Сделать чёрно-белое фото цветным | Блог Барышням
О том, как сделать фотографию чёрно-белую — цветной, я уже писала в этой статье. Но есть и другие онлайн-сервисы и программы для ПК, которые делают эту же операцию. Те, что с автоматической обработкой, я протестировала, и сегодня напишу о них обзор. Тестировать буду вот такое фото:
Онлайн сервисы
9may
https://9may.mail.ru/
Сервис бесплатный. Пользоваться им просто, загружаете фото, ждёте автоматическую обработку 1-2 минуты и фото готово.
Результат:
Студия Арт Лебедев
https://color.artlebedev.ru/
Бесплатная автоматическая обработка. От вас требуется только загрузить фото.
Результат:
Colorize
https://colorize.cc/
Сайт платный. Обрабатывает фото автоматически. Бесплатно фото можно обработать, на на изображении будет водяной знак.
Playback
https://playback. fm/colorize-photo
fm/colorize-photo
Ресурс бесплатный. Обработка автоматическая.
Hdconvert
https://hdconvert.com/ru/convert_colorize_online.html
Сервис платный. Обрабатываются фотографии так же как и в предыдущих сервисах — автоматически.
Hotpot
https://hotpot.ai/colorize-picture
Сервис бесплатный. Раскрашивание автоматическое.
Image colorizer
https://imagecolorizer.com/colorize.html
Есть платный и бесплатный тариф. Окрашивание автоматическое.
Программы на пк
Movavi Picverse
Сайт https://www.movavi.ru
Программа платная. Есть пробная версия. Цвет накладывается автоматически.
Пример окрашивания в программе.
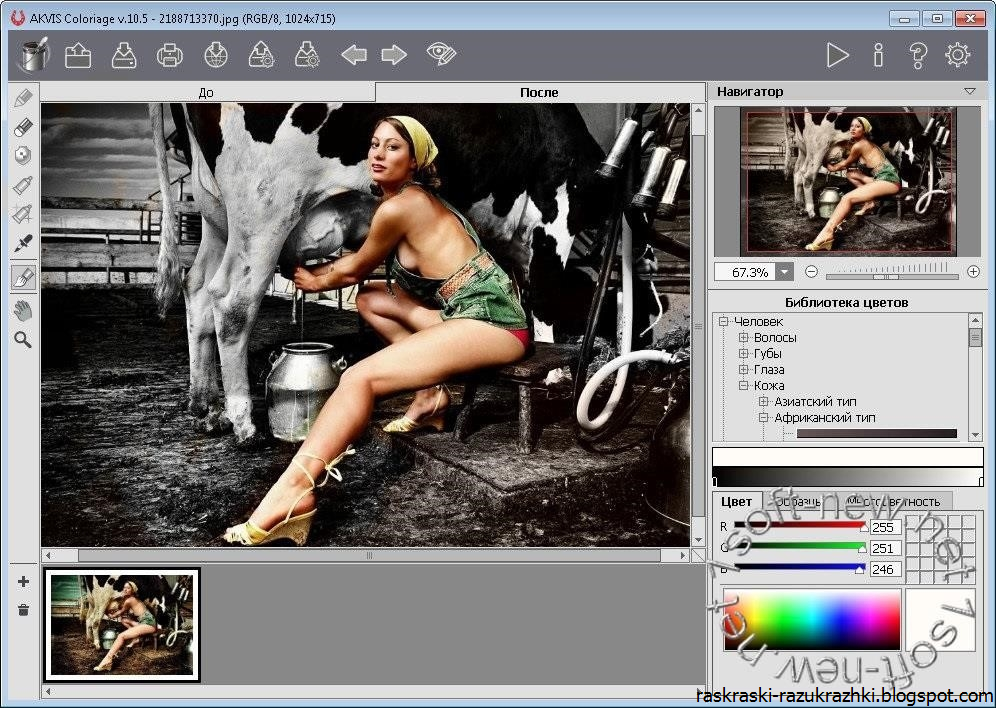
AKVIS Coloriage
Сайт — https://akvis.com/ru/coloriage/download-add-color.php
Программа платная, есть пробная версия. Раскрашивать нужно вручную. Принцип действия программы в простом нанесении цветных контуров или штрихов внутри тех объектов, которые необходимо окрасить. А утилита сама определит границы этих объектов.
А утилита сама определит границы этих объектов.
Урок по раскрашиванию — https://akvis.com/en/coloriage-tutorial/howwork/howwork.php
Фотовинтаж
https://fotovintage.ru/kolorizaciya-foto.php
Программа платная, имеется пробная версия.
На фото ничего не окрасилось и программа предложила раскрасить всё вручную.
Recolored
Официального сайта нет, но программу можно найти по запросу в интернете. Утилита платная, бесплатно использовать можно 21 день. Окраска фото вручную.
Photo-Colorizer
https://www.cadkas.com/downenggraphic4.php
Раскрашивалка черно-белых фотографий. Раскрашивать фото нужно вручную. В программе имеются цвета для кожи, неба, реки, песка и т.д. Можно изменить цвета и на цветных фотографиях.
Можно раскрашивать фотографии в ручную, если умеете пользоваться такими программами как, Фотошоп, Gimp и т.п. Уроки раскрашивания можно найти в интернете в поисковиках. В Фотошопе последних версий есть и автоматическая раскраска чёрно-белых фото.
Приложения для смартфонов
- Clrzr
- Spectrum
- Colorize it
- Colorize Images
- Colorize от Photomyne
- B&W Colorizer – Color Images
- Photo Colorizer AI -B&W Photos
- Black and White Photo Colorizer-Chromatix
- Colorize Color to Old Photos
- Hypocam
- BlackCam
и многие другие.
И напоследок, необычный автоматический раскрашиватель:
Petalica paint
https://petalica-paint.pixiv.dev/index_en.html
На ресурсе можно окрасить любую чёрно-белую раскраску или картинку. Нужно только ставить цветные отметки на деталях изображения. Картинки получаются сказочные.
Как раскрасить чёрно-белые фото (Фотошоп и ещё 3 варианта)
#Реклама, Фото уроки
- Опубликовано
17 Май
Возможность создавать цветные фотографии появилась в начале 20 столетия. В нашей стране технология обрела популярность только в 90х годах. Многие семейные фотоальбомы хранят памятные черно-белые снимки, которые были сделаны около полувека назад. Фотографии старого образца обладают особыми ценностями и способны вызвать вспышку воспоминаний и ностальгии.
В нашей стране технология обрела популярность только в 90х годах. Многие семейные фотоальбомы хранят памятные черно-белые снимки, которые были сделаны около полувека назад. Фотографии старого образца обладают особыми ценностями и способны вызвать вспышку воспоминаний и ностальгии.
Черно-белые снимки по сегодняшний день не выходят из моды. Современные фотографы часто оформляют свои работы в черно-белых тонах, так как это дарит снимку особую атмосферу. Такие работы можно отнести к стилю ретро.
Несмотря на это, у многих возникает желание превратить черно-белый снимок в цветное изображение. В данном материале расскажем как это можно сделать.
Метод ручной раскраски
Этот способ считается одним из самых первых вариантов раскраски. До появления цифровых технологий, художники разукрашивали фотографии масляными красками и другими средствами профессионального ретуширования. Оригинальный снимок с помощью таких действий приобретает не только цветовую гамму, но и воспринимается по-новому. Методика раскраски изображения вручную представляет интерес только с точки зрения художественного искусства, так как на смену пришли усовершенствованные компьютерные технологии, которые позволяют выполнить раскраску любой сложности.
Методика раскраски изображения вручную представляет интерес только с точки зрения художественного искусства, так как на смену пришли усовершенствованные компьютерные технологии, которые позволяют выполнить раскраску любой сложности.
Ручную раскраску можно сделать на компьютере с помощью специальной программы Colorize Photo Converter. Это фоторедактор любительского образца, который запускается через интернет-браузер. Он дает возможность раскрашивать цифровые черно-белые фотографии посредством подбора цветов с любого изображения, загруженного пользователем, или выбранного из представленных в программе. Такой вариант раскраски подойдет для снимков, которые не перенасыщены мелкими деталями. Мелкие детали требуют более профессионального подхода к обработке. Программа является отличным вариантом для раскраски портретных снимков.
Для создания цифрового формата снимка используйте сканер или услуги фотосалонов.
Алгоритм нейросетей
Приложения такого формата работают на базе технологий искусственного интеллекта, нейронных сетей и машинного обучения.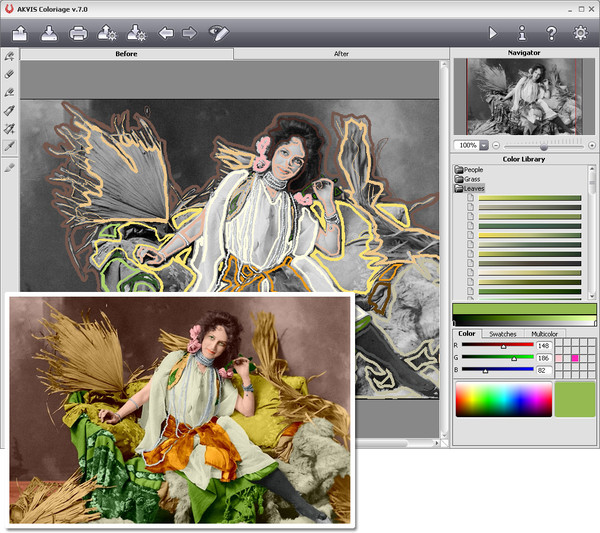 Это современный подход, который набирает все больше популярности с каждым днем. На многих интернет-ресурсах и мобильных приложений можно найти большой выбор фоторедакторов для профессиональной обработки снимков. Они оснащены большим спектром инструментов и возможностей.
Это современный подход, который набирает все больше популярности с каждым днем. На многих интернет-ресурсах и мобильных приложений можно найти большой выбор фоторедакторов для профессиональной обработки снимков. Они оснащены большим спектром инструментов и возможностей.
Большинство таких редакторов предлагают разнообразные фильтры, наиболее подходящие для обработки цветных фотографий. Программ для автоматического превращения черно-белых снимков в цветные не много. Большинство таких программ имеют похожий алгоритм действия. С помощью искусственного интеллекта, который изучает изображения, создается коррекция цветовой палитры изображения.
Самым популярным сервисом для раскраски черно-белых фотографий является Algorithmia Colorize Photos. Создателями программы стали ученые из Университета в Калифорнии. По сегодняшний день программа работает в тестовом режиме.
Работа в сервисе очень проста. Достаточно ввести адрес на изображение в необходимое поле или загрузить снимок из галереи. Иногда процесс колористики запускается автоматически. В течении 5-30 секунд пользователь получит фотографию с двух частей – цветной и черно-белой фотографии.
Иногда процесс колористики запускается автоматически. В течении 5-30 секунд пользователь получит фотографию с двух частей – цветной и черно-белой фотографии.
Еще одной программой, которая исполняет такую функцию является приложение Colorize Photos for Free. В этой программе стоит ограничение на размер загружаемого изображения – 15 Мегабайт. В программе можно регулировать уровень колористики. Чем выше показатель, тем ярче цветовое изображение. Программа осуществляет процесс раскраски с помощью машинной технологии.
Цифровые фоторедакторы
Стоит отметить, что у приложений, работающих на основе ИИ и машинных обучений, имеется множество недостатков. Изображения могут быть окрашены неточно или не полностью. В программах нету параметров, с помощью которых можно корректировать результат.
Если вы не довольны результатом работы таких программ, тогда на помощь придет графический фоторедактор. Самым популярным и многофункциональным считается программа Adobe Photoshop. Такие редакторы предусматривают работу со слоями изображения. На каждый слой накладывается раскраска определенной области изображения. Каждый слой можно раскрасить по желанию, затем слои накладываются друг на друга и пользователь получает результат.
Такие редакторы предусматривают работу со слоями изображения. На каждый слой накладывается раскраска определенной области изображения. Каждый слой можно раскрасить по желанию, затем слои накладываются друг на друга и пользователь получает результат.
Процесс такой обработки требует детального изучения. Он похож на раскраску в ручную, но совершается на компьютере.
Есть много специалистов, которые занимаются оказанием услуг по обработке фотографий в профессиональных фоторедакторах. Заказать обработку фото можно у через интернет у фрилансеров, цены начинаются от 300 руб за одно фото.
Искусство колоризации
Ретушь снимков с помощью цифровых технологий мало в чем отличается от ручной раскраски живых фотографий. Алгоритмы сетей и машин работают с помощью угадывания реального вида объектов. Хороший результат такой работы получается далеко не всегда.
Работа с фоторедакторами на профессиональном уровне требует специальных знаний и практики. Обычно за такую работу принимаются только специалисты. Поэтому колористика изображений по сегодняшний день остается искусством, которое предусматривает индивидуальный подход к каждой детали на картинке. Обработка фотографий в фоторедакторе происходит с учетом многих нюансов, таких как изначальное состояние фотографии, историю изображения и время создания снимка, механические повреждения и др. Такие детали позволяют подобрать наиболее подходящий способ устранения проблем и создания качественного цифрового изображения.
Поэтому колористика изображений по сегодняшний день остается искусством, которое предусматривает индивидуальный подход к каждой детали на картинке. Обработка фотографий в фоторедакторе происходит с учетом многих нюансов, таких как изначальное состояние фотографии, историю изображения и время создания снимка, механические повреждения и др. Такие детали позволяют подобрать наиболее подходящий способ устранения проблем и создания качественного цифрового изображения.
Работа такого характера является непростым процессом, с которым можно ознакомиться на сайте проекта Dynamicchrome. Рамки проекта создают оцифрованные фотохроники, которые представляют историческую ценность.
Заказать услугу по обработке черно-белых фотографий можно если пойти на сайт услуг за 500 руб, который предоставляет клиентам выполнение работ разного уровня сложности по доступным ценам.
Автоматическое раскрашивание черно-белых изображений с использованием техники машинного обучения «Автокодировщики» | Махмуд Эль-Джиддави
В этой статье я покажу вам основные шаги по раскрашиванию черно-белых изображений с помощью машинного обучения с помощью «Keras Tensorflow».
Прежде чем перейти к коду и деталям, давайте сначала обсудим проблему в целом, а по мере углубления я буду обсуждать с вами детали и код.
Первое, о чем вы должны подумать, когда дело доходит до решения проблемы, это определить вашу проблему, так что давайте начнем с определения проблемы.
Прежде чем ответить на этот вопрос, позвольте мне показать вам, из чего состоит изображение. Обычно изображение хранится в красных, зеленых, синих компонентах, они складываются вместе, чтобы сделать изображение, которое вы видите на своем компьютере, как вы видите ниже, единым изображение может быть разделено на исходные компоненты RGB .
канала RGB одного изображенияесли объединить их вместе, то в итоге вы увидите что-то точно такое, как на рисунке ниже.
Исходное изображение Теперь, вы знаете, из чего состоит изображение, вы не можете сгенерировать один канал, отвечающий за часть раскрашивания, в RGB цветовое пространство информация о раскрашивании находится внутри трех каналов, если какой-либо из этих каналов не существует, что уничтожит ваши цвета в изображении.
Основная проблема, заключающаяся в том, что у вас есть черно-белое изображение на входе, вы хотите сгенерировать три канала RGB компонентов этого черно-белого изображения на выходе. Теперь предположим, что у вас есть черно-белое изображение, вы помещаете его в черный ящик с левой стороны, после чего получаете три раскрашенных компонента 9.0009 RGB с правой стороны, но что это за черный ящик? ответ: «Автокодировщики».
По словам Яна «Гудфеллоу», изобретателя GAN, он описал автокодировщики в своей книге «Глубокое обучение» следующим образом:
Рисунок 1.1вывод. Внутри он имеет скрытый слой h , который описывает код, используемый для представления ввода. Сеть можно рассматривать как состоящую из двух частей: функция кодировщика h=f(x) и декодер, производящий реконструкцию r=g(h) . Эта архитектура представлена на рисунке 1.1.
Если автоэнкодеру удается просто научиться везде устанавливать g(f(x))=x , то он не особенно полезен. Вместо этого Auto-encoder разработан таким образом, чтобы он не мог научиться копировать идеально. Обычно они ограничены способами, которые позволяют им копировать только приблизительно и копировать только входные данные, которые напоминают обучающие данные. Поскольку модель вынуждена расставлять приоритеты, какие аспекты входных данных следует копировать, она часто изучает полезные свойства данных. Современный автокодер обобщил идею кодировщика и декодера за пределы детерминированных функций до стохастических отображений p энкодер (h|x) и p декодер (x|h) .
Традиционно Auto-encoder использовался для уменьшения размерности или изучения признаков. В последнее время теоретические связи между Auto-encoder и моделями скрытых переменных вывели Auto-encoder на передний план генеративного моделирования.
Автокодировщик можно рассматривать как частный случай сетей с прямой связью, и его можно обучать с использованием всех тех же методов, как правило, мини-пакетного градиентного спуска, следующего за градиентами, вычисленными путем обратного распространения.
Общая структура автокодировщика, отображающего вход x в выход (называемый реконструкцией) r посредством внутреннего представления или кода h. Автокодировщик состоит из двух компонентов: кодировщик f (сопоставление x с h) и декодер g (сопоставление h с r).
Как видите, мы можем использовать Auto-encoder для реконструкции изображения, другими словами, мы бы сказали, что у него есть возможность генерировать, и это именно то, что мы хотим сделать, мы хотим генерировать три канала из RGB .
Один из подходов состоит в том, чтобы сделать две копии вашего изображения, одна из которых будет изображением в градациях серого, и она будет действовать как ваш ввод для кодировщика, который отвечает за извлечение функций изображения «Представления скрытого пространства» , которые можно использовать в качестве входных данных для декодера для восстановления изображения, другая копия будет тем же изображением, но раскрашенным в соответствии с вашей целью для декодера (контролируемое обучение), чтобы он мог минимизировать ошибку между исходным цветным изображением и сгенерированным. Архитектура автокодировщика будет примерно такой, как на рисунке ниже.
Архитектура автокодировщика будет примерно такой, как на рисунке ниже.
Будет сверточная нейронная сеть ( CNN ) через часть кодировщика для извлечения признаков. в части декодера будут сверточные слои, подобные тем, что в кодере (с другими фильтрами), но за которыми следуют слои повышающей дискретизации для части реконструкции.
Цветное изображение RGB с копией его оттенков серого вы можете контролировать количество фильтров и слоев в каждом слое, конечно, последний слой должен содержать три фильтра, которые будут RGB каналов реконструированного изображения, но вы можете сделать кое-что поумнее. Что, если у вас есть другое цветовое пространство вместо RGB , которое может изолировать информацию о цвете от изображения? Это означает, что вы получите чисто черно-белую информацию об изображении в одном канале, а два других канала будут содержать информацию о цвете, встроенную в эти два канала. это кажется очень хорошей идеей и что такое LAB 9Цветовое пространство 0012 для вас.
это кажется очень хорошей идеей и что такое LAB 9Цветовое пространство 0012 для вас.
Существует множество цветовых пространств, таких как RGB, CMYK, Lab, XYZ, … легкость от цвета. Думайте о легкости как о каком-то изображении в градациях серого, у него есть только яркость, но совсем нет цветов. канал L отвечает за эту яркость (оттенки серого) а два других канала ab отвечают за цвета. как вы можете видеть на изображениях ниже, информация о цвете встроена в канал ab . Не глядя на L , вы можете заметить, что слишком сложно понять, что изображено на картинке, глядя на ab , и это из-за научного факта, который гласит, что 94% клеток в наших глазах определяют легкость. ( л ). Таким образом, только 6% наших рецепторов действуют как датчики цвета (9).0009 аб ).
для дальнейшего объяснения см. видео ниже, представленное Марко Оливотто (физик, работающий в области цветокоррекции изображений)
Лабораторное цветовое пространство (дальнейшее объяснение)
объяснение, я закодировал этот подход в google colaboratory, если вы не знаете, что такое google colab , Colaboratory — это бесплатная среда Jupyter Notebook , которая не требует настройки и работает полностью в облаке. С помощью Colaboratory вы можете писать и выполнять кодируйте, сохраняйте и делитесь своими анализами, а также получайте доступ к мощным вычислительным ресурсам (Tesla K-80 Nvidia GPU) — и все это бесплатно из вашего браузера. он позволяет использовать до 12 ГБ оперативной памяти.
1. выберите набор данных
выбор набора данных может показаться простым, но это не так. вы должны выбрать набор данных, который является согласованным, например, многие из наборов данных, которые я нашел, содержат много черно-белых изображений, и это может максимизировать вашу ошибку в обучающей части, потому что в этом случае вместо отображения изображения в градациях серого и его цветной версии для вашего модели, чтобы изучить отображение из оттенков серого в цветное изображение, вы показываете версию в градациях серого и изображение в градациях серого в качестве цели, в этом случае для вашей модели нет ничего полезного для изучения, поэтому вам следует удалить все изображения в градациях серого из вашего набора данных и выбрать все из них раскрасить как RGB . После фильтрации ваших данных вы готовы к части предварительной обработки.
После фильтрации ваших данных вы готовы к части предварительной обработки.
2. Предварительная обработка
Теперь у вас есть набор данных из RGB изображений. Как вы выяснили в разделе общего объяснения , выбор Lab вместо RGB является лучшим выбором, потому что вас интересует только генерация цветов, а информация о цветах встроена в ab каналов вместо RGB . при предварительной обработке вам нужно будет преобразовать весь набор данных из RGB в Lab. Еще одна вещь, которую нужно сделать перед преобразованием в Lab , — это нормализовать набор данных (разделить на максимальное значение, которое может достичь RGB пикселей), потому что диапазон RGB 2 находится между 9
для каждого цветового канала, поэтому максимальное значение RGB пиксель может достигать 255 . Эта «нормализация» позволяет нам сравнивать ошибку с нашим прогнозом и быстрее сходиться. Кроме того, все изображения должны быть одинакового размера, поэтому мы изменим их размер на « 256 x 256 »
Эта «нормализация» позволяет нам сравнивать ошибку с нашим прогнозом и быстрее сходиться. Кроме того, все изображения должны быть одинакового размера, поэтому мы изменим их размер на « 256 x 256 »
import keras
from keras.preprocessing import image
from keras.engine import Layer
из keras.layers import Conv2D, Conv3D, UpSampling2D, InputLayer, Conv2DTranspose, Input, Reshape, merge, concatenate
из keras.layers import Activation, Dense, Dropout, Flatten load_img
из skimage.color import rgb2lab, lab2rgb, rgb2gray, gray2rgb
из skimage.transform import resize
из skimage.io import imsave
from time import time
import numpy as np
import os
import random
import tensorflow as tf
from PIL import Image, ImageFile
Первое, что мы делаем, это импортируем библиотеки, которые мы будем использовать для дальнейшей работы. одна из вещей, которую google colab позволяет вам сделать, — это импортировать ваш диск Google в вашу среду, поэтому вам не нужно загружать или загружать набор данных, если они уже существуют в вашей учетной записи Google Drive.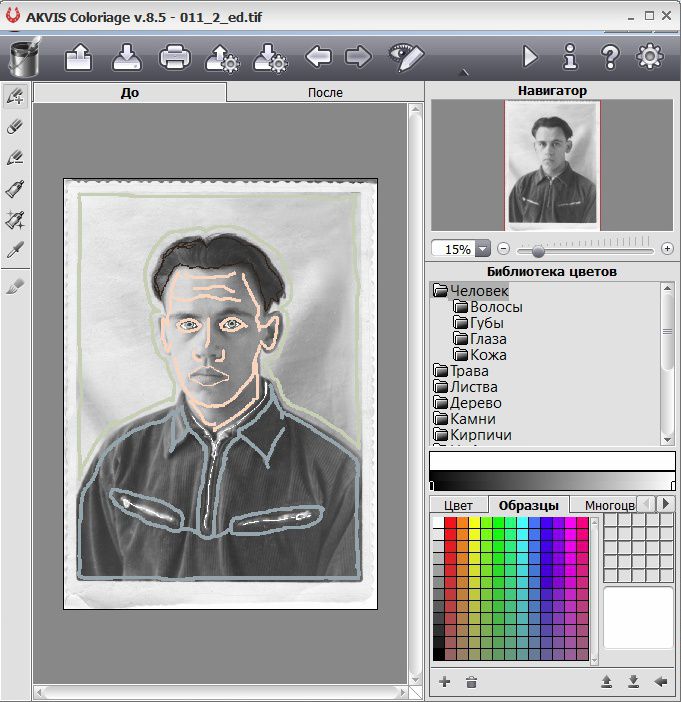 мы можем сделать это с помощью следующего кода.
мы можем сделать это с помощью следующего кода.
из google.colab импортировать диск
drive.mount('/Mahmoud')
После импорта данных пришло время нормализовать изображение (разделить их на 255). ImageDataGenerator позволяет вам делить ваши данные на лету, не потребляя при этом памяти.
path = '/Mahmoud/My Drive/dataset/'
train_datagen = ImageDataGenerator(rescale=1./255)
затем измените размер изображений на 256×256
train = train_datagen.flow_from_directory(path, target_size=(256, 256),batch_size=length,class_mode=None)
вот хитрость в использовании train_datagen.flow_from_directory: когда вы передаете путь к вашему набору данных, вы должны поместить свой набор данных в папку, а затем передать путь к этой папке. например, если ваш путь к набору данных «Мой диск/набор данных/данные», вы должны передать этот путь «Мой диск/набор данных», не передавая последнюю папку «Данные», потому что если у вас есть 3 папки, содержащие ваши данные, предполагается, что вы используете 3 класса другого набора данных, потому что мы используем только один класс, на данный момент у нас есть только одна папка, содержащая наш набор данных.
последняя часть — это преобразование из RGB в Lab .
X =[]
Y =[]
для img in train[0]:
try:
lab = rgb2lab(img)
X.append(lab[:,:,0])
Y.append(lab [:,:,1:] / 128)
кроме:
print('ошибка')
X = np.array(X)
Y = np.array(Y)X = X.reshape(X.shape+(1 ,))
print(X.shape)
print(Y.shape)
повторяя каждое изображение, мы конвертируем RGB 9от 0012 до Лаб. Поскольку нашим входом в сеть будет канал L , мы помещаем канал L каждого изображения в вектор X и ab Y 9,0010 в вектор 9,0012, который нам нужен. разделить Y на 128, потому что диапазон значений канала ab находится между (-127, 128). После нормализации значения будут между (-1, 1). мы добавляем эту строку X=X. reshape(X.shape+(1,)) потому что мы хотим, чтобы размеры X и Y были одинаковыми.
reshape(X.shape+(1,)) потому что мы хотим, чтобы размеры X и Y были одинаковыми.
1. Начало работы с созданием инфраструктуры API реального времени
2. Как я использовал машинное обучение в качестве вдохновения для физических картин
3. MS или Startup Job — какой путь выбрать, чтобы построить карьеру в области глубокого обучения?
4. ТОП-100 средних статей, связанных с искусственным интеллектом
3. Обучение сети
Теперь вы готовы построить модель.
- Часть энкодера состоит из нескольких сверточных слоев с функцией активации ReLU и , Strides=2 для уменьшения ширины и высоты вектора скрытого пространства.
- Часть декодера состоит из сверточных слоев со слоями повышающей дискретизации для восстановления размеров исходного входного изображения (256×256) и реконструкции изображения с 2 фильтрами на последнем слое, который представляет каналы ab .
 вы можете заметить здесь, что в последнем слое мы использовали функцию активации tanh вместо РеЛУ . вы должны быть в состоянии знать, почему мы сделали это, потому что мы нормализовали значения ab так, чтобы они находились между (-1,1) и tanh , используемые для раздавливания значений между (-1,1).
вы можете заметить здесь, что в последнем слое мы использовали функцию активации tanh вместо РеЛУ . вы должны быть в состоянии знать, почему мы сделали это, потому что мы нормализовали значения ab так, чтобы они находились между (-1,1) и tanh , используемые для раздавливания значений между (-1,1).
#Encoder
encoder_input = Input(shape=(256, 256, 1,))
encoder_output = Conv2D(64, (3,3), активация='relu', padding='same', strides =2)(encoder_input)
encoder_output = Conv2D(128, (3,3), активация='relu', заполнение='такое же')(encoder_output)
encoder_output = Conv2D(128, (3,3), активация='relu', padding='same', strides=2)(encoder_output)
encoder_output = Conv2D(256, (3,3), активация='relu' , padding='same')(encoder_output)
encoder_output = Conv2D(256, (3,3), активация='relu', padding='same', strides=2)(encoder_output)
encoder_output = Conv2D(512, ( 3,3), активация='relu', заполнение='то же самое')(encoder_output)
encoder_output = Conv2D(512, (3,3), активация='relu', заполнение='то же самое')(encoder_output)
encoder_output = Conv2D(256, (3,3), активация='relu', заполнение='такое же')(encoder_output)#Декодер
decoder_output = Conv2D(128, (3,3), активация='relu', padding='same')(encoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(64, ( 3,3), активация = 'relu', заполнение = 'то же') (decoder_output)
decoder_output = UpSampling2D ((2, 2)) (decoder_output)
decoder_output = Conv2D (32, (3,3), активация =' relu', padding='same')(decoder_output)
decoder_output = Conv2D(16, (3,3), активация='relu', padding='same')(decoder_output)
decoder_output = Conv2D(2, (3, 3), активация = 'tanh', заполнение = 'то же самое') (decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
model = Model(inputs=encoder_input, outputs=decoder_output)
После построения модели обучите ее, используя среднеквадратичную ошибку в качестве функции потерь и Adam как оптимизатор. количество эпох — это выбор методом проб и ошибок. это также зависит от типа набора данных, например, набор данных о цветах может сильно отличаться от набора данных о животных.
количество эпох — это выбор методом проб и ошибок. это также зависит от типа набора данных, например, набор данных о цветах может сильно отличаться от набора данных о животных.
model.compile(optimizer='adam', loss='mse' , metrics=['accuracy'])
model.fit(X,Y,validation_split=0.2, epochs=1000 )
4. Постобработка
как мы делаем в препроцессинге для обучения, так же делаем перед тестированием. не имеет значения, находится ли тестовое изображение в градациях серого или в цвете, потому что в обоих случаях мы извлекаем канал L и делаем прогноз с изображением в градациях серого.
test_path = 'MyDrive/Test/'
test = os.listdir(test_path)
для imgName в тесте:
color_me = []
img = img_to_array(load_img(test_path + imgName))
img = resize(img ,(256,256))
color_me.append(img)
color_me = np.array(color_me, dtype=float)
color_me = rgb2lab(1.0/255*color_me)[:,:,:,0 ]
color_me = color_me.reshape(color_me.shape+(1,))
print(color_me.shape)
После прогнозирования мы ожидаем, что значения будут в диапазоне (-1,1). это потому, что мы использовали функцию tanh на последнем слое, поэтому нам нужно умножить значения на 128, чтобы восстановить значения каналов ab .
output = model.predict(color_me)
output = output * 128
Последнее, что нужно сделать, это объединить каналы L , которые вы использовали для тестирования, с вашими выходными каналами ab для восстановления Lab сохраните изображение, которое вы только что создали, после преобразования его в RGB .
# Раскрашивание вывода
для i in range(len(output)):
result = np.zeros((256, 256, 3))
результат[:,:,0] = color_me[i][:,:,0]
результат[:,:,1:] = вывод[i]
imsave("результат"+i+".png", lab2rgb (результат))
теперь вы знаете основную идею выполнения этой задачи с основными шагами, есть другой подход, который похож на то, что мы сделали, но он более эффективен и генерирует гораздо быстрее. он использует технику трансферного обучения.
он использует технику трансферного обучения.
Как сказал Джейсон Браунли в своей статье «Нежное введение в трансферное обучение для глубокого обучения»
Изображение индуктивного переносаТрансферное обучение — это метод машинного обучения, при котором модель, разработанная для одной задачи, повторно используется в качестве отправной точки для модели второй задачи.
Это популярный подход в глубоком обучении, при котором предварительно обученные модели используются в качестве отправной точки для задач компьютерного зрения и обработки естественного языка, учитывая огромные вычислительные и временные ресурсы, необходимые для разработки моделей нейронных сетей для этих задач и из-за огромных прыжков. в навыках, которые они предоставляют по связанным проблемам.
вы можете использовать трансферное обучение, чтобы ускорить обучение и повысить производительность вашей модели глубокого обучения.
Трансферное обучение — это метод машинного обучения, при котором модель, обученная одной задаче, переназначается для второй связанной задачи.

Трансферное обучение и адаптация предметной области относятся к ситуации, когда то, что было изучено в одной обстановке… используется для улучшения обобщения в другой обстановке
— Страница 526, Глубокое обучение, 2016.0002 Трансферное обучение — это оптимизация, позволяющая ускорить прогресс или повысить производительность при моделировании второй задачи.
Трансферное обучение — это улучшение обучения новой задаче путем переноса знаний из связанной задачи, которая уже была изучена.
— Глава 11: Трансферное обучение, Справочник по исследованиям приложений машинного обучения, 2009 г.
Трансферное обучение связано с такими проблемами, как многозадачное обучение и дрейф концепций, и не является исключительно областью изучения глубокого обучения.
Тем не менее, трансферное обучение популярно в глубоком обучении, учитывая огромные ресурсы, необходимые для обучения моделей глубокого обучения, или большие и сложные наборы данных, на которых обучаются модели глубокого обучения.
Перенос обучения работает только в глубоком обучении, если функции модели, изученные в первой задаче, являются общими.
При обучении с передачей мы сначала обучаем базовую сеть базовому набору данных и задаче, а затем переназначаем изученные функции или переносим их во вторую целевую сеть для обучения на целевом наборе данных и задаче. Этот процесс будет иметь тенденцию работать, если функции являются общими, то есть подходящими как для базовых, так и для целевых задач, а не специфичными для базовой задачи.
— Насколько можно передавать функции в глубоких нейронных сетях?
Эта форма трансферного обучения, используемая в глубоком обучении, называется индуктивным переносом. Именно здесь область возможных моделей (предвзятость модели) сужается выгодным образом за счет использования модели, подходящей для другой, но связанной задачи.
Взято из «Переносного обучения»
Эндрю Нг, соучредитель Coursera и адъюнкт-профессор компьютерных наук в Стэнфордском университете, сказал в своем широко популярном учебном пособии NIPS 2016, что трансферное обучение будет — после контролируемого обучения — следующий фактор коммерческого успеха ML.
В частности, он нарисовал на доске диаграмму, показанную на рисунке ниже. По словам Эндрю Нг, трансферное обучение станет ключевым фактором успеха машинного обучения в отрасли.
В этом разделе работа выполняется в виртуальной машине Microsoft Azure вместо google colab, потому что я хотел увеличить свой набор данных, а google colab завершает сеанс после использования 12 ГБ ОЗУ. Microsoft Azure предоставляет 56 ГБ оперативной памяти. если вы студент, вы можете использовать свою почту колледжа по обмену, чтобы получить 100 долларов США за использование виртуальной машины Microsoft Azure, а за 100 долларов вы можете получить до 160 часов использования вашей виртуальной машины. обязательно выберите виртуальные машины для обработки данных, поскольку они имеют предварительно настроенные среды в облаке для обработки данных и разработки искусственного интеллекта. Для обучения используется графический процессор Tesla K-80 Nvidia.
Продолжая предыдущий раздел, мы собираемся изменить архитектуру модели и использовать трансферное обучение вместо обучения сети с нуля, мы собираемся использовать предварительно обученную модель VGG16 в качестве кодировщика, VGG16 (также называемую OxfordNet) — сверточный архитектура нейронной сети, названная в честь группы визуальной геометрии из Оксфорда, которая ее разработала. Он был использован для победы в конкурсе ILSVR (ImageNet) в 2014 году. По сей день он по-прежнему считается отличной моделью зрения. научились классифицировать между 1000 классами набора данных ImageNet
Он был использован для победы в конкурсе ILSVR (ImageNet) в 2014 году. По сей день он по-прежнему считается отличной моделью зрения. научились классифицировать между 1000 классами набора данных ImageNet
На рисунке ниже показана архитектура VGG16 : входной слой берет изображение размером (224 x 224 x 3), а выходной слой представляет собой предсказание softmax на 1000 классов. От входного слоя до последнего слоя максимального объединения (обозначенного 7 x 7 x 512) рассматривается как часть извлечения признаков модели, в то время как остальная часть сети рассматривается как классификационная часть модели. .
Архитектура модели VGG16Поскольку мы собираемся заменить часть кодировщика на VGG16, он нам не нужен как классификатор, он нужен нам как экстрактор признаков, поэтому последние плотные слои не нужны, мы должны их всплывать. .
vggmodel = keras.applications.vgg16.VGG16()
newmodel = Sequential()
num = 0
для i, слой в enumerate(vggmodel.layers):
, если i<19:
newmodel.add(layer)
newmodel.summary()
для слоя в newmodel.layers:
layer.trainable=False
здесь мы повторяем каждый слой, кроме последних плотных слоев, поэтому мы добавляем 19 слоев в нашу модель. размер тома последнего слоя «7x7x512». мы будем использовать этот объем скрытого пространства в качестве вектора признаков для ввода в декодер. и декодер собирается изучить отображение из скрытого пространственного вектора в аб каналов. нам нужны слои VGG16 с их первоначальными весами без их изменения, чтобы мы установили для обучаемого параметра в каждом слое значение false, потому что мы не хотим обучать их снова. окончательная архитектура показана на рисунке ниже.
архитектура моделиVGG16 ожидает на входе трехмерное изображение размером 224×224, при предварительной обработке мы должны масштабировать все изображения до 224 вместо 256
224, 224),размер_пакета=длина,режим_класса=нет)
теперь у нас есть один канал L в каждом слое, но VGG16 ожидает 3 измерения, поэтому мы повторили канал L два раза, чтобы получить 3 измерения одного и того же канала L
vggfeatures = []
для i, образец в enumerate(X):
образец = gray2rgb(sample)
образец = sample.reshape((1,224,224,3))
предсказание = newmodel.predict(sample)
предсказание = предсказание.изменить( (7,7,512))
vggfeatures.append(прогноз)
vggfeatures = np.array(vggfeatures)
print(vggfeatures.shape)
строка gray2rgb повторяет канал L , чтобы иметь 3 измерения по глубине. после прогнозирования добавьте прогноз в список vggfeatures для последующего использования в архитектуре. форма этого списка (количество изображений, 7, 7, 512). каждое изображение имеет размеры вектора скрытого пространства модели экстрактора признаков VGG16. последний шаг — построить новую архитектуру.
2. Обучите свою сеть
#Encoder
encoder_input = Input(shape=(7, 7, 512,))
#Decoder
decoder_output = Conv2D(256, (3,3), активация='relu', padding= 'такой же')(вход_кодера)выход_декодера = Conv2D(128, (3,3), активация='relu', заполнение='то же самое')(выход_декодера)
вывод_декодера = UpSampling2D((2, 2))(выход_декодера)
вывод_декодера = Conv2D(64, (3,3), активация='relu', заполнение='такое же')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(32, (3,3), активация='relu', padding='same')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(16, ( 3,3), активация = 'relu', заполнение = 'то же самое') (decoder_output)
decoder_output = UpSampling2D ((2, 2)) (decoder_output)
decoder_output = Conv2D (2, (3, 3), активация =' tanh', padding='same')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
model = Model(inputs=encoder_input, outputs=decoder_output)
После создания модели вы готовы к ее обучению. количество эпох и размер партии могут различаться в зависимости от типа или классов набора данных.
количество эпох и размер партии могут различаться в зависимости от типа или классов набора данных.
из keras.callbacks import TensorBoard
tensorboard = TensorBoard(log_dir='C:\\Users\\mahmoudkhedr\\Desktop\\logs\\')
model.compile(optimizer='Adam', loss='mse' , metrics=['accuracy'])
model.fit(vggfeatures, Y, verbose=1, epochs=100, batch_size=128)
3. Постобработка
изменение в разделе Постобработка заключается в том, что вы собираетесь использовать два модели вместо одной, первая модель — это предварительно обученная модель VGG16 для извлечения функций и использования этих функций для прогнозирования с помощью второй модели «декодера», который вы использовали для обучения ваших данных
testpath = 'C:\\Users\\mahmoudkhedr\\Desktop\\test\\'
files = os.listdir(testpath)
для idx, файл в перечислении(файлы):
test = img_to_array(load_img(testpath +file))
test = resize(test, (224,224), anti_aliasing=True)
test*= 1.0/255
lab = rgb2lab(test)
l = lab[:,:,0]
L = gray2rgb(l )
L = L.reshape((1,224,224,3))
#print(L.shape)
vggpred = newmodel.predict(L)
ab = model.predict(vggpred)
#print(ab.shape)
ab = аб*128
cur = np.zeros((224, 224, 3))
cur[:,:,0] = l
cur[:,:,1:] = ab
imsave('C:\\Users\\download \\result'+str(idx)+".jpg", lab2rgb(cur))
, наконец, сохраните результат. в следующем разделе показаны некоторые результаты, которые я получил на тестовых данных.
Есть еще одна дополнительная работа, связанная с размером изображения на этапе тестирования, но она не упоминается здесь, потому что я был озабочен упоминанием основной проблемы и ее решения.
В заключение, раскрашивание изображения не является простым или тривиальным, если сравнивать его с проблемами классификации, потому что здесь мы имеем дело с созданием изображения вместо меток. в этой статье я попытался показать свою работу по решению этой проблемы и решение для создания цветных изображений.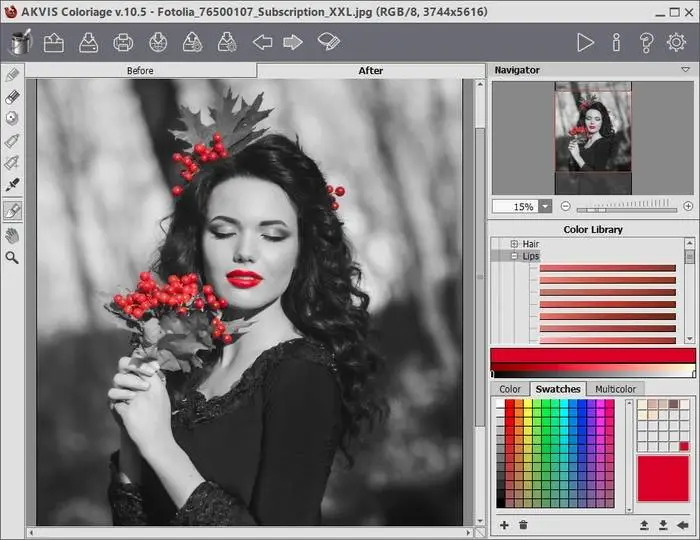 Пробовал разные наборы данных. Я обнаружил, что набор данных имеет решающее значение и может изменить ваши результаты, например, если вы хотите, чтобы ваша модель была конкретной и раскрашивала изображения цветов, вам нужно выбрать набор данных цветов, чем больше данных вы предоставите, тем лучше результат.
Пробовал разные наборы данных. Я обнаружил, что набор данных имеет решающее значение и может изменить ваши результаты, например, если вы хотите, чтобы ваша модель была конкретной и раскрашивала изображения цветов, вам нужно выбрать набор данных цветов, чем больше данных вы предоставите, тем лучше результат.
Спасибо Эмилю Валльнеру , который помогал и поддерживал меня в этом проекте. Я многому научился из его предыдущей работы по раскрашиванию.
Спасибо моей команде (Омар Абдель-Разик, Омар Халед, Махмуд Али, Амр Мухаммед), которые работали со мной и помогли запустить этот проект.
Если у вас есть какие-либо вопросы, не стесняйтесь спрашивать меня.
Электронная почта: [email protected]
Раскрашивание черно-белых изображений с помощью глубокого обучения | Автор Шреяс Трипати
Hola Amigos,
Несколько дней назад, во время зимних каникул, я был в гостях у бабушки и дедушки, и там я наткнулся на черно-белые фотографии моей матери в ее детстве, и мне вдруг пришла в голову идея, а как насчет того, чтобы попробовать раскрасить это изображение. Итак, я начал искать эту тему и связанные с ней работы, сделанные в научных статьях.
Итак, я начал искать эту тему и связанные с ней работы, сделанные в научных статьях.
Том Зимберофф изучал музыку в Университете Южной Калифорнии, прежде чем заняться фотографией. В качестве…
www.datadriveninvestor.com
После нескольких часов поиска я наконец нашел способ раскрасить эти изображения, и сразу же приступил к работе над этим проектом, и после изнурительных 6 часов я, наконец, получил работающую модель, хотя результаты не такие идеальные, как у меня были воображаемый. Но, тем не менее, я подумал написать этот блог о своем проекте. Итак, давайте посмотрим, как раскрашивать черно-белые изображения.0009 выводит раскрашенное изображение , которое представляет семантические цвета и тона входных данных (например, океан в ясный солнечный день должен быть правдоподобно «синим» — модель не может окрасить его в «ярко-розовый»).
Предыдущие методы раскрашивания изображения:
- Основаны на значительном человеческом взаимодействии и аннотациях
- Произведенная ненасыщенная раскраска
Новый подход, который мы собираемся использовать сегодня, вместо этого основан на глубоком обучении. Мы будем использовать сверточную нейронную сеть, способную раскрашивать черно-белые изображения с результатами, которые могут даже «обмануть» людей! 9Модель 0003, предложенная Zhang et al.
Мы будем использовать сверточную нейронную сеть, способную раскрашивать черно-белые изображения с результатами, которые могут даже «обмануть» людей! 9Модель 0003, предложенная Zhang et al.
Техника, которую мы рассмотрим сегодня, взята из статьи ECCV 2016 года Zhang et al. Colorization Colorization .
Предыдущие подходы к раскрашиванию черно-белых изображений основывались на ручной аннотации человека и часто давали ненасыщенные результаты, которые не были «правдоподобными» как истинные раскраски.
Чжан и др. решил решить проблему раскрашивания изображения, используя сверточные нейронные сети, чтобы «галлюцинировать», как будет выглядеть исходное изображение в градациях серого при раскрашивании.
Теперь, когда мы получаем интенсивность в качестве входных данных и должны угадывать цвета, мы не можем использовать цветовое пространство RGB, поскольку оно не содержит информации об освещении. Следовательно, у нас есть два варианта: либо использовать цветовое пространство YCbCr, либо цветовое пространство LAB, поскольку оба канала Y и L кодируют информацию об освещении.
В этом уроке мы будем использовать цветовое пространство LAB, но вы также можете попробовать использовать пространство YCbCr.
Подобно цветовому пространству RGB, цветовое пространство Lab имеет три канала . Но , в отличие от цветового пространства RGB, Lab кодирует информацию о цвете по-другому:
- Канал L кодирует только яркость яркости
- Канал и кодирует зелено-красный.
- А канал b кодирует сине-желтый
Для получения дополнительной информации вы можете обратиться к этой статье в Википедии.
Поскольку канал L кодирует только интенсивность, мы можем использовать канал L в качестве нашего входа в оттенки серого для сети.
Отсюда сеть должна научиться предсказывать каналы a и b . Имея входных данных L канала и предсказанных ab каналов , мы можем затем сформировать наше окончательное выходное изображение .
Весь (упрощенный) процесс можно резюмировать следующим образом:
- Преобразование всех обучающих изображений из цветового пространства RGB в цветовое пространство Lab.
- Используйте канал L в качестве входных данных для сети и обучите сеть прогнозировать каналы ab .
- Объедините вход L канала с предсказанными ab каналами.
- Преобразование лабораторного изображения обратно в RGB.
Для получения более подробной информации см. оригинальную статью Zhang et al.
Наш скрипт раскраски требует только три импорта: NumPy, OpenCV и argparse.
Давайте продолжим и используем argparse для разбора аргументов командной строки. Этот сценарий требует, чтобы эти четыре аргумента были переданы сценарию непосредственно из терминала:
- — изображение: путь к нашему входному черно-белому изображению.

- — prototxt: наш путь к файлу prototxt Caffe.
- — модель . Наш путь к предварительно обученной модели Caffe.
- — points : путь к файлу центральных точек кластера NumPy.
С указанными выше четырьмя флагами и соответствующими аргументами сценарий сможет работать с различными входными данными без изменения кода.
# импортировать необходимые пакетыимпортировать numpy as np
import argparse
import cv2# построить анализатор аргументов и разобрать аргументыap = argparse.ArgumentParser()
ap.add_argument("-i", "— image", type=str, required=True,
help="путь к входному черно-белому изображению")
ap.add_argument("-p", " — prototxt", type=str, required=True,
help="путь к файлу prototxt Caffe" )
ap.add_argument("-m", "-model", type=str, required=True,
help="путь к предварительно обученной модели Caffe")
ap.add_argument("-c", "— points", type=str, required=True,
help="путь к центральным точкам кластера")
args = vars(ap.
Идём дальше и загрузим нашу модель и центры кластера в память:
Теперь мы загружаем нашу модель Caffe непосредственно из значений аргументов командной строки. OpenCV может читать модели Caffe с помощью функции cv2.dnn.readNetFromCaffe. После этого загрузите центральные точки кластера непосредственно из пути аргумента командной строки в файл точек.
Несколько средних строк:
- Центры нагрузки для ab канал квантование, используемое для перебалансировки.
- Считайте каждую из точек 1×1 сверток и добавьте их в модель.
# загрузить нашу сериализованную черно-белую модель колоризатора и кластер
# центральные точки с диска
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args[ «модель»])
pts = np.load(args[«points»])# добавить центры кластеров в виде сверток 1x1 в модель
class8 = net.getLayerId("class8_ab")
conv8 = net.
pts = pts.transpose().reshape(2, 313, 1, 1)
net.getLayer(class8).blobs = [pts.astype("float32")]
net.getLayer(conv8).blobs = [np.full([1, 313], 2.606,dtype="float32")]# загрузить входное изображение с диска, масштабировать интенсивность пикселей в диапазоне
# [0, 1], а затем преобразовать изображение из BGR в Lab color
# space
image = cv2.imread(args["image"])
scaled = image.astype(" поплавок32") / 255,0
lab = cv2.cvtColor(scaled, cv2.COLOR_BGR2LAB
Теперь мы можем передать вход L канал через сеть, чтобы предсказать ab каналов:
A через прямой проход канала L сеть занимает строк 48 и 49 (вот освежение информации о OpenCV blobFromImage , если вам это нужно). Здесь все выглядит просто, но если вам нужны подробности, обратитесь к документации и демонстрации Чжана и др. на GitHub.0003
Постобработка включает:
- Захват L канала из исходного входного изображения ( Line 58 ) и объединение исходного L канала и спрогнозировано каналы ab вместе образуют раскрашенные
- Преобразование раскрашенного изображения из цветового пространства Lab в RGB
- Обрезка любых интенсивностей пикселей, выходящих за пределы диапазона [0, 1]
- Возвращение интенсивности пикселей в диапазон [0, 255] На этапах предварительной обработки мы делили на 255, а теперь умножаем на 255. Я также обнаружил, что это масштабирование и преобразование «uint8» не являются обязательными, но помогают коду работать между версиями OpenCV 3.4.x и 4.x .
Наконец, на экране отображается как исходное изображение, так и раскрашенные изображения!
# изменить размер изображения лаборатории до 224x224 (размеры раскраски
# сеть принимает), разделите каналы, извлеките канал 'L', а затем
# выполните центрирование по среднему значению
resized = cv2.resize(lab, (224, 224))
L = cv2.split(resized)[0]
L -= 50# передать канал L через сеть, которая будет *предсказывать* значения каналов 'a'
# и 'b'
'print("[INFO] раскрашивание изображения…")'
net.setInput(cv2 .dnn.blobFromImage(L))
ab = net.forward()[0, :, :, :].transpose((1, 2, 0))# изменить размер прогнозируемого объема 'ab' до тех же размеров, что и наш
# входное изображение
ab = cv2.resize(ab, (image.shape[1], image.
# взять канал 'L' из *исходного* входного изображения (не
# измененный размер one) и соедините исходный канал «L» с
# предсказанными каналами «ab»
L = cv2.split(lab)[0]
colorized = np.concatenate((L[:, :, np.newaxis], ab), axis=2)# преобразовать выходное изображение из цветового пространства Lab в RGB, затем# обрезать любые значения, выходящие за пределы диапазона [0, 1]
colorized = cv2.cvtColor(colorized, cv2.COLOR_LAB2BGR)
colorized = np.clip(colorized, 0, 1)# текущее раскрашенное изображение представлено в виде числа с плавающей точкой
# тип данных в диапазоне [0, 1] — преобразуем в беззнаковое
# 8-битное целое представление в диапазон [0, 255]
раскрашенный = (255 * раскрашенный).astype("uint8")# показать исходное и выходное раскрашенные изображения раскрашено)
cv2.waitKey(0)
Не пугайтесь. Это ожидаемый результат, но результаты, которые я получил, немного далеки от такого совершенства.
Это изображение Марка Твена, американского писателя, юмориста, предпринимателя, издателя и лектора. Его превозносили как «величайшего юмориста, когда-либо родившегося в этой стране», а Уильям Фолкнер называл его «отцом американской литературы».
Здесь мы видим, что трава и листва окрашены в правильный оттенок зеленого, хотя вы можете видеть, как эти оттенки зеленого смешиваются с обувью и руками Твен.
На слева вы можете увидеть оригинальное входное изображение Робина Уильямса, известного актера и комика, который скончался примерно 5 лет назад.
На справа вы можете увидеть результат черно-белой модели раскрашивания.
В сегодняшнем уроке вы узнали, как раскрашивать черно-белые изображения с помощью OpenCV и Deep Learning.
Модель раскрашивания изображения, которую мы использовали здесь сегодня, была впервые представлена Zhang et al. в своей публикации 2016 года « Цветная раскраска изображения ».
Используя эту модель, мы смогли раскрасить черно-белые изображения.
Наши результаты, хотя и не идеальные, продемонстрировали правдоподобность автоматического раскрашивания черно-белых изображений и видео.