету области. Даже для фотографий - где JPEG часто является выбором для окончательного распространения, поскольку его метод сжатия обычно дает файлы меньшего размера, PNG по-прежнему хорошо подходит для хранения изображений во время процесса редактирования из-за его сжатия без потерь. По сравнению с GIF формат файла PNG поддерживает восьмибитные изображения на основе палитры (с дополнительной прозрачностью для всех цветов палитры) и 24-битный истинный цвет (16 миллионов цветов) или 48-битный истинный цвет с альфа-каналом и без него, тогда как GIF поддерживает только 256 цветов и один прозрачный цвет.
Файлы PNG почти всегда используют расширение PNG или png, и им присваивается тип мультимедиа MIME image / png.
Банкноты
Вот некоторые примечания об использовании изображений PNG в плеере:
- Сжатие
- Уровень сжатия не влияет на время рендеринга, за исключением случая, когда он установлен на 0 (что отключает алгоритм deflate).
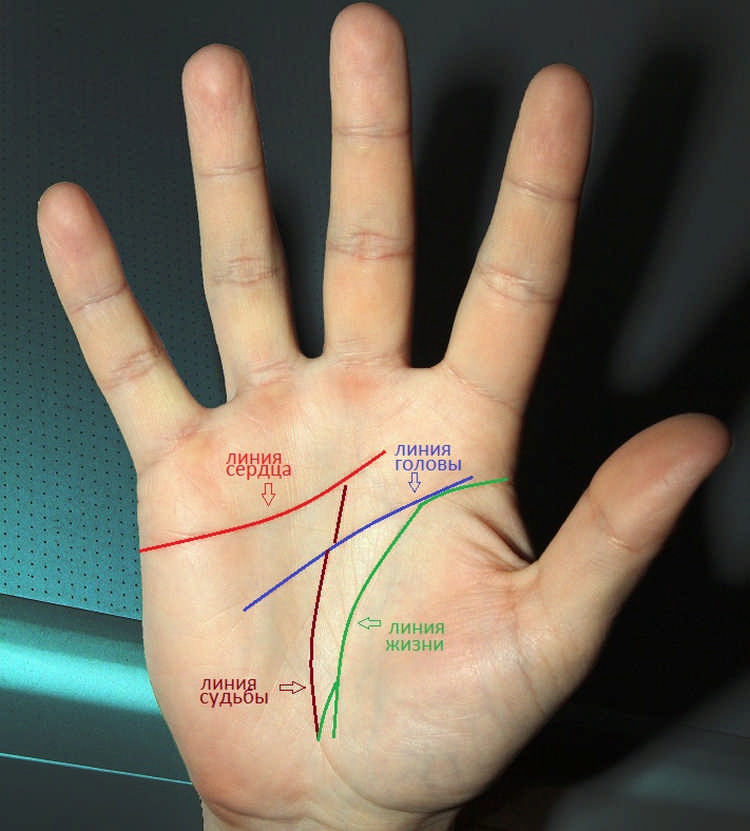
- Настоятельно не рекомендуется использовать 0, так как это приведет к созданию огромных файлов, которые потребуют больше времени на рендеринг и усложнят публикацию контента, при этом не будут иметь никакого преимущества с точки зрения визуального качества.Это также может сделать файл настолько большим, что он превысит максимальный размер файла, поддерживаемый плеером (~ 2 МБ).
- При импорте файла PNG в Elementi и отключении deflate, файл будет автоматически повторно сжат с включенным deflate для экономии места.
- Обычно при установке уровня сжатия на 9 создается файл небольшого размера без потерь за счет большего времени сжатия (но не времени рендеринга!). Тем не менее, этот параметр не обязательно гарантирует лучший размер, и другие значения могут быть лучше; Если ваша цель - максимальное сжатие, используйте такой инструмент, как pngcrush, который выберет наилучшие настройки.
- Уровень сжатия не влияет на время рендеринга, за исключением случая, когда он установлен на 0 (что отключает алгоритм deflate).
- Глубина цвета
- Рекомендуемые форматы (наилучшая производительность):
- Оттенки серого: 8 бит на канал -> 8 бит на пиксель
- Оттенки серого с альфа-каналом: 8 бит на канал -> 16 бит на пиксель
- Truecolor: 8 бит на канал -> 24 бит на пиксель
- Truecolor с альфа-каналом: 8 бит на канал -> 32 бит на пиксель
- Разница во времени рендеринга для вышеуказанного незначительна, если было применено сжатие.
 Выбор формата цвета должен основываться на ваших требованиях: если вам нужен цвет, используйте 24 бит на пиксель, если вам нужны только оттенки серого, используйте 8 бит на пиксель.
Выбор формата цвета должен основываться на ваших требованиях: если вам нужен цвет, используйте 24 бит на пиксель, если вам нужны только оттенки серого, используйте 8 бит на пиксель. - Индексированный цветовой формат поддерживается как устаревший, но не рекомендуется, поскольку он обычно не обеспечивает визуальные потери без потерь, а другой формат с потерями, такой как JPEG, даст лучшее качество для того же размера. Если ваши изображения черно-белые, используйте формат градаций серого, а не индексированные цвета. Изображения
- PNG с глубиной цвета, установленной на 16 бит на канал ( не на пиксель! ), при импорте подвергаются понижающей дискретизации до 8 бит на канал.
- Рекомендуемые форматы (наилучшая производительность):
- Чередование
- Файлы PNG с чересстрочной разверткой / Adam7 поддерживаются в устаревших целях.Настоятельно не рекомендуется использовать чересстрочную развертку, поскольку она снижает эффективность сжатия (больший размер файла) и увеличивает время рендеринга, но не дает улучшения качества изображения.

- Файлы PNG с чересстрочной разверткой / Adam7 поддерживаются в устаревших целях.Настоятельно не рекомендуется использовать чересстрочную развертку, поскольку она снижает эффективность сжатия (больший размер файла) и увеличивает время рендеринга, но не дает улучшения качества изображения.
- Информация о гамма-коррекции
- Информация о коррекции гаммы игнорируется плеером, поэтому лучше не указывать ее.
- Типы фильтров
- Поддерживаются все типы фильтров (например, None, Sub, Up, Average, Path, Adaptive). Нет никакой разницы во времени декодирования из-за самого предсказания; однако лучший прогноз дает файлы меньшего размера, а файлы меньшего размера декодируются быстрее.Рекомендуется использовать адаптивную фильтрацию, чтобы компрессор выбрал наилучшую настройку.
GIF
GIF (формат обмена графическими данными) наиболее подходит для хранения графики с небольшим количеством цветов (до 256 цветов), например простых диаграмм, фигур, логотипов и изображений в мультяшном стиле, поскольку в нем используется сжатие без потерь LZW, которое более эффективно при больших размерах. области имеют один цвет и менее эффективны для фотографических или размытых изображений. Благодаря своим возможностям анимации, он по-прежнему широко используется для создания эффектов анимации изображений, несмотря на низкий коэффициент сжатия по сравнению с современными видеоформатами.
Благодаря своим возможностям анимации, он по-прежнему широко используется для создания эффектов анимации изображений, несмотря на низкий коэффициент сжатия по сравнению с современными видеоформатами.
Банкноты
Несмотря на то, что проигрыватель может декодировать изображения в формате GIF, этот формат не рекомендуется из-за его ограниченного использования.
- Elementi автоматически конвертирует неанимированные изображения GIF в формат PNG при импорте файла, но разрешает использование анимированных изображений GIF.
- Инструмент создания содержимого проигрывателя отклоняет все изображения в формате GIF.
- Fusion допускает все изображения в формате GIF, но поддерживается только частично.
SVG
Scalable Vector Graphics (SVG) - это открытый стандарт, созданный и разработанный Консорциумом World Wide Web для удовлетворения потребности в универсальном, универсальном векторном формате с поддержкой сценариев для Интернета и других областей. Это формат векторного изображения на основе XML для двухмерной графики с поддержкой интерактивности и анимации.
Это формат векторного изображения на основе XML для двухмерной графики с поддержкой интерактивности и анимации.
Изображения SVG и их поведение определяются в текстовых файлах XML; это означает, что их можно искать, индексировать, создавать сценарии и сжимать. Как файлы XML, изображения SVG можно создавать и редактировать с помощью любого текстового редактора, но чаще создаются с помощью программного обеспечения для рисования, такого как Inkscape, Adobe Illustrator, CorelDRAW и т. Д.
Банкноты
Особые случаи
Большие изображения
В настоящее время очень часто можно найти (очень) большие изображения - большинство фотоаппаратов / смартфонов способны создавать изображения размером более 1920 x 1080 пикселей - но хорошо ли использовать эти большие изображения такими, какие они есть?
Короткий ответ - НЕТ, потому что максимальное разрешение проигрывателя составляет 1080p, поэтому все, что выше, будет пустой тратой ресурсов игрока.Решения?
- Всегда лучше уменьшить их размер с помощью специального инструмента (например, GIMP, Photoshop и т.
 Д.), Который даст результаты наилучшего качества.
Д.), Который даст результаты наилучшего качества. - Если это невозможно, знайте, что такие изображения автоматически уменьшаются в размере после импорта в Elementi или загрузки в инструмент создания контента проигрывателя, чтобы полностью уместить область экрана.
- Обратите внимание, что в случае многоэкранного содержимого Elementi 2015 или более поздней версии не будет уменьшать размер изображения, но создаст многоэкранное изображение, которое используется для отображения импортированного изображения с полным разрешением на нескольких экранах.
Если такое большое изображение попадет на проигрыватель, он попытается уменьшить его на лету при рендеринге, но этого следует избегать ( см. Почему ниже ).
Несколько изображений
Другой случай, который следует рассмотреть, - это когда на экране одновременно отображается несколько изображений. Как описано выше, большие изображения уменьшаются, но только для того, чтобы полностью уместить область экрана - что хорошо, если изображение используется в качестве фона или в списке воспроизведения, но что происходит, когда несколько изображений отображаются в строке в одной и той же сцене? Что ж, игроку придется уменьшать размер этих изображений на лету при рендеринге, что не рекомендуется ( см. Ниже, ниже ).
Ниже, ниже ).
Хороший способ - уменьшить размер этих изображений перед их использованием, чтобы уменьшить потребление памяти.
- Например, если вы хотите отображать 10 изображений подряд на проигрывателе, установленном на 1080p (1920x1080), то размер изображений следует изменить так, чтобы ширина не превышала 192 пикселей.
Уменьшение размера изображения
Если проигрывателю необходимо визуализировать определенное изображение с меньшим размером, чем исходное, то он будет уменьшать это изображение на лету.Однако это не рекомендуется по причинам качества и производительности:
- Качество полученного изображения хуже, чем при использовании специального инструмента для изменения размера - HMP просто разделит размер изображения на два, в то время как приложения, такие как GIMP, Photoshop и т. Д., Используют оптимизированные алгоритмы для этой операции, таким образом, с лучшим качеством в результате.
- На производительность HMP влияет то, что HMP должен выделить память для всего изображения, чтобы декодировать его, а затем он уменьшит его.
 Например, проигрыватель будет использовать 4,8 МБ памяти для изображения 1920x1280 без прозрачности (в противном случае - в два раза), в то время как на экране изображение может фактически отображаться как 192x128 пикселей (уменьшено в 10 раз!), Таким образом тратя ресурсы проигрывателя.
Например, проигрыватель будет использовать 4,8 МБ памяти для изображения 1920x1280 без прозрачности (в противном случае - в два раза), в то время как на экране изображение может фактически отображаться как 192x128 пикселей (уменьшено в 10 раз!), Таким образом тратя ресурсы проигрывателя. - Если размер изображения меньше 11184810 пикселей для JPEG и 4194304 пикселей для PNG и GIF, проигрыватель должен отбросить изображение и вместо этого показать синий x , но не перезагружаться. Если изображение больше, проигрыватель, вероятно, перезагрузится и перейдет в безопасный режим
Устранение неполадок
- Вместо изображения отображается синий x .
- Это происходит, когда изображение выходит за рамки спецификаций проигрывателя - обычно потому, что изображение поступает из внешнего источника (как это может быть в случае с виджетами, управляемыми данными) и, таким образом, оно не прошло через механизм импорта Elementi.
- Изображение JPEG не отображается, и это предупреждающее сообщение: Невозможно декодировать ресурс JPEG (поддерживаются только 1 или 3 компонента) можно найти в player.
 log.
log.
- Это происходит, когда используется изображение JPEG, использующее 4-компонентное цветовое пространство (например, YCCK) - в таких случаях изображение не отображается на экране.Elementi обычно конвертирует такие изображения в правильный формат, но в противном случае требуется ручное преобразование.
Зашифровать или расшифровать изображение
Шифрование изображения • Расшифровка изображения • Предостережения относительно шифрования и дешифрования
Большинство изображений изначально созданы для того, чтобы их просматривали часто и многие люди. Веб-изображения, например, могут просматриваться сотни раз в день множеством посетителей. Однако в некоторых случаях вам может потребоваться сохранить конфиденциальность определенного изображения, чтобы его могли просматривать только вы или, возможно, избранная группа ваших друзей или посетителей Интернета.ImageMagick позволяет вам зашифровать ваши изображения так, что, если кто-то не знает вашу кодовую фразу, они не смогут просмотреть исходный контент.
Вы можете использовать утилиту шифрования для шифрования вашего изображения, но они обычно шифруют весь файл, делая его нераспознаваемым как формат изображения. С ImageMagick шифруются только пиксели. Зашифрованное изображение по-прежнему распознается как изображение и даже будет отображаться на вашей веб-странице. Однако содержимое выглядит бессмысленно, совсем не так, как исходное.
Зашифровать изображение
Используйте параметр -encipher, чтобы зашифровать изображение до неузнаваемости. Эта опция требует имени файла, содержащего вашу парольную фразу. В этом примере мы шифруем изображение и сохраняем его в формате PNG:
magick rose.jpg -encipher passphrase.txt rose.png
Здесь мы зашифровываем изображение, используя другое изображение в качестве ключевой фразы:
magick rose.jpg -шифрование smiley.gif rose.png
Расшифровать изображение
Используйте опцию -decipher, чтобы расшифровать изображение, чтобы оно снова стало узнаваемым.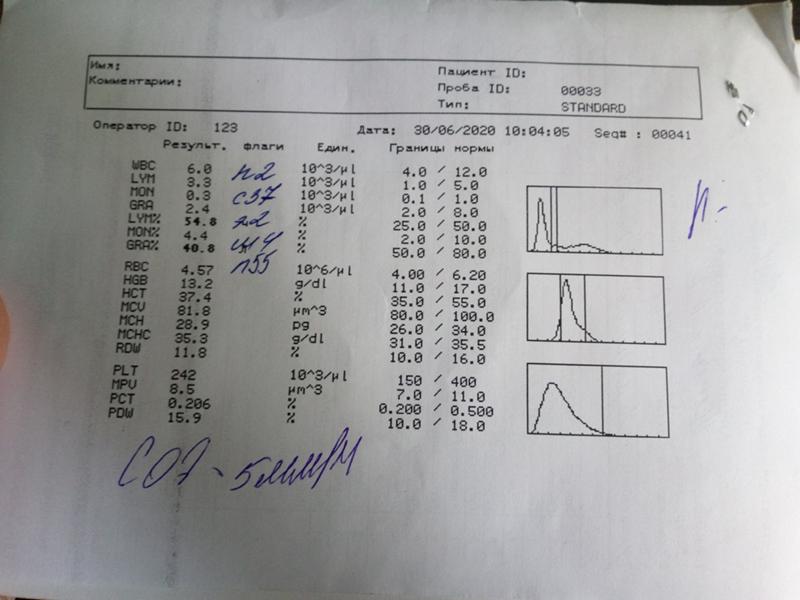 Эта опция требует имени файла, содержащего вашу парольную фразу. В этом примере мы расшифровываем изображение и сохраняем его в формате JPEG:
Эта опция требует имени файла, содержащего вашу парольную фразу. В этом примере мы расшифровываем изображение и сохраняем его в формате JPEG:
magick rose.png -decipher passphrase.txt rose.jpg
Предостережения относительно шифрования и дешифрования
Некоторые форматы не поддерживают зашифрованные пиксели - формат JPEG или GIF, для пример. Чтобы убедиться, что ваш формат изображения поддерживается, зашифруйте тестовое изображение и убедитесь, что вы можете восстановить исходное содержимое , прежде чем вы зашифруете дополнительные изображения в этом формате.
Формат изображения может поддерживать только 8-битный и RGB (TrueColor). Таким образом, вы можете хотелось бы включить параметры "-depth 8 -type TrueColor" перед выводом имя файла.
Парольная фраза может быть любой комбинацией букв и символов. Должно
должно быть не менее 12 комбинаций символов, чтобы сохранить изображение
частный. Также убедитесь, что права доступа к файлу парольной фразы не позволяют другим
читая его, в противном случае непреднамеренные пользователи могут просмотреть исходное изображение
содержание.
Вы можете восстановить исходное содержимое изображения, только если знаете кодовая фраза. Если вы его потеряете или забудете, исходное содержимое изображения будет потеряно. навсегда.
ImageMagick шифрует только пиксели изображения. Метаданные изображения остаются нетронутой и доступной для чтения всем, у кого есть доступ к файлу изображения.
ImageMagick использует AES шифр в режиме счетчика. Мы используем первую половину вашей ключевой фразы для получения одноразового номера. Вторая половина - это ключ шифра. При правильном использовании AES-CTR обеспечивает высокий уровень конфиденциальности.Чтобы избежать утечки информации, вы должны использовать новую парольную фразу для каждого зашифрованного изображения.
В настоящее время только ImageMagick может восстановить содержимое зашифрованного изображения. Мы использовать стандартный шифр и режим, чтобы другие поставщики могли поддерживать содержимое зашифрованного изображения.
Некоторые небольшие практические примеры шифрования изображений можно найти в IM.