Сравнение 24-битного и 16-битного звука: результаты аудиотеста / Хабр
Блогер Archimago немало сил потратил, чтобы ответить на вопрос: какое качество звука человек способен определять на слух? В рамках одного из его последних аудиотестов респондентов просят вслепую различить звуки с динамическим диапазоном 24 бит и 16 бит. Каждый из них скачивал несколько пар 24-битных файлов, один из которых претерпел конверсию 24-16-24 бита, то есть на практике был 16-битным файлом. Их просили определить разницу.В тесте приняли участие 140 добровольцев (138 мужчин и 2 женщины: честная демографическая картина для аудиофилов). Средний возраст респондентов: 44 года.
Согласно анкетам, более 20% респондентов назвались музыкантами и звукоинженерами, поэтому можно сравнить результаты среди «профессионалов» и любителей, с учётом статистической погрешности.
Стоимость аудиоаппаратуры у участников опроса чаще всего лежит в диапазоне от $1000 до $3000.
Результаты опроса по трём парам файлов довольно любопытны.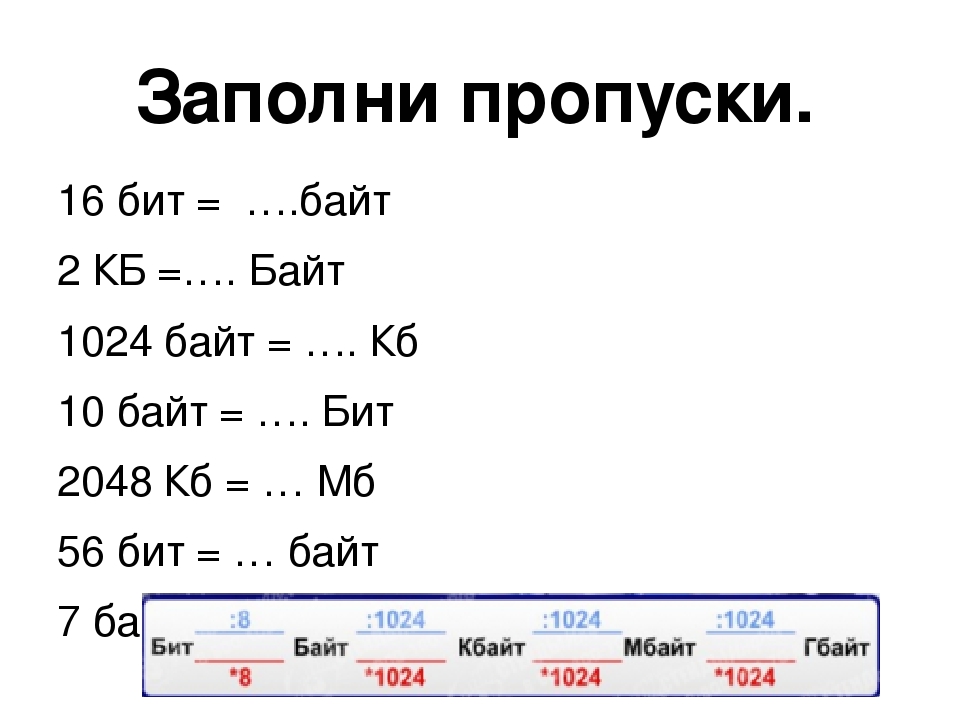
А в композиции Bozza 52,85% пользователей ошиблись, приняв 16-битный файл за 24-битный.
20 респондентов правильно ответили на все вопросы, а 21 человек ошибся во всех вариантах, что тоже вписывается в рамки статистического распределения.
Ещё более удивительно, что музыканты показали результат хуже среднего, даже с учётом статистической погрешности! Особенно сильно напутали в композиции Вивальди.
А вот результат среди пользователей, у которых стоимость звукового оборудования превышает $6000.
Наушники тоже вовсе не помогают отличить 16-битную музыку от 24-битной.
Подводя итог. Конечно, есть приложения, в которых нужно работать именно с 24-битным звуком (тот же мастеринг). Но факт в том, что на слух 16- и 24-битный звук совершенно не различимы друг от друга. Если кто-то заявляет, что способен услышать разницу, то этот человек наверняка заблуждается.
Сколько битов необходимо для обращения к этому объему памяти?
Я прохожу курс основ программирования и в настоящее время нахожусь на главе, где говорится о компьютерной организации и операциях с битами — как работает CPU (ALU, CU, регистры и т. д.).
Я довольно хорошо разбираюсь в двоичном языке. Я понимаю знак / величину format/ дополнения 1, дополнения 2 и т. д.
В книге я узнал, что кусочек = 4 бита, 8 бит = 1 байт — это слово, которое обычно находится в группах: 8 бит, 16 бит, 32 бита или 64 бита (так далее), и все это имеет для меня идеальный смысл. Вот мой вопрос о домашнем задании, который меня немного смущает:
«Компьютер имеет 64 MB памяти, каждое слово — 4 байта. Сколько битов необходимо для обращения к каждому отдельному слову в памяти?»
Ну, теперь я в замешательстве. В книге только что говорилось, что слово обычно кратно 8. Однако я знаю, что 1 байт = 8 бит, поэтому, поскольку есть 4 байта и 1 байт = 8 байт, было бы правильно думать, что 4 байта х 8 бит = 32 бита? Это и есть ответ?
Поделиться Источник Daniel 25 сентября 2011 в 05:06
4 ответа
-
x86-количество регистров против количества зарезервированных битов
Я новичок в assembly, и мой вопрос таков:: Если машина имеет, например, n регистров.
 Сколько битов необходимо зарезервировать в инструкции assembly для обращения к каждому из n регистров? И на сколько функциональное разделение может уменьшить необходимые биты?
Сколько битов необходимо зарезервировать в инструкции assembly для обращения к каждому из n регистров? И на сколько функциональное разделение может уменьшить необходимые биты?
-
В CUDA, не коалесцированные обращения к памяти вызывают расхождение ветвей?
Я всегда думал, что расхождение ветвей вызвано только кодом ветвления, таким как if, else, for, switch и т. д. Однако недавно я прочитал статью, в которой говорится:: Можно ясно заметить, что количество расходящихся ветвей, взятых потоками в каждом первом алгоритме, основанном на разведке, по…
5
1-битный адрес может адресовать два слова (0, 1).
2-битный адрес может адресовать четыре слова (00, 01, 10, 11).
3-битный адрес может адресовать восемь слов (000, 001, 010, 011, 100, 101, 110, 111).
Итак, первый ответ: сколько у вас слов? Затем ответьте: сколько битов нужно вашему адресу, чтобы обратиться к ним?
Поделиться Nemo 25 сентября 2011 в 05:19
3
64 МБ = 67108864 байт/4 байта = 16777216 слово в памяти, и каждое отдельное слово, таким образом, может быть адресовано в 24 битах (первое слово имеет адрес 000000000000000000000000, а последнее-адрес 111111111111111111111111).
Требование состоит в том, чтобы представить каждое слово памяти с адресом, который находится в битах, таким образом, чтобы каждое слово могло быть представлено.
Например, чтобы представить 4 слова, вам нужно 4 адреса, 2, возведенное в 2, равно 4, поэтому вам нужно два бита. 00-это адрес первого слова, 01-адрес второго слова, 10-адрес третьего слова и 11-адрес 4-го слова.
Для 8 слов вам нужно 8 адресов, а 2, возведенное в 3, равно 8, поэтому требуется 3 бита. 000, 001, 010, 011, 100, 101, 110, 111 это 8 адресов.
Поделиться SpeedBirdNine 25 сентября 2011 в 05:19
2
1 байт = 8 бит, так что, поскольку есть 4 байта и 1 байт = 8 бит, было бы правильно думать, что 4 байта х 8 бит = 32 бита?? быть ответом???
Нет, это не ответ. Если ваш компьютер имеет 64 MB памяти и каждое слово составляет 4 байта, сколько слов есть в вашей памяти? Сколько битов вам нужно для обращения к каждому слову (биты необходимы для представления числа от 0 до числа слов — 1).
Если ваш компьютер имеет 64 MB памяти и каждое слово составляет 4 байта, сколько слов есть в вашей памяти? Сколько битов вам нужно для обращения к каждому слову (биты необходимы для представления числа от 0 до числа слов — 1).
Поделиться K-ballo 25 сентября 2011 в 05:10
-
Сколько битов мантиссы точно представляют собой фракитон
Это часть обзора для будущего экзамена, и я застрял на этой проблеме. Любая помощь будет очень признательна. Я действительно не знаю, как подойти к этой проблеме. Спасибо. Луна удаляется от Земли примерно на 4 /1024 км в год. Сколько битов мантиссы потребуется, чтобы сложить орбитальное расстояние…
-
Сколько битов необходимо для 2-сторонней ассоциативной адресации кэша?
Приведенный ниже Вопрос сбивает меня с толку, так как он не похож на другие примеры, которые я видел. Для 128-байтовой памяти и 32-байтового 2-полосного набора ассоциированной обратной записи, кэширования данных с выделением записи с 4-байтовыми блоками и политикой замены LRU (наименее недавно.
 ..
..
1
Формула бытия:
log (размер памяти/адресуемый размер блока) / log 2
Пример1: Сколько адресных битов требуется для адресации 16 Гбайт памяти, где каждая адресуемая единица имеет ширину 1 байт? Ans: log(16*1024*1024*1024/1)/log2 = 34 бита
Пример 2: Сколько адресных битов требуется для адресации 16 Гбайт памяти, где каждая адресуемая единица имеет ширину 2 байта? Ans: log(16*1024*1024*1024/2)/log2 = 33 бита
Пример3: Сколько адресных битов требуется для адресации 64 Мбайт памяти, где каждая адресуемая единица имеет ширину 4 байта? Ans: log(64*1024*1024/4)/log2 = 24 бита
Пример3: Сколько адресных битов требуется для адресации 16 Мбайт памяти, где каждая адресуемая единица имеет ширину 1 байт? Ans: log(16*1024*1024/1)/log2 = 24 бита
Поделиться Raj Kapoor 29 октября 2019 в 04:41
Похожие вопросы:
Redis: отношение размера базы данных к объему памяти?
Каково отношение размера базы данных Redis к объему памяти? Например, если у меня есть база данных 80 МБ, сколько RAM будет использовать Redis (при использовании с обычным веб-приложением)?
не выровненные обращения к памяти
Я работаю над встроенным устройством, которое не поддерживает невыровненный доступ к памяти.
алгоритм LRU, сколько битов необходимо для реализации этого алгоритма?
У меня есть небольшой вопрос об алгоритме LRU. Если у вас есть кэш с четырьмя блоками, сколько битов вам нужно для реализации этого алгоритма ?
x86-количество регистров против количества зарезервированных битов
Я новичок в assembly, и мой вопрос таков:: Если машина имеет, например, n регистров. Сколько битов необходимо зарезервировать в инструкции assembly для обращения к каждому из n регистров? И на…
В CUDA, не коалесцированные обращения к памяти вызывают расхождение ветвей?
Я всегда думал, что расхождение ветвей вызвано только кодом ветвления, таким как if, else, for, switch и т. д. Однако недавно я прочитал статью, в которой говорится:: Можно ясно заметить, что…
Сколько битов мантиссы точно представляют собой фракитон
Это часть обзора для будущего экзамена, и я застрял на этой проблеме. Любая помощь будет очень признательна. Я действительно не знаю, как подойти к этой проблеме. Спасибо. Луна удаляется от Земли…
Любая помощь будет очень признательна. Я действительно не знаю, как подойти к этой проблеме. Спасибо. Луна удаляется от Земли…
Сколько битов необходимо для 2-сторонней ассоциативной адресации кэша?
Приведенный ниже Вопрос сбивает меня с толку, так как он не похож на другие примеры, которые я видел. Для 128-байтовой памяти и 32-байтового 2-полосного набора ассоциированной обратной записи,…
Как определить количество битов, байтов и ячеек памяти?
1) сколько ячеек памяти имеется в 4K x 8 памяти? 2) Сколько слов можно в нем хранить? 3) Сколько битов в каждом слове?
Почему запись в многоуровневой таблице страниц содержит меньше битов, чем требуется для обращения к основной памяти?
Сколько битов требуется для хранения значения указателя?
Насколько мне известно, размер указателя в 32-битных системах обычно составляет 4 байта, а в системах 64-bit-8 байт. Но, насколько я знаю, не все биты используются для хранения адреса. Если да, то…
Но, насколько я знаю, не все биты используются для хранения адреса. Если да, то…
Что это такое 16 бит. Энциклопедия
Пользователи также искали:
16 бит это,
16 бит музыка,
16 бит тому назад 3 сезон,
16 бит тому назад лурк,
16 бит тому назад,
16 бит цвет,
16 бит в байт,
8 или 16 бит для печати,
бит,
бит тому назад,
назад,
тому,
бит в байт,
бит тому назад лурк,
бит тому назад сезон,
или бит для печати,
бит цвет,
цвет,
музыка,
байт,
лурк,
сезон,
печати,
бит музыка,
бит это,
16 бит,
16 бит тому назад,
16 бит в байт,
16 бит тому назад лурк,
16 бит тому назад 3 сезон,
8 или 16 бит для печати,
16 бит цвет,
16 бит музыка,
16 бит это,
история компьютерной техники. 16 бит,
16 бит,
А8 — ЕГЭ по информатике
Тема: Кодирование звука.
Что нужно знать:
· при оцифровке звука в памяти запоминаются только отдельные значения сигнала, который нужно выдать на динамик или наушники
· частота дискретизации определяет количество отсчетов, запоминаемых за 1 секунду; 1 Гц (один герц) – это один отсчет в секунду, а 8 кГц – это 8000 отсчетов в секунду
· глубина кодирования – это количество бит, которые выделяются на один отсчет
· для хранения информации о звуке длительностью t секунд, закодированном с частотой дискретизации f Гц и глубиной кодирования B бит требуется B*f*t бит памяти; например, при f = 8кГц, глубине кодирования 16 бит на отсчёт и длительности звука 128 секунд требуется
I=8000*16*128=16384000 бит
I=8000*16*128/8=2048000 байт
I=8000*16*128/8/1024=2000 Кбайт
I=8000*16*128/8/1024/1024=1,95 Мбайт
· при двухканальной записи (стерео) объем памяти, необходимый для хранения данных одного канала, умножается на 2
Пример задания:
Производится
одноканальная (моно) звукозапись с частотой дискретизации 16 кГц и глубиной
кодирования 24 бита. Запись длится 1 минуту, ее результаты записываются в файл,
сжатие данных не производится. Какое из приведенных ниже чисел наиболее близко
к размеру полученного файла, выраженному в мегабайтах?
Запись длится 1 минуту, ее результаты записываются в файл,
сжатие данных не производится. Какое из приведенных ниже чисел наиболее близко
к размеру полученного файла, выраженному в мегабайтах?
1) 0,2 2) 2 3) 3 4) 4
Решение:
1) так как частота дискретизации 16 кГц, за одну секунду запоминается 16000 значений сигнала
2) так как глубина кодирования – 24 бита = 3 байта, для хранения 1 секунды записи требуется
16000 ´ 3 байта = 48 000 байт
(для стерео записи – в 2 раза больше)
3) на 1 минуту = 60 секунд записи потребуется
60 ´ 48000 байта = 2 880 000 байт,
то есть около 3 Мбайт
4) таким образом, правильный ответ – 3.
|
Возможные ловушки и проблемы: · если указано, что выполняется двухканальная (стерео) запись, нужно не забыть в конце умножить результат на 2 · могут получиться довольно большие числа, к тому же «некруглые» (к сожалению, использовать калькулятор по-прежнему запрещено) |
Еще пример задания:
Производится
одноканальная (моно) звукозапись с частотой дискретизации 64Гц. При записи
использовались 32 уровня дискретизации. Запись длится 4 минуты 16 секунд, её
результаты записываются в файл, причём каждый сигнал кодируется минимально
возможным и одинаковым количеством битов. Какое из приведённых ниже чисел
наиболее близко к размеру полученного файла, выраженному в килобайтах?
При записи
использовались 32 уровня дискретизации. Запись длится 4 минуты 16 секунд, её
результаты записываются в файл, причём каждый сигнал кодируется минимально
возможным и одинаковым количеством битов. Какое из приведённых ниже чисел
наиболее близко к размеру полученного файла, выраженному в килобайтах?
1) 10 2) 64 3) 80 4) 512
Решение:
1) так как частота дискретизации 64 Гц, за одну секунду запоминается 64 значения сигнала
2) глубина кодирования не задана!
3) используется 32 = 25уровня дискретизации значения сигнала, поэтому на один отсчет приходится 5 бит
4) время записи 4 мин 16 с = 4 ´ 60 + 16 = 256 с
5) за это время нужно сохранить
256 ´ 5 ´ 64 бит = 256 ´ 5 ´ 8 байт = 5 ´ 2 Кбайт = 10 Кбайт
6) таким образом, правильный ответ – 1.
|
Возможные ловушки и проблемы: · если указано, что выполняется двухканальная (стерео) запись, нужно не забыть в конце умножить результат на 2 · если «по инерции» считать, что 32 – это глубина кодирования звука в битах, то получим неверный ответ 64 Кбайта |
Дневники чайника
Дневники чайникаСистемы счисления и устройство памяти.

Второй день
Поскольку компьютер в основе своей имеет только 0 и 1, на первых этапах освоения ассемблера (может быть, год) нам будут нужны только целые числа, мало того, очень долго можно работать всего лишь с положительными целыми числами, о которых здесь и пойдёт речь.
Только целые и только положительные.
Возможно, вы проходили эту тему в школе, и кто-то из вас даже что-то помнит, но начинать нужно именно отсюда.
Нас будут интересовать 3 системы счисления — dec, bin, hex.
Десятичная — Decimal (Dec или буква «d»)
Aрабская система — она называется десятичной, потому что в ней используются 10 символов.
0,1,2,3,4,5,6,7,8,9
Все значения представляются этими символами. Вы и сами знаете, как пользоваться десятичной системой, так как мы все выросли на ней и каждую минуту чего-нибудь считаем.
Запомни, юнга! В космосе нет верха, нет низа — это всё условности. И то, что у тебя десять пальцев на руках, это всего лишь исключение. У наших бинарных братьев всего два пальца, они смеются над тобой — урод десятипалый :). У них есть на это право, их больше и они старше.
С Бинарниками надо дружить, иначе корабль собьют на подходе к первой же станции.
У наших бинарных братьев всего два пальца, они смеются над тобой — урод десятипалый :). У них есть на это право, их больше и они старше.
С Бинарниками надо дружить, иначе корабль собьют на подходе к первой же станции.
Двоичная система счисления — Binary (Bin или буква «b»)
Нетрудно догадаться, что двоичная система имеет всего два символа 0 и 1.
Компьютер — это очень простой прибор, в нём есть только выключатели — биты (вкл. =1, выкл. =0).
Понятие Bit, скорее всего, произошло от английских слов Binary — двоичная и Digit — цифра. Но поскольку битов о-о-очень много, биты строятся в байты.
11111111 - это байт 01010101 - и это байт 00000000 - и это тоже байт
Бит может иметь значение 0 или 1.
Байт — это 8 бит, и он может иметь значения от 0000 0000 — ноль, до 1111 1111 — 255 в десятичной системе
(пробелы для читаемости). Получается, что у байта 256 значений (всегда считается вместе с нулевым).
биты dec-цифры | биты dec-цифры 00000001 = 1 | 00001011 = 11 00000010 = 2 ! | 00001100 = 12 00000011 = 3 | 00001101 = 13 00000100 = 4 ! | 00001110 = 14 00000101 = 5 | 00001111 = 15 00000110 = 6 | 00010000 = 16 ! 00000111 = 7 | 00010001 = 17 00001000 = 8 ! | 00010010 = 18 00001001 = 9 | 00010011 = 19 00001010 = 10 | 00010100 = 20 И так до 11111111 = 255.
Переводить из десятичных цифр в биты (то есть в двоичные цифры) и обратно можно на виндовом калькуляторе (в инженерном режиме). Потренируйтесь пока так. Учить наизусть всю таблицу не нужно, познакомились — уже хорошо. :)
Как вы думаете, почему я выделил 2,4,8,16?
Правильно, это «круглые» цифры. В десятичной системе они, конечно, не круглые, но в двоичной получается 10,100,1000,10000. Поэтому десятичная система для компьютерных вычислений не очень подходит. Вместо неё используется…
Поэтому десятичная система для компьютерных вычислений не очень подходит. Вместо неё используется…
Шестнадцатиричная система счисления — Hexadecimal (Hex или буква «h»)
Имеет целых 16 символов. Чтоб не придумывать новые символы, в hex используются буквы латинского алфавита.
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F - это цифры
Я приравняю все hex-символы к десятичным значениям.
h d h d h d h d 0=0 4=4 8=8 C=12 1=1 5=5 9=9 D=13 2=2 6=6 A=10 E=14 3=3 7=7 B=11 F=15
В этой системе счисления ноль справа прибавляется при умножении на 16 (десятичных).
Лишние нули слева от числа значения не имеют, так же, как и в математике.
Однако если число начинается с буквы (A-F), ноль слева нужен при наборе программ. Иначе как компилятор будет определять, что началось число? А чтобы не путать числа в разных системах и писать при этом коротко, пишут:
d — десятичные значения
01,02,03,04,05,06,07,08,09,10d,11d,12d,13d,14d,15d,16d,17d,18d,19d,20d...
h — шестнадцатиричные значения
01,02,03,04,05,06,07,08,09,0Ah,0Bh,0Ch,0Dh,0Eh,0Fh,10h,11h,12h,13h,14h...
b — двоичные значения
0,1,10b,11b,100b...
Вот примеры:
01 * 16d = 10h (получается 16d) 10h * 16d = 100h (получается 256d) 100h * 16d = 1000h (получается 4096d) 1 * 10h = 10h 10h + 10h = 20h 10h * 10h = 100h 100h + 100h = 200h 10b * 10b = 100b
Удобно, правда? А вот так?
10d + 10h = 1Ah или 26d
Неудобно. Поэтому всегда ВСЕ ВЫЧИСЛЕНИЯ ДЕЛАЙТЕ В ОДНОЙ СИСТЕМЕ!
Сам я никогда не перевожу из hex в dec и в bin в уме или на листочке, для этого есть калькулятор.
И мне знакома эта растерянность перед новыми цифрами. Но я и не рассчитываю, что стало понятно хоть что-то.
Просто вы должны знать, что системы счисления hex & bin существуют.
Через месяц практики вы привыкнете к шестнадцатиричной системе как к родной. А вот двоичная будет использоваться только в пределах четырёх байт.
На экране монитора мне лишь изредка приходится видеть биты как «01011010», хотя часто их очень не хватает.
А вот двоичная будет использоваться только в пределах четырёх байт.
На экране монитора мне лишь изредка приходится видеть биты как «01011010», хотя часто их очень не хватает.
Теперь ещё раз про байт.
bin-числа hex-числа 00001000 = 08 00010000 = 10h 00100000 = 20h 01000000 = 40h 10000000 = 80h ... 11111111b = FFh
В байт умещаются ровно два разряда hex-системы счисления! Именно так мы и будем видеть байты. Вспомните наш нулевой эксперимент:
байты в hex символы в кодировке DOS (Р - русская буква) 90 41 90 41 90 90 41 41 42 43 44 | РAРAРРAABCD
Теперь вы понимаете, что я имел в виду, сказав: «90 здесь 144». Правильнее было бы сказать 90h = 144d.
Байт это 8 бит, и что самое главное, байт — минимально адресуемая ячейка памяти.
Если нужно прочитать информацию, например, из бита 900, то нам нужно обратиться к 112-му байту и посмотреть в нём бит номер 4.
| Адрес в байтах | Информация в БИТАХ
| | 76543210 - номера бит (разряд)
------|-------------------|-----------------------------------------------
111d | 0000006F | 00000000
112d | 00000070 | 000?0000
113d | 00000071 | 00000000
114d | 00000072 | 00000000
Конечно же, в компьютере физически биты не разделяются пробелами. Вся оперативная память, например, — сплошной поток выключателей :).
Но при отображении биты обычно разделяют на:
байты — 8 бит, две hex-цифры, или
тетрады — 4 бита, одна hex-цифра.
Обратите внимание на запись. Мы нумеруем биты справа налево и обязательно от нуля — это стандарт для учебников и документации. Кроме того, нумерация от нуля имеет математический смысл (разряды нужно осознать!).
Хотя так информацию мы видеть практически не будем. Вместо битов везде будут hex-байты, вот так:
Вместо битов везде будут hex-байты, вот так:
Адрес в байтах | Информация в БАЙТАХ
-------------------|---------------------------------------
0000006F | 00
00000070 | 00
00000071 | 00
00000072 | 00
или вот так:
Адрес в байтах | Информация в БАЙТАХ
-------------------|---------------------------------------
0000006F | 00 00 00 00
Здесь вынужден заметить: адреса в файле и адреса в оперативной памяти — это совершенно разные вещи.
Далее по тексту я буду грубо писать: «адрес в памяти», под этими словами мы будем подразумевать часть логического адреса,
которую принято называть смещением (offset). В рамках наших уроков смещение — вполне достаточный адрес в памяти.
Однако смещение — это не полный логический адрес и называть смещение адресом без оговорок — довольно грубо!
В следующем витке мы обязательно разберём адресацию памяти в разных режимах процессора, и там я расскажу,
что такое сегмент и смещение.
А сейчас запомните. Когда я пишу: адрес в файле, я подразумеваю номер байта в файле от нуля. И это норма. А вот когда я пишу: адрес в памяти, это значит, что речь идёт о части логического адреса, называемой смещением (тоже от нуля).
Да простят меня профи за такую вольность.
Юнга, после обеда я научу тебя писать дельные программы для вспомогательного бортового оборудования. Ты, конечно, пуст, как первая ступень, и ни черта не понял за сегодня, но у меня нет времени рассусоливать, нас давно ждут.
Первая полезная программа
Что там у нас дальше по учебнику? Этого вам пока не надо… Этого я и сам ещё не знаю… Тут слишком много умностей… Нет, пожалуй, продолжу, как предложил Олег Калашников. Пожалуй, лучший подход для любителей практики.
Эксперимент 01 (prax01.com)
Я по-прежнему подразумеваю, что вы используете WinXP и пример должен работать.
Создайте файл с расширением «com» (напомню в FAR’e — Shift+F4). Назвав файл, напечатайте в нём любую букву или цифру, ну, допустим, «1».
Сохраните файл (в FAR’e — Esc).
Назвав файл, напечатайте в нём любую букву или цифру, ну, допустим, «1».
Сохраните файл (в FAR’e — Esc).
Нет, это ещё не программа, этот файл выполнять не нужно. Откройте в Hiew’e.
Сейчас вы видите 1, если нажать «F4» (Mode), то, как и в тот раз, вы увидите байт в hex-виде. F4 еще раз покажет дизассемблерный код. Если в файле единица, то выглядеть код будет так:
Адреса Байты Имена Операнды 00000000: 31 xor [bx][si],ax
В отличие от команды nop, которую вы уже видели, большинство команд используют предметы для действия.
Предмет, с (или над) которым производится действие, называется операнд.
Операнды в ассемблере для Интел-совместимых процессоров принято разделять запятыми.
То есть в некоторых системах или в других языках программирования пишут:
AX xor 44
или вполне может быть такая форма записи:
44,55 xоr AX
Но в x86 ассемблере принято писать так:
xor AX,44 где AX - операнд 1 (он же приёмник), а 44 - операнд 2 (он же источник).
Из всего этого главное сейчас усвоить, что операндов не больше трёх (чащё всего 2), они разделяются запятыми и идут после имени команды. Давайте писать настоящую программу на ассемблере.
В Hiew’e (когда вы видите дизассемблерный код нашего файла) нажмите F3 и затем Enter. Теперь можно набирать программу на ассемблере (символ «1» в файле должен стереться). Каждая инструкция вводится Enter’ом и превращается в строку, если нет явной ошибки. Пробелы нужны только для удобства, поэтому неважно, сколько их. Пишите как хотите, строчными или прописными буквами, но только по-англицки. :)
Вот код программы, его нужно набрать:
mov ah,9 mov dx,10Dh int 21h mov ah,10h int 16h int 20h
Когда всё напишете, нажмите один раз Esc, чтобы прекратить ассемблирование, и F9, чтобы сохранить файл.
Это был весь код программы, которая должна выводить строку на экран! Круто, правда? Только не хватает самой строки.
Для того, чтоб вписать строку, нужно открыть файл в текстовом редакторе (в FAR’e — F4).
Допишите после всех закорючек (только не сотрите ничего) любую текстовую строку и в конце поставьте знак $.
Это может выглядеть примерно так:
_?_? _?_?_?_?_Good Day!$
Закорючки будут другие, но вид такой. Сохраните программу. Откройте снова в Hiew’e.
Адреса Маш.команды Команды Асма комментарии
Байты Имена Операнды
00000000: B409 mov ah,009 ; Поместить значение 9 в регистр AH (параметр1)
00000002: BA0D01 mov dx,0010D ; Поместить адрес текстовой строки в DX (параметр2)
00000005: CD21 int 021 ; Вызвать подпрограмму, в которой
; отработает функция вывода текста на экран (AH=09)
00000007: B410 mov ah,010 ; Поместить значение 10h в регистр AH (параметр1)
00000009: CD16 int 016 ; Вызвать подпрограмму ожидания нажатия клавиши
0000000B: CD20 int 020 ; Подпрограмма завершения
0000000D: 47 inc di
0000000E: 6F outsw
0000000F: 6F outsw
00000010: 64204461 and fs:[si][61],al
00000014: 7921 jns 000000037 ---X
00000016: 24 and al,000
Принято так, что после точки с запятой идёт комментарий, просто пояснение для людей. В этом примере я откомментировал все строки кода программы. Только вам от этого пока не легче.
В этом примере я откомментировал все строки кода программы. Только вам от этого пока не легче.
Видите, начиная с адреса в файле 0000000Dh, появились команды, которые вы не писали, это всего лишь строка текста. Её процессор выполнять не будет только потому, что перед строкой текста стоит код завершения (int 20).
Запустите программу (можно из проводника)… Если компьютер с вами поздоровался — я вас тоже поздравляю! Значит, у вас есть шанс научить его делать и более сложные вещи.
| Вы увидите окно DOS-приложения с текстом: Good Day! Нажатие на любую клавишу вызовет выход из программы. |
Если же этого не произошло — не расстраивайтесь. Перепроверьте всё несколько раз, может быть, вы опечатались.
Прочитайте «Аннотацию» в последней главе или комментарии. Я пока ничего подобного не написал, но, возможно, когда-нибудь придётся.
Ведь у нас нет гарантии, что новые твАрения MS или других «рук» не изменят ситуацию в худшую сторону. Хотя, будем надеяться, что программа заработает и на новых OS’ях и процессорах.
Хотя, будем надеяться, что программа заработает и на новых OS’ях и процессорах.
«$» не выводится. Хм, интересно :/ Это условный символ конца строки?
Да, но в windows мы будем использовать нулевой байт (00h) для этой же цели.
Вот, уже получилась полнофункциональная программа для DOS, которая будет работать и в Windows.
Прямо так и вижу следующие «почему»:
Почему mov?
Почему ah?
Почему 9?
И вообще, что это за подпрограммы-прерывания int 16, int 21, int 20.
Последний вопрос меня тоже очень огорчил, когда впервые столкнулся с этим примером. Я ожидал получить программу на чистом Ассемблере, а был вынужден использовать какие-то непонятные функции, которых не писал.
На самом деле вывод строки на экран без специальной DOS-функции ничуть не сложнее.
Мы используем именно такой способ из-за того, что он наиболее схож с программированием под Win.
Здесь было бы аккуратнее и быстрее выводить на экран без специальной подпрограммы DOS-функций.
Но ДОС в прошлом, а нас ждёт Win32.
Cамое главное не переживать, если вы вдруг не понимаете что здесь к чему, поверьте, через пару уроков вы полностью поймёте эту программу.
Мы завтра весь день будем искать ответ на вопрос «Почему ah», так как этот «почему» — самый важный во всём ассемблере. Серьёзно!
Bitfry
Решение: I = 16 бит I = K*i
РАЗБОР ЗАДАЧ, АНАЛОГИЧНЫХ КОНТРОЛЬНОЙ РАБОТЕ №1
ЧЕЛОВЕК И ИНФОРМАЦИЯ
В кодировке Windows каждый символ кодируется 16 битами. Определите информационный объем сообщения в битах:
С днем рождения!
Чтобы записать данные необходимо подсчитать количество символов в выделенном сообщении, считая и пробелы и знаки препинания.
Дано: Решение:
i = 16 бит I = K*i
K = 16 I = 16*16 = 256 бит
Найти:
I
— ? (бит) Ответ:
256 бит.
Рассказ, набранный на компьютере, содержит 4 страницы, на каждой странице 32 строки, в каждой строке 64 символа. Определите информационный объём рассказа в кодировке Unicode, в которой каждый символ кодируется 8 битами. Ответ получить в Килобайтах.
Дано: Решение:
i = 8 бит I = K*i
K = 4*32*64 I = 4*32*64*8 бит = Кбайт = =
Найти: = Кбайт = 22 Кбайта = 4 Кбайта
I — ? (Кбайт) Ответ: 4 Кбайта.
Сколько Кбайт информации содержит сообщение объемом
16384 байт?
Решение:
1 Кбайт = 1024 байта
16384 байт = 16384 : 1024 = 16 Кбайт
Сколько бит информации содержит сообщение объемом
100 байт?
Решение:
1 байт = 8 бит
100 байт = 100*8 = 800 бит
Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке длиной в 320 символов, первоначально записанного в 2-байтном коде, в 8-битную кодировку.
 На
сколько
байт
уменьшилось
сообщение?
На
сколько
байт
уменьшилось
сообщение?
Дано: Решение:
i1 = 2 байта I1 = K*i1 I2 = K*i2
i2 = 8 бит I1 – I2 = K*i1 – K*i2 = K*(i1 – i2)
K = 320 i2 = 8 бит = 8 : 8 = 1 байт
Найти: I1 — I2 = 320*(2 – 1) байт = 320 байт
I1 — I2? (байт) Ответ: на 320 байт.
Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 16-битном коде Unicode, в 8-битную кодировку КОИ-8. При этом информационное сообщение уменьшилось на 100 байт. Какова длина сообщения в символах?
Дано: Решение:
i1 = 16 бит I1 = K*i1 I2 = K*i2
i2 = 8 бит I1 – I2 = K*i1 – K*i2 = K*(i1 – i2)
I1 — I2 = 100 байт K = = = = 100 символов
Найти:
K
— ? (символов) Ответ:
100
символов.
Задачи для самостоятельного решения:
В кодировке Windows каждый символ кодируется 8 битами. Определите информационный объем сообщения в битах:
У Лукоморья дуб зеленый
Считая, что каждый символ кодируется 16 битами, оцените информационный объем следующего предложения в кодировке Unicode:
Один пуд — около 16,4 килограмм.
В кодировке Windows каждый символ кодируется 8 битами. Определите информационный объем сообщения в битах:
Сижу за решеткой в темнице сырой
Каждый символ закодирован 8 битами. Оцените информационный объем следующего предложения в этой кодировке:
В одном килограмме 1000 грамм.
Рассказ, набранный на компьютере, содержит 2 страницы, на каждой странице 32 строки, в каждой строке 64 символа.
 Определите
информационный объём рассказа в
кодировке Unicode, в которой каждый символ
кодируется 16 битами. Ответ
получить в Килобайтах.
Определите
информационный объём рассказа в
кодировке Unicode, в которой каждый символ
кодируется 16 битами. Ответ
получить в Килобайтах.Статья, набранная на компьютере, содержит 20 страниц, на каждой странице 40 строк, в каждой строке 48 символов. В одном из представлений Unicode каждый символ кодируется 16 битами. Определите информационный объём статьи в этом варианте представления Unicode. Ответ получить в Килобайтах.
Рассказ, набранный на компьютере, содержит 2 страницы, на каждой странице 32 строки, в каждой строке 64 символа. Определите информационный объем рассказа в кодировке Unicode, в которой каждый символ кодируется 16 битами. Ответ запишите в Кбайтах.
Статья, набранная на компьютере, содержит 10 страниц, на каждой странице 32 строки, в каждой строке 56 символов. В одном из представлений Unicode каждый символ кодируется 2 байтами. Определите информационный объём статьи в этом варианте представления Unicode.
 Ответ получить в Килобайтах.
Ответ получить в Килобайтах.Сколько байт информации содержит сообщение объемом 0, 5 Кбайт?
Сколько Кбайт информации содержит сообщение объемом
8192 байт?Сколько Мбайт информации содержит сообщение объемом 1024 Кбайт?
Сколько байт информации содержит сообщение объемом 0,5 Кбайт?
Текстовый документ, состоящий из 3072 символов, хранился в 8-битной кодировке. Этот документ был преобразован в 16-битную кодировку. Укажите, какое дополнительное количество Кбайт потребуется для хранения документа.
Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке длиной в 100 символов, первоначально записанного в 2-байтном коде, в 8-битную кодировку. На сколько бит уменьшилось сообщение?
Текстовый документ, состоящий из 5120 символов, хранился в 8-битной кодировке КОИ-8.
 Этот
документ был преобразован в 16-битную
кодировку Unicode.
Укажите, какое дополнительное количество
Кбайт
потребуется для хранения документа.
Этот
документ был преобразован в 16-битную
кодировку Unicode.
Укажите, какое дополнительное количество
Кбайт
потребуется для хранения документа.
Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 16-битном коде Unicode, в 8-битную кодировку КОИ-8. При этом информационное сообщение уменьшилось на 60 байт. Какова длина сообщения в символах?
1 символ это сколько бит
На чтение 5 мин. Просмотров 118 Опубликовано
Я просто смущен. сколько символов в одном бите?
Это зависит от характера и того, в каком кодировании он находится:
Символ ASCII в 8-разрядной кодировке ASCII составляет 8 бит (1 байт), хотя он может поместиться в 7 бит.
Символ ISO-8895-1 в кодировке ISO-8859-1 составляет 8 бит (1 байт).
Символ Unicode в кодировке UTF-8 находится между 8 битами (1 байт) и 32 битами (4 байта).
Символ Юникода в кодировке UTF-16 находится между 16 (2 байтами) и 32 битами (4 байта), хотя большинство общих символов принимают 16 бит. Это кодировка, используемая Windows внутренне.
Символ Unicode в кодировке UTF-32 всегда 32 бита (4 байта).
Символ ASCII в UTF-8 — 8 бит (1 байт), а в UTF-16 — 16 бит.
Дополнительные символы (не ASCII) в ISO-8895-1 (0xA0-0xFF) будут принимать 16 бит в UTF-8 и UTF-16.
Это означало бы, что между 0.03125 и 0.125 символами.
Один бит это 1/8 (одна восьмая или 0.125 символа). Из учебника информатики мы знаем что для того чтобы записать один символ нам нужен 1 байт, который состоит из 8 бит, отсюда 1 бит это 1/8 символа или 0.125 символа. Почему 1 символ это байт? Все дело в том что машина (компьютер) не понимает наши буквы и символы, она понимает только значения «верно» и «ложь» которые записаны в двоичном коде (то есть при помощи двух символов 1 и 0). Соответственно для того чтобы закодировать один из 256 символов при помощи нолей и единиц нам потребуется восемь мест в каждом из которых может быть только один из двух вариантов: единица или ноль. Таким местом как раз и является один бит который может содержать только ноль или единицу, а вот последовательность из восьми нолей или единиц можно описать один из 256 символов. Таким образом и получается что для записи одного символа нам нужно 8 бит или один байт.
Соответственно для того чтобы закодировать один из 256 символов при помощи нолей и единиц нам потребуется восемь мест в каждом из которых может быть только один из двух вариантов: единица или ноль. Таким местом как раз и является один бит который может содержать только ноль или единицу, а вот последовательность из восьми нолей или единиц можно описать один из 256 символов. Таким образом и получается что для записи одного символа нам нужно 8 бит или один байт.
UTF-8 (от англ. Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования текста, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII. Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D. Кодировка UTF-8 сейчас является доминирующей в веб-пространстве. Она также нашла широкое применение в UNIX-подобных операционных системах [1] . Формат UTF-8 был разработан 2 сентября 1992 года Кеном Томпсоном и Робом Пайком, и реализован в Plan 9 [2] . Идентификатор кодировки в Windows – 65001 [3] .
Формат UTF-8 был разработан 2 сентября 1992 года Кеном Томпсоном и Робом Пайком, и реализован в Plan 9 [2] . Идентификатор кодировки в Windows – 65001 [3] .
Сравнивая UTF-8 и UTF-16, можно отметить, что наибольший выигрыш в компактности UTF-8 даёт для текстов на латинице, поскольку латинские буквы без диакритических знаков, цифры и наиболее распространённые знаки препинания кодируются в UTF-8 лишь одним байтом, и коды этих символов соответствуют их кодам в ASCII. [4] [5]
Содержание
Алгоритм кодирования [ править | править код ]
Алгоритм кодирования в UTF-8 стандартизирован в RFC 3629 и состоит из 3 этапов:
1. Определить количество октетов (байтов), требуемых для кодирования символа. Номер символа берётся из стандарта Юникод.
| Диапазон номеров символов | Требуемое количество октетов |
|---|---|
| 00000000-0000007F | 1 |
| 00000080-000007FF | 2 |
| 00000800-0000FFFF | 3 |
| 00010000-0010FFFF | 4 |
Для символов Юникода с номерами от U+0000 до U+007F (занимающими один байт c нулём в старшем бите) кодировка UTF-8 полностью соответствует 7-битной кодировке US-ASCII.
2. Установить старшие биты первого октета в соответствии с необходимым количеством октетов, определённом на первом этапе:
- 0xxxxxxx — если для кодирования потребуется один октет;
- 110xxxxx — если для кодирования потребуется два октета;
- 1110xxxx — если для кодирования потребуется три октета;
- 11110xxx — если для кодирования потребуется четыре октета.
Если для кодирования требуется больше одного октета, то в октетах 2-4 два старших бита всегда устанавливаются равными 102 (10xxxxxx). Это позволяет легко отличать первый октет в потоке, потому что его старшие биты никогда не равны 102.
| Количество октетов | Значащих бит | Шаблон |
|---|---|---|
| 1 | 7 | 0xxxxxxx |
| 2 | 11 | 110xxxxx 10xxxxxx |
| 3 | 16 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
3. Установить значащие биты октетов в соответствии с номером символа Юникода, выраженном в двоичном виде. Начать заполнение с младших битов номера символа, поставив их в младшие биты последнего октета, продолжить справа налево до первого октета. Свободные биты первого октета, оставшиеся незадействованными, заполнить нулями.
Установить значащие биты октетов в соответствии с номером символа Юникода, выраженном в двоичном виде. Начать заполнение с младших битов номера символа, поставив их в младшие биты последнего октета, продолжить справа налево до первого октета. Свободные биты первого октета, оставшиеся незадействованными, заполнить нулями.
Примеры кодирования [ править | править код ]
| Символ | Двоичный код символа | UTF-8 в двоичном виде | UTF-8 в шестнадцатеричном виде | |
|---|---|---|---|---|
| $ | U+0024 | 100100 | 0 0100100 | 24 |
| ¢ | U+00A2 | 10 100010 | 110 00010 10 100010 | C2 A2 |
| € | U+20AC | 10 0000 10 101100 | 1110 0010 10 000010 10 101100 | E2 82 AC |
| U+10348 | 1 0000 0011 01 001000 | 11110 000 10 010000 10 001101 10 001000 | F0 90 8D 88 | |
Маркер UTF-8 [ править | править код ]
Для указания, что файл или поток содержит символы Юникода, в начале файла или потока может быть вставлен маркер последовательности байтов (англ. Byte order mark, BOM ), который в случае кодирования в UTF-8 принимает форму трёх байтов: EF BB BF16 .
Byte order mark, BOM ), который в случае кодирования в UTF-8 принимает форму трёх байтов: EF BB BF16 .
| 1-й байт | 2-й байт | 3-й байт | |
|---|---|---|---|
| Двоичный код | 1110 1111 | 1011 1011 | 1011 1111 |
| Шестнадцатеричный код | EF | BB | BF |
Пятый и шестой байты [ править | править код ]
Изначально кодировка UTF-8 допускала использование до шести байтов для кодирования одного символа, однако в ноябре 2003 года стандарт RFC 3629 запретил использование пятого и шестого байтов, а диапазон кодируемых символов был ограничен символом U+10FFFF . Это было сделано для обеспечения совместимости с UTF-16.
c — Путаница в 16-битном диапазоне типов данных
Я думаю, вы смешиваете две вещи:
- Какие диапазоны стандарт требует для
подписанных символов,intи т. Д. - Какие диапазоны? В настоящее время реализовано в большинстве аппаратных средств.

Они не обязательно должны быть одинаковыми, если реализованный диапазон является надмножеством диапазона, требуемого стандартом.
Согласно стандарту C, определяемые реализацией значения SCHAR_MIN и SCHAR_MAX должны быть равны или больше по величине (абсолютному значению) и иметь тот же знак, что и:
СЧАР_МИН-127
SCHAR_MAX +127
и.е. только 255 значений, не 256 .
Однако пределы, определенные соответствующей реализацией, могут быть «больше» по величине, чем эти. то есть [-128, + 127] тоже разрешено стандартом. А поскольку большинство машин представляют числа в форме дополнения до 2, [-128, + 127] — это диапазон, который вы будете видеть чаще всего.
На самом деле, и минимальный диапазон int , определенный стандартом C, равен симметрично относительно нуля.Это:
INT_MIN -32767
INT_MAX +32767
то есть только 65535 значений, не 65536 .
Но опять же, большинство машин используют представление с дополнением до 2, а это означает, что они предлагают диапазон [-32768, + 32767] .
Хотя в форме дополнения до 2 можно представить 256 значений со знаком в 8 битах (т. Е. [-128, + 127] ), существуют другие представления чисел со знаком, где это невозможно.
В представлении «знак-величина» один бит зарезервирован для знака, поэтому:
00000000
10000000
означают одно и то же, то есть 0 (точнее, +0 и -0 ).
Это означает, что одно значение теряется. Таким образом, знаковое представление может содержать значения от -127 ( 11111111 ) до +127 ( 01111111 ) в 8 битах.
В представлении дополнения до единицы (отрицать, выполняя побитовое НЕ):
00000000
11111111
означают одно и то же, т.е.е. 0 .
Опять же, только значения от -127 ( 10000000 ) до +127 ( 01111111 ) могут быть представлены в 8 битах.
Если стандарт C требовал, чтобы диапазон был [-128, + 127] , то это по существу исключило бы возможность машин, использующих такие представления, эффективно запускать программы C. Им потребуется дополнительный бит для представления этого диапазона, поэтому для хранения подписанных символов потребуется 9 битов вместо 8. Логический вывод, основанный на вышеизложенном: Вот почему стандарт C требует [-127, + 127] для подписанных символов. символы.то есть предоставить реализациям свободу выбора формы целочисленного представления, которая соответствует их потребностям, и в то же время иметь возможность эффективно придерживаться стандарта. Та же логика применима и к int .
— как 32-битное слово будет храниться в 16-битной архитектуре, которая не обнаруживает переполнения?
как 32-битное числовое кодовое слово будет храниться в 16-битной архитектуре …
Простое сохранение информации не требует каких-либо функций центрального процессора.
Для хранения N бит данных вам потребуется N / 8 байт памяти.
Это программное обеспечение (а не оборудование) должно «знать», содержат ли четыре байта одно 32-битное слово, 32-битное значение с плавающей запятой, два 16-битных слова, 4 8-битных слова или 32 одиночных бита. .
Если вы пишете программу на ассемблере, вы должны писать программу соответственно. Если вы используете какой-либо язык программирования, компилятор должен это сделать.
… если эта система не может обнаружить переполнение ?
Расчет (особенно сложение) — другое дело.Если вы ссылаетесь на «флаг переноса» словом «переполнение»:
Вы можете проверить перенос вручную: если вы сложите два числа и произойдет перенос, сумма будет меньше, чем каждое из двух слагаемых. Если переноса нет, сумма будет больше или равна каждому слагаемому.
Когда вы выполняете 64-битное сложение на ЦП MIPS (32-битный ЦП не поддерживает флаг переноса ) с помощью компилятора GCC, эта проверка будет выполнена. Здесь псевдокод:
Здесь псевдокод:
sum_low = a_low + b_low
// ЦП не поддерживает перенос:
sum_high = a_high + b_high
// Имитация переноса:
если (a_low> sum_low) sum_high = sum_high + 1
Как он будет храниться в системе 6811?
Насколько мне известно, 6811 использует память с прямым порядком байтов.Это означает, что сам ЦП хранит 16-битные слова (например, счетчик программ) таким образом, что старшие 8 бит сохраняются по адресу N , а младшие 8 бит сохраняются по адресу N + 1 .
По этой причине большинство компиляторов также сохраняют 32-битное слово «big endian»: старшие 8 бит сохраняются по адресу N , а младшие 8 бит сохраняются по адресу N + 3 .
6811 определенно поддерживает «флаг переноса», добавляя с переносом и «флагом переполнения».Таким образом, 6811 не является примером ЦП, «не обнаруживающего переполнения». См. Ответ old_timer , как добавление работает на процессорах, у которых есть переполнение и перенос.
Типы и битовая глубина · Анализ изображений флуоресцентной микроскопии с помощью ImageJ
При этом иногда необходимо преобразовать тип изображения или битовая глубина, и тогда рекомендуется соблюдать осторожность.
Иногда такое преобразование может потребоваться против ваше суждение, но у вас мало выбора, потому что команда или плагин, которые вам нужны, были написаны только для определенных типов изображения.И хотя это может быть редким событием, процесс достаточно неинтуитивно, чтобы требовать особого внимания.
Преобразования применяются в ImageJ с помощью команд в
подменю. Три верхних варианта: 8-бит (беззнаковый
целое число), 16-битное (целое число без знака) и 32-битное (с плавающей запятой),
которые соответствуют поддерживаемым в настоящее время типам.
Как правило, , увеличивая битовой глубины изображения, не должно изменять
значения пикселей: более высокая битовая глубина может хранить все значения, которые ниже
битовые глубины можно хранить. Но в обратном направлении это не так, и когда
уменьшение глубины бит может произойти одно из двух в зависимости от
будет ли опция
Но в обратном направлении это не так, и когда
уменьшение глубины бит может произойти одно из двух в зависимости от
будет ли опция Scale при преобразовании под
проверено или нет.
-
Масштаб при преобразованиине проверено : пикселям просто дается ближайшее допустимое значение в пределах новой разрядности, т.е. есть отсечение и округление по мере необходимости. -
Масштаб при конвертациипроверяется : добавляется константа или вычитается, затем пиксели делятся на другую константу перед присваивается ближайшему допустимому значению в пределах новой разрядности.Только , затем применяется отсечение или округление, если это все еще необходимо.
Возможно, удивительно, что константы, участвующие в масштабировании, определены
от Минимум и Максимум в текущем Яркость / Контраст…
настройки: Минимум вычитается, а результат делится на
Максимум — Минимум . Любое значение пикселя ниже
Любое значение пикселя ниже Минимум или
выше Максимум заканчивается обрезкой.Следовательно, конвертирующих
на меньшую битовую глубину с масштабированием может привести к другим результатам
в зависимости от того, какие настройки яркости и контрастности были .
бит в килобайты Калькулятор битов преобразования
в килобайтыПреобразование бит в килобайты . Введите значение бит (b) для преобразования в килобайты (КБ).
Сколько килобайт в бите
1 бит равен (1/8) × 10 0-3 килобайт.
1 бит = (1/8) × 10 -3 килобайт.
1 бит = (1/8) × 0,001 килобайт.
1 b = 0,000125 КБ .
В бите 0,000125 килобайт.
| Биты (b) | Килобайт (КБ) |
|---|---|
| 10 0 бит | 10 3 × 8 бит |
| 1 бит | 8000 бит |
| 10 3 байтов | |
0. 125 байт 125 байт | 1000 байт |
Биты
Бит (b) — это единица измерения, используемая в двоичной системе для хранения или передачи данных, таких как скорость интернет-соединения или шкала качества аудио- или видеозаписи. Бит обычно представлен 0 или 1. 8 бит составляют 1 байт. Бит также может быть представлен другими значениями, такими как да / нет, истина / ложь, плюс / минус и т. Д. Бит — это одна из основных единиц, используемых в компьютерных технологиях, информационных технологиях, цифровой связи, а также для хранения, обработки и передачи различных типов данных.
1 бит = 1000 0 бит
1 бит = 1 × (1/8000) килобайт
1 бит = (1/8000) килобайт
1 бит = 0,000125 КБ
Килобайт
Килобайт (КБ) — это обычная единица измерения цифровой информации (включая текст, звук, графику, видео и другие виды информации), равная 1000 байтам. В практических информационных технологиях килобайт фактически равен 2 10 байтам, что делает его равным 1024 байтам.Десятилетия назад эта единица измерения была одной из самых популярных, но в последнее время, когда объемы информации резко возросли, такая единица измерения, как гигабайт, стала более распространенной.
В практических информационных технологиях килобайт фактически равен 2 10 байтам, что делает его равным 1024 байтам.Десятилетия назад эта единица измерения была одной из самых популярных, но в последнее время, когда объемы информации резко возросли, такая единица измерения, как гигабайт, стала более распространенной.
1 килобайт = 1000 байт
1 байт = 8 бит
1 килобайт = 8000 бит
1 бит = (1/8000) КБ
Таблица преобразования бит в Килобайт
| Биты (b) | килобайт (КБ) |
|---|---|
| 1 бит | 0.000125 кб 0,00075 KB |
| 7 бит | 0,000875 KB |
| 8 бит | 0,001 KB |
| 9 бит | 0,001125 KB |
| 10 бит | 00125 кб 0,001875 КБ|
| 16 бит | 0,002 КБ |
| 17 бит | 0,002125 КБ |
| 18 бит | 0,00225 КБ |
| 19 бит | 0. 002375 кб 0,003 КБ 002375 кб 0,003 КБ |
| 25 бит | 0,003125 КБ |
| 26 бит | 0,00325 КБ |
| 27 бит | 0,003375 КБ |
| 28 бит | 0.0035 кб 0,004125 КБ |
| 34 бит | 0,00425 КБ |
| 35 бит | 0,004375 КБ |
| 36 бит | 0,0045 КБ |
| 37 бит | 0.004625 KB |
| 38 бит | 0,00475 KB |
| 39 бит | 0,004875 KB |
| 40 бит | 0,005 KB |
| Биты (b) | килобайт (КБ) |
|---|---|
| 100 бит | 0,0125 КБ |
| 200 бит | 0,025 КБ |
| 300 бит | 0,0375 КБ |
| 400 бит | 0.05 КБ |
| 500 бит | 0,0625 КБ |
| 600 бит | 0,075 КБ |
| 700 бит | 0,0875 КБ |
| 800 бит | 902 0,1 КБ 0,1125 КБ |
| 1000 бит | 0,125 КБ |
| 1100 бит | 0,1375 КБ |
| 1200 бит | 0,15 КБ |
| 1300 бит | 0. 1625 КБ 1625 КБ |
| 1400 бит | 0,175 КБ |
| 1500 бит | 0,1875 КБ |
| 1600 бит | 0,2 КБ |
| 1700 бит | |
| 1700 бит | |
| 1900 бит | 0,2375 КБ |
| 2000 бит | 0,25 КБ |
| 2100 бит | 0,2625 КБ |
| 2200 бит | 275 кб 0,3375 КБ|
| 2800 бит | 0,35 КБ |
| 2900 бит | 0,3625 КБ |
| 3000 бит | 0,375 КБ |
| 3100 бит 0.3875 кб 0,45 КБ | |
| 3700 бит | 0,4625 КБ |
| 3800 бит | 0,475 КБ |
| 3900 бит | 0,4875 КБ |
| 4000 бит | |
| 4000 бит | 5 КБ
© 2014-2021 www.GbMb.org
битовая глубина изображения | Shutha
Напоминание о том, что такое «бит»
Возможно, стоит начать с того, чтобы напомнить вам, что такое «бит». Помните, что каждый пиксель - это просто двоичное число, представляющее его цвет. Помните также, что для представления 256 тонов в пикселе потребовалось двоичное число длиной 8 цифр (11111111), чтобы представить это количество тонов.Теперь каждая цифра в этом числе представляет собой 1 бит информации, и поэтому мы получили цвет пикселя, представленный числом размером 8 бит. Таким образом, количество возможных цветов пикселя в градациях серого составляет 256 цветов, и это представлено двоичным числом, которое составляет «8 бит в глубину».
Помните, что каждый пиксель - это просто двоичное число, представляющее его цвет. Помните также, что для представления 256 тонов в пикселе потребовалось двоичное число длиной 8 цифр (11111111), чтобы представить это количество тонов.Теперь каждая цифра в этом числе представляет собой 1 бит информации, и поэтому мы получили цвет пикселя, представленный числом размером 8 бит. Таким образом, количество возможных цветов пикселя в градациях серого составляет 256 цветов, и это представлено двоичным числом, которое составляет «8 бит в глубину».
Теперь это число не обязательно должно иметь глубину 8 бит. Он может иметь длину 10, 12, 14 или 16 бит, и каждый раз, когда он становится длиннее, он может представлять намного больше вариаций цвета.
Таким образом, «вес» одного пикселя в оттенках серого составляет 8 бит, который также известен как 1 байт (8 бит = 1 байт в компьютерном языке).Но это также может быть 16 бит, что составляет 2 байта.
И вес 8-битного изображения RGB в 3 раза больше, потому что есть одно 8-значное число для каждого цветового канала в пикселе RGB - 1 для красного канала, 1 для зеленого канала и 1 для синего канала, что делает он размером 3 байта. Но это изображение RGB может иметь глубину цвета 16 бит, и в этом случае каждый из трех цветовых каналов будет иметь номер длиной 16 цифр, то есть размером 16 бит, что составляет 2 байта на канал цвета, что означает, что каждый Размер пикселя 16-битного изображения RGB составляет 6 байтов.
Но это изображение RGB может иметь глубину цвета 16 бит, и в этом случае каждый из трех цветовых каналов будет иметь номер длиной 16 цифр, то есть размером 16 бит, что составляет 2 байта на канал цвета, что означает, что каждый Размер пикселя 16-битного изображения RGB составляет 6 байтов.
Реальное преимущество 16-битного изображения перед 8-битным, однако, заключается не в размере файла, а в вариациях цвета, которые оно представляет.
Битовая глубина и Photoshop
Любое изображение на доцифровой стадии, будь то фотографируемая сцена или сканируемая аналоговая пленка (например, 35-миллиметровый негатив или прозрачная пленка), имеет непрерывный диапазон тонов. Однако после цифровой фотографии или сканирования цифровой файл записывается путем разделения изображения на несколько уровней тона.Это может быть от 8 до 16 бит на канал цвета в зависимости от программного обеспечения сканера и ограничений оборудования.
Рис. 1 Реальность, которую мы воспринимаем человеческим глазом, - это непрерывный тон. Однако, когда он снимается на сканер или цифровую камеру, каждый пиксель, представляющий эту реальность, должен быть представлен двоичным числом определенной длины или «битовой глубины». Когда изображение переносится в Photoshop, оно рассматривается как 8-битное или 16-битное изображение.После того, как кто-то работал с изображением, вам всегда нужно выводить для других в 8-битном формате, поскольку это то, с чем работает отрасль.
Однако, когда он снимается на сканер или цифровую камеру, каждый пиксель, представляющий эту реальность, должен быть представлен двоичным числом определенной длины или «битовой глубины». Когда изображение переносится в Photoshop, оно рассматривается как 8-битное или 16-битное изображение.После того, как кто-то работал с изображением, вам всегда нужно выводить для других в 8-битном формате, поскольку это то, с чем работает отрасль.
Независимо от того, сколько уровней камера или сканер может обнаружить и сохранить, файл может быть только в 8- или 16-битном формате, когда он открыт в Photoshop. Если камера или отсканированное изображение имеют что-то вроде 12-битного, то экспорт как 16-битный файл в Photoshop не улучшает 12-битное сканирование; это просто гарантирует, что будут сохранены полные 12 бит. 12-битное изображение, импортированное как 16-битный файл, по-прежнему содержит только 12 бит информации об уровне.
16-битный файл имеет в два раза больше двоичных цифр для каждого канала RGB, но все равно имеет то же количество пикселей. Но поскольку каждый пиксель содержит вдвое больше информации, это означает, что размер 16-битного файла также вдвое превышает размер рабочего файла, чем 8-битного файла. В конце концов, какой бы разрядностью ни были захвачены изображения, а затем они обрабатывались, конечный результат, предоставляемый публике, должен быть в 8-битном формате, так как большинство создателей изображений не понимают 16-битные изображения.
Но поскольку каждый пиксель содержит вдвое больше информации, это означает, что размер 16-битного файла также вдвое превышает размер рабочего файла, чем 8-битного файла. В конце концов, какой бы разрядностью ни были захвачены изображения, а затем они обрабатывались, конечный результат, предоставляемый публике, должен быть в 8-битном формате, так как большинство создателей изображений не понимают 16-битные изображения.
ПРИМЕЧАНИЕ: Существуют также 1-битные изображения, но они не будут использоваться для фотографий, поскольку они могут содержать только два тона черного и белого.16 = 65 536), что намного превосходит то, что может видеть человеческий глаз. Тем не менее, сканирование в 16-битном режиме дает реальные преимущества. Например, возьмите это изображение ниже.
Рис. 2 Изображение вверху сильно недоэкспонировано. Гистограмма ниже показывает, как она была сжата до небольшой части общего тонального диапазона.
Рис. 3 Поскольку тональный диапазон изображения ограничен такой небольшой частью общего тонального диапазона, он потребует значительного растяжения. 8-битное изображение, которое в любом случае состоит только из 256 тонов, будет, по всей вероятности, постеризовано, потому что 80 тонов, представленных в данный момент в изображении, будут растянуты на 256 тонов. 16-битное изображение, которое имеет возможные 65 536 тоновых уровней, будет иметь более чем достаточно данных для распространения прямо по тональному диапазону, даже если только 30%, если тона представлены.
8-битное изображение, которое в любом случае состоит только из 256 тонов, будет, по всей вероятности, постеризовано, потому что 80 тонов, представленных в данный момент в изображении, будут растянуты на 256 тонов. 16-битное изображение, которое имеет возможные 65 536 тоновых уровней, будет иметь более чем достаточно данных для распространения прямо по тональному диапазону, даже если только 30%, если тона представлены.
Изображение выше имеет очень ровный диапазон тонов (сделано специально для иллюстрации). Статистика гистограммы показывает, что уровни только от 0 до 80, что составляет менее одной трети полного диапазона 256 (указано).Вместо этого 8 уровней. Это 20 480, что более чем достаточно для последних 256 необходимых тонов. На этом этапе, до того как изображение будет исправлено, гистограмма будет выглядеть одинаково как для 8-, так и для 16-битных изображений. Итак, займемся исправлением.
Рис. 4 Изображение исправлено с помощью инструмента «Уровни» в Photoshop.
Рис. 5 Гистограмма 8-битного изображения (слева) показывает промежутки, где 80 тональных уровней были распределены по 256 тональным уровням. Гистограмма для 16-битного изображения (справа) не показывает пропусков в тональном диапазоне, потому что 20 480 тональных уровней были распределены по 256 тональным уровням.
После того, как сканирование было исправлено путем выделения диапазона в инструменте «Уровни» в Photoshop, разница между 8- и 16-битными версиями теперь проявляется в гистограммах. 8-битная гистограмма сломана. У него было только 80 уровней для начала, а это значит, что нужно было добавить промежутки между уровнями, чтобы покрыть 256 тональное пространство. Но результат все равно 80 уровней. С другой стороны, 16-битное изображение имело 20 480 уровней вместо 80, поэтому не нужно было добавлять промежутки для заполнения 256-ти тонального пространства.Когда 16-битное изображение преобразуется в 8-битное после исправления, в результате получается 256 полных тонов.
Когда уровни изображения разнесены слишком далеко, существует реальный риск постеризации при работе с 8-битным изображением. Однако для большинства производственных работ вы можете не заметить реального улучшения качества изображения, поэтому нужно поэкспериментировать, чтобы увидеть, что лучше всего соответствует вашим стандартам качества и рабочему процессу. Однако именно по этой причине сканирование архивного качества всегда выполняется с разрешением 16 бит.
Вверх по основам цифровой обработки изображений
Вернуться к тональному диапазону
В градациях серого v «Серый RGB»
8.2 16-РАЗР. ОБОРУДОВАНИЯ ПРОТИВ 32-РАЗРЯДНОГО ОБЕСПЕЧЕНИЯ
Компьютера в стеке: 8,2 16-РАЗР.Stack Computers : новая волна © Copyright 1989, г. Филип Купман, Все права защищены.
Глава 8. Приложения
8,2 16-БИТНОЕ ОБОРУДОВАНИЕ ПРОТИВ 32-БИТНОГО ОБЕСПЕЧЕНИЯ
Фундаментальное решение о том, какой процессор стека выбрать для
конкретным приложением является размер элементов данных процессора: 16 бит или
32 бита. Выбор между 16- и 32-битными процессорами определяется
факторы стоимости, размера и производительности.
Выбор между 16- и 32-битными процессорами определяется
факторы стоимости, размера и производительности.
8.2.1 16-битное оборудование часто лучше
16-разрядные стековые процессоры в целом имеют меньшую стоимость, чем 32-разрядные процессоры. Их внутренние пути передачи данных уже, поэтому они используют меньше транзисторов и стоят меньше производить. Им нужны только 16-битные пути к внешней памяти, поэтому они имеют вдвое меньше контактов шины памяти, чем 32-битные процессоры.Системные затраты составляют также ниже, поскольку для минимальной конфигурации 16-разрядного процессора требуется только вдвое меньше микросхем памяти по сравнению с 32-битным процессором для одного банка объем памяти.
16-битных чипов также имеют разумный объем кремниевой области, доступной для
специальные функции, такие как аппаратные умножители, встроенная память программ и
периферийные интерфейсы. Тенденция - это полузаказные 16-битные стековые процессоры. такие как RTX 2000, чтобы быть законченными системами на кристалле, включая ввод / вывод
периферийные устройства и программная память для встроенных приложений.
такие как RTX 2000, чтобы быть законченными системами на кристалле, включая ввод / вывод
периферийные устройства и программная память для встроенных приложений.
16-битных процессоров всегда следует оценивать для приложения, затем отклоняется в пользу 32-битных процессоров только в том случае, если есть явная выгода для менять.
8.2.2 Иногда требуется 32-битное оборудование
Большинство традиционных приложений управления в реальном времени хорошо обслуживаются 16-битными процессоры. Они обеспечивают как минимум высокую скорость обработки в небольшой системе. Стоимость. Конечно, одна из причин того, что традиционные приложения хорошо обслуживаются 16-разрядными процессорами, так что способные 32-разрядные процессоры не использовались широко доступны очень давно.По мере появления более мощных 32-битных процессоров в более широкое использование, будут открыты новые области применения, чтобы хорошее использование.
32-битные процессоры стека следует использовать вместо 16-битных процессоров только в
случаи, когда приложение требует высокой эффективности на одном или нескольких
следующее: 32-битные целочисленные вычисления, доступ к большим объемам памяти или
арифметика с плавающей запятой.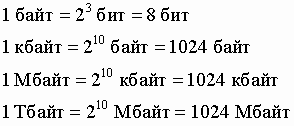
32-битные целочисленные вычисления, очевидно, хорошо подходят для 32-битных процессор.Случаи, когда требуются 32-битные целые числа, включают графику и манипулирование большими структурами данных. В то время как 16-битный процессор может моделировать 32-битная арифметика с использованием операндов двойной точности, 32-битные процессоры намного более эффективным.
В то время как 16-разрядные процессоры могут использовать регистры сегментов для доступа к более чем 64 КБ
элементы памяти, этот метод становится неудобным и медленным, если его нужно использовать
часто. Программа, которая должна постоянно изменять регистр сегмента на
доступ к структурам данных (особенно к отдельным структурам данных, размер которых превышает
64 КБ) может тратить много времени на вычисление значений сегментов.Еще хуже, поскольку адреса, которыми нужно манипулировать при вычислении данных
места записи, ширина которых превышает 16 бит, вычисление адресов
также медленнее из-за всей математики с двойной точностью. 32-битный
процессор может предложить линейное 32-битное адресное пространство с сопутствующим быстрым
вычисление адреса на 32-битном пути данных.
32-битный
процессор может предложить линейное 32-битное адресное пространство с сопутствующим быстрым
вычисление адреса на 32-битном пути данных.
Для вычислений с плавающей запятой также требуется 32-разрядный процессор.
эффективность. 16-битные процессоры тратят значительное количество времени на манипулирование
элементы стека при работе с числами с плавающей запятой, тогда как 32-битные
процессоры, естественно, подходят по размеру элементов данных.Есть
много случаев, когда масштабированная целочисленная арифметика более уместна, чем
числа с плавающей запятой для увеличения скорости на некоторых процессорах. В этих случаях
Может хватить и 16-битного процессора. Однако часто приходится использовать математику с плавающей запятой.
для снижения стоимости программирования проекта и поддержки кода, написанного на
языки высокого уровня. Кроме того, с появлением очень быстрой плавающей запятой
оборудование обработки, традиционное преимущество скорости целочисленных операций над
число операций с плавающей запятой уменьшается.
Недостатки 32-битных процессоров - стоимость и сложность системы. Чипы 32-битных процессоров обычно стоят дороже, потому что в них больше транзисторов. и контакты, чем 16-битные чипы. Они также требуют 32-битной программной памяти. и, как правило, печатная плата большего размера, чем у 16-разрядных процессоров. Там есть меньше места на кристалле для дополнительных функций, таких как аппаратные множители, но эти элементы будут появляться по мере того, как технология изготовления чипов становится более плотной.
СЛЕДУЮЩИЙ РАЗДЕЛ
Фил Купман - koopman @ cmu.edu
Инструмент преобразованияслов в биты
Armazenamento De DadosBit
Bit - это базовая единица оружия цифровой информации. É um acrônimo para dígito binário. Cada bit registra uma das duas respostas Possíveis a uma única pergunta: 0 ou 1, sim ou não, ligado ou desligado. Quando um dado является представителем como binário (base 2) números, cada dígito binário é um único bit. (Em 1946, palavra "bit" foivention pelo estatístico americano e cientista da computação John Tukey.)
(Em 1946, palavra "bit" foivention pelo estatístico americano e cientista da computação John Tukey.)
Byte
Byte - это единая информация, используемая для обработки вычислений. Refere-se a uma unidade de memória endereçável. Seu tamanho Pode Variar dependendo da máquina или linguagem de computação. На главном уровне контекста um byte é igual - 8 бит (или 1 октет). (Em 1956, unidade foi nomeado pelo engenheiro da IBM, Werner Buchholz.)
Caráter
Нет информации в цифровом формате, um carácter éigual a um byte or 8 bit.
Gibibyte
Гибибайт - это многократный байт, единое целое с цифровой информацией, префиксы норм базового мультипликатора гиби (символы Gi).O símbolo da unidade de gibibyte é GiB.
Gigabit
Gigabit - это единое целое для цифровой информации или передачи. Размер 1024 мегабит, 1048576 килобит или 1073741824 бит
Gigabyte
Gigabyte - это единое хранилище цифровых данных. Размер 1024 мегабайта, 1,048,576 килобайта, или 1073741824 байта
Kibibyte
O Kibibyte (символ KiB, сокращение двоичного байта в килобайтах) является одним из основных средств массовой информации электронной коммерции, созданной в 2000 году. ) como:
1 кибибайт = 1.024 байта
) como:
1 кибибайт = 1.024 байта
Килобит
Килобит - это единая единица хранения цифровой информации или передачи. Значение 1024 бит.
Килобайт
Килобайт - это единое целое с цифровыми данными. Размер 1024 байта.
Мебибайт
Мебибайт - это многопользовательский байт, унифицированная цифровая информация, префикс для умножения базовых значений множителя (символ Mi). Символы унидад де мебибайт é MiB.
Мегабит
Мегабит - это единое целое для цифровой информации или передачи.Значение 1024 или 1.048.576 бит.
Мегабайт
Мегабайт - это единое целое с цифровыми данными. Размер составляет 1024 или 1,048,576 байта.
Mword
Нет цифрового информационного наполнения, мм Mword имеет 4 байта или 32 бита.
Nibble
Nibble - Sucessão de quatro cifras binárias (биты) [1]. Полубайт = 4 бита, 2 полубайта = 1 байт = 8 бит, 4 полубайта = 1 слово = 2 байта = 16 бит
Петабит
Петабит - это единое средство передачи цифровой информации или передачи.