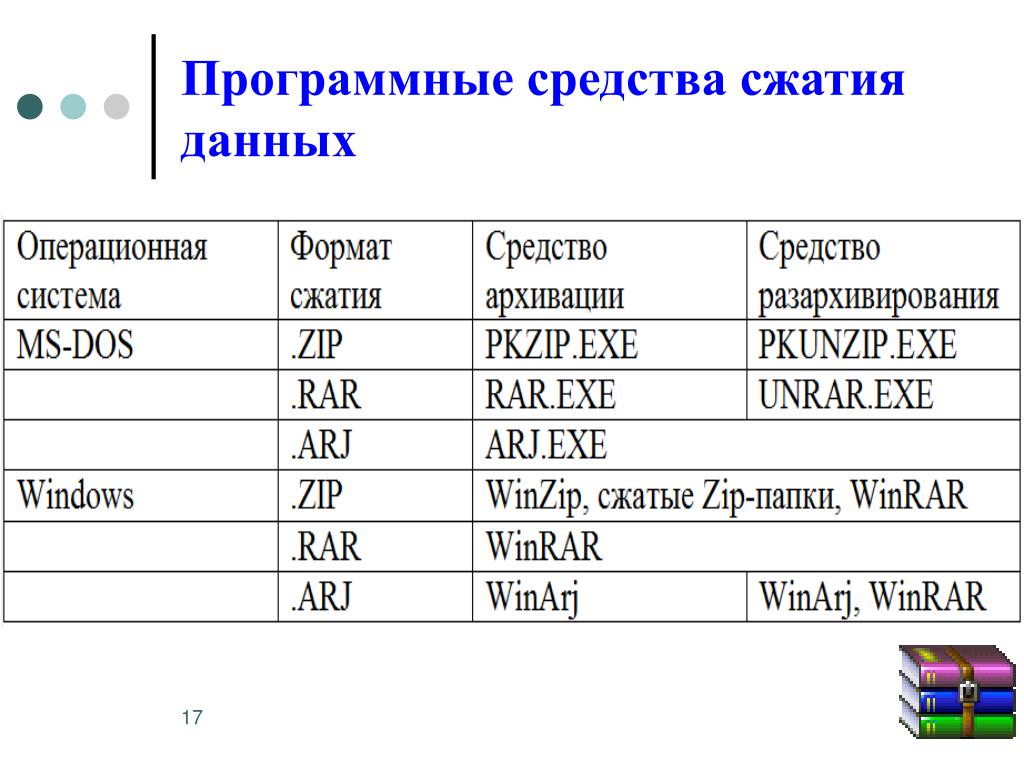
Форматы сжатия данных — Время электроники
В статье рассматриваются основные методы сжатия данных, приводится классификация наиболее известных алгоритмов, и на простых примерах обсуждаются механизмы работы методов CS&Q, RLE-кодирования, Хаффмана, LZW, дельта-кодирования, JPEG и MPEG. Статья представляет собой авторизованный перевод [1].
Передача данных и их хранение стоят определенных денег. Чем с большим количеством информации приходится иметь дело, тем дороже обходится ее хранение и передача. Зачастую данные хранятся в наиболее простом виде, например в коде ASCII (American Standard Code for Information Interchange — американский стандартный код для обмена информацией) текстового редактора, в исполняемом на компьютере двоичном коде, в отдельных файлах, полученных от систем сбора данных и т.д. Как правило, при использовании этих простых методов кодирования объем файлов данных примерно в два раза превышает действительно необходимый размер для представления информации. Ее сжатие с помощью алгоритмов и программ позволяет решить эту задачу.
Ее сжатие с помощью алгоритмов и программ позволяет решить эту задачу.
Методы сжатия данных
В таблице 1 показаны два разных способа распределения алгоритмов сжатия по категориям. К категории (а) относятся методы, определяемые как процедуры сжатия без потерь и с потерями. При использовании метода сжатия без потерь восстановленные данные идентичны исходным. Этот метод применяется для обработки многих типов данных, например для исполняемого кода, текстовых файлов, табличных данных и т.
| Табл. 1. Классификация методов сжатия: без потерь и с потерями | ||||||||||
|
Передаваемые по интернету изображения служат наглядным примером того, почему необходимо сжатие данных.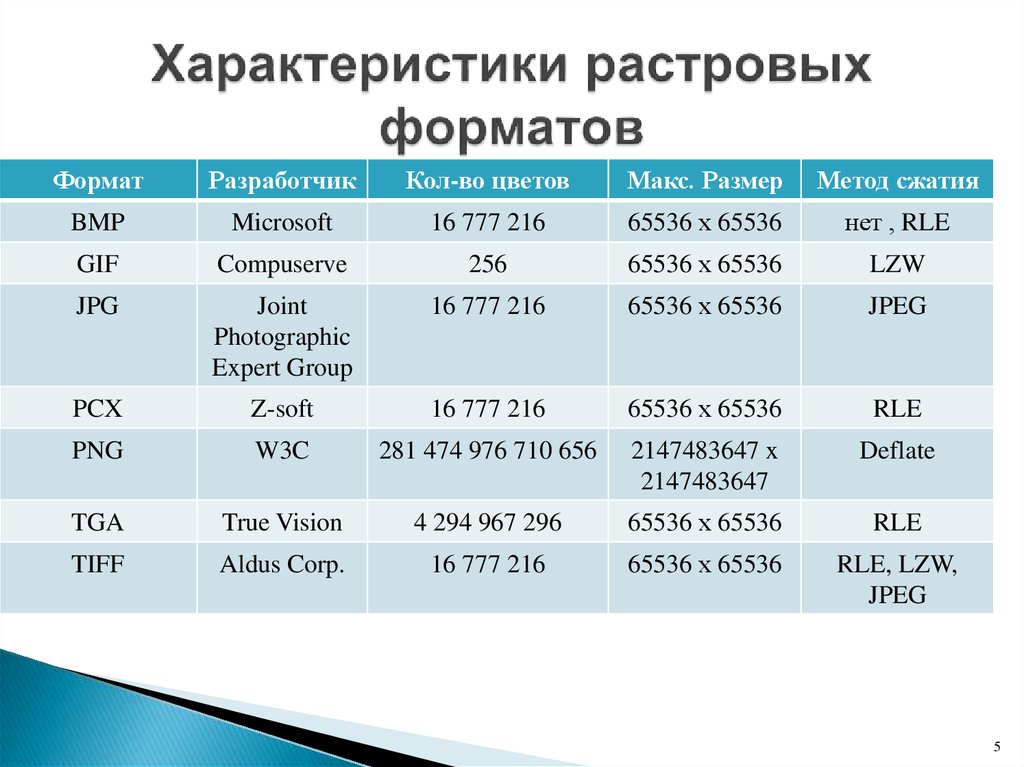 Предположим, что требуется загрузить из интернета цифровую цветную фотографию с помощью 33,6-Кбит/с модема. Если изображение не сжато (например, это файл TIFF-формата), его объем составит около 600 Кбайт. При сжатии фото без потерь (в файл GIF-формата) его размер уменьшится примерно до 300 Кбайт. Метод сжатия с потерями (
JPEG-формат) позволит уменьшить размер файла до 50 Кбайт. Время загрузки этих трех файлов составляет 142, 72 и 12 с, соответственно. Это большая разница. JPEG идеально подходит для работы с цифровыми фотографиями, тогда как GIF используется только для рисованных изображений.
Предположим, что требуется загрузить из интернета цифровую цветную фотографию с помощью 33,6-Кбит/с модема. Если изображение не сжато (например, это файл TIFF-формата), его объем составит около 600 Кбайт. При сжатии фото без потерь (в файл GIF-формата) его размер уменьшится примерно до 300 Кбайт. Метод сжатия с потерями (
JPEG-формат) позволит уменьшить размер файла до 50 Кбайт. Время загрузки этих трех файлов составляет 142, 72 и 12 с, соответственно. Это большая разница. JPEG идеально подходит для работы с цифровыми фотографиями, тогда как GIF используется только для рисованных изображений.
Второй способ классификации методов сжатия данных проиллюстрирован в таблице 2. Большинство программ сжатия работает с группами данных, которые берутся из исходного файла, сжимаются и записываются в выходной файл. Например, одним из таких методов является CS&Q (Coarser Sampling and Quantization — неточные выборка и дискретизация). Предположим, что сжимается цифровой сигнал, например звуковой сигнал, который оцифрован с разрядностью 12 бит. Можно прочесть две смежные выборки из исходного файла (24 бит), отбросить одну выборку полностью, отбросить наименее значащие 4 бита из другой выборки, затем записать оставшиеся 8 битов в выходной файл. При 24 входных битах и 8 выходных коэффициент сжатия алгоритма с потерями равен 3:1. Этот метод высокоэффективен при использовании
Можно прочесть две смежные выборки из исходного файла (24 бит), отбросить одну выборку полностью, отбросить наименее значащие 4 бита из другой выборки, затем записать оставшиеся 8 битов в выходной файл. При 24 входных битах и 8 выходных коэффициент сжатия алгоритма с потерями равен 3:1. Этот метод высокоэффективен при использовании
| Табл. 2. Классификация методов сжатия: фиксированный и переменный размер группы | |||||||||||||||||
|
|||||||||||||||||
В методе CS&Q из входящего файла читается фиксированное число битов, и меньшее фиксированное число записывается в выходной файл. Другие методы сжатия позволяют создавать переменное число битов для чтения или записи. Причина того, почему в таблицу не вошли форматы JPEG и MPEG, в том, что это составные алгоритмы, в которых совмещено множество других методов.
Другие методы сжатия позволяют создавать переменное число битов для чтения или записи. Причина того, почему в таблицу не вошли форматы JPEG и MPEG, в том, что это составные алгоритмы, в которых совмещено множество других методов.
RLE-кодирование
Файлы данных содержат одни и те же символы, повторяющиеся множество раз в одном ряду. Например, в текстовых файлах используются пробелы для разделения предложений, отступы, таблицы и т.д. Цифровые сигналы также содержат одинаковые величины, указывающие на то, что сигнал не претерпевает изменений. Например, изображение ночного неба может содержать длинные серии символов, представляющих темный фон, а цифровая музыка может иметь длинную серию нулей между песнями. RLE-кодирование (Run-length encoding — кодирование по длинам серий) представляет собой метод сжатия таких типов файлов.
 Если среднее значение длины серии больше двух, происходит сжатие. С другой стороны, множество одиночных нулей в данных может привести к тому, что кодированный файл окажется больше исходного.
Если среднее значение длины серии больше двух, происходит сжатие. С другой стороны, множество одиночных нулей в данных может привести к тому, что кодированный файл окажется больше исходного.
|
Рис. 1. Пример RLE-кодирования |
Входные данные можно рассматривать и как отдельные байты, или группы, например числа с плавающей запятой. RLE-кодирование можно использовать только в случае одного знака (как в случае в нулем в примере выше), нескольких знаков или всех знаков.
Кодирование Хаффмана
Этот метод был разработан Хаффманом в 1950-х гг. Метод основан на использовании относительной частоты встречаемости индивидуальных элементов. Часто встречающиеся элементы кодируются более короткой последовательностью битов. На рисунке 2 представлена гистограмма байтовых величин большого файла ASCII. Более 96% этого файла состоит из 31 символа: букв в нижнем регистре, пробела, запятой, точки и символа возврата каретки.
Алгоритм, назначающий каждому из этих стандартных символов пятибитный двоичный код по схеме 00000 = a, 00001 = b, 00010 = c и т.д., позволяет 96% этого файла уменьшить на 5/8 объема. Последняя комбинация 11111 будет указывать на то, что передаваемый символ не входит в группу из 31 стандартного символа. Следующие восемь битов в этом файле указывают, что представляет собой символ в соотоветствии со стандартом присвоения ASCII. Итак, 4% символов во входном файле требуют для представления 5 + 8 = 13 бит.
Принцип этого алгоритма заключается в присвоении часто употребляемым символам меньшего числа битов, а редко встречающимся символам — большего количества битов. В данном примере среднее число битов, требуемых из расчета на исходный символ, равно 0,96 . 5 + 0,04 . 13 = 5,32. Другими словами, суммарный коэффициент сжатия составляет 8 бит/5,32 бит, или 1,5 : 1.
|
Рис. 2. Гистограмма значений ASCII фрагмента текста из этой статьи |
На рисунке 3 представлена упрощенная схема кодирования Хаффмана. В таблице кодирования указана вероятность употребления символов с A по G, имеющихся в исходной последовательности данных, и их соответствия. Коды переменной длины сортируются в стандартные восьмибитовые группы. При распаковке данных все группы выстраиваются в последовательность нулей и единиц, что позволяет разделять поток данных без помощи маркеров. Обрабатывая поток данных, программа распаковки формирует достоверный код, а затем переходит к следующему символу. Такой способ формирования кода обеспечивает однозначное чтение данных.
В таблице кодирования указана вероятность употребления символов с A по G, имеющихся в исходной последовательности данных, и их соответствия. Коды переменной длины сортируются в стандартные восьмибитовые группы. При распаковке данных все группы выстраиваются в последовательность нулей и единиц, что позволяет разделять поток данных без помощи маркеров. Обрабатывая поток данных, программа распаковки формирует достоверный код, а затем переходит к следующему символу. Такой способ формирования кода обеспечивает однозначное чтение данных.
|
|||||||||||||||||||||||||
|
Рис. |
 3. Пример кодирования Хаффмана
3. Пример кодирования ХаффманаДельта-кодирование
Термин «дельта-кодирование» обозначает несколько методов сохранения или передачи данных в форме разности между последующими выборками (или символами), а не сохранение самих выборок. На рисунке 4 приводится пример работы этого механизма. Первое значение в кодируемом файле является совпадает с исходным. Все последующие значения в кодируемом файле равны разности между соответствующим и предыдущим значениями входного файла.
|
Рис. 4. Пример дельта-кодирования |
Дельта-кодирование используется для сжатия данных, если значения исходного файла изменяются плавно, т.е. разность между следующими друг за другом величинами невелика. Это условие не выполняется для текста ASCII и исполняемого кода, но является общим случаем, когда информация поступает в виде сигнала. Например, на рисунке 5а показан фрагмент аудиосигнала, оцифрованного с разрядностью 8 бит, причем все выборки принимают значения в диапазоне –127–127. На рисунке 5б представлен кодированный вариант этого сигнала, основное отличие которого от исходного сигнала заключается в меньшей амплитуде. Другими словами, дельта-кодирование увеличивает вероятность того, что каждое значение выборки находится вблизи нуля, а вероятность того, что оно значительно больше этой величины, невелика. С неравномерным распределением вероятности работает метод Хаффмана. Если исходный сигнал не меняется или меняется линейно, в результате дельта-кодирования появятся серии выборок с одинаковыми значениями, с которыми работает RLE-алгоритм. Таким образом, в стандартном методе сжатия файлов используется дельта-кодирование с последующим применением метода Хаффмана или RLE-кодирования.
На рисунке 5б представлен кодированный вариант этого сигнала, основное отличие которого от исходного сигнала заключается в меньшей амплитуде. Другими словами, дельта-кодирование увеличивает вероятность того, что каждое значение выборки находится вблизи нуля, а вероятность того, что оно значительно больше этой величины, невелика. С неравномерным распределением вероятности работает метод Хаффмана. Если исходный сигнал не меняется или меняется линейно, в результате дельта-кодирования появятся серии выборок с одинаковыми значениями, с которыми работает RLE-алгоритм. Таким образом, в стандартном методе сжатия файлов используется дельта-кодирование с последующим применением метода Хаффмана или RLE-кодирования.
|
а) |
б) |
|
Рис. 5. Пример дельта-кодирования |
Механизм дельта-кодирования можно расширить до более полного метода под названием кодирование с линейным предсказанием (Linear Predictive Coding, LPC).
Чтобы понять суть этого метода, представим, что уже были закодированы первые 99 выборок из входного сигнала и необходимо произвести выборку под номером 100. Мы задаемся вопросом о том, каково наиболее вероятное ее значение? В дельта-кодировании ответом на данный вопрос является предположение, что это значение предыдущей, 99-й выборки. Это ожидаемое значение используется как опорная величина при кодировании выборки 100. Таким образом, разность между значением выборки и ожиданием помещается в кодируемый файл. Метод LPC устанавливает наиболее вероятную величину на основе нескольких последних выборок. В используемых при этом алгоритмах применяется z-преобразование и другие математические методы.
Алгоритм LZW
LZW-сжатие — наиболее универсальный метод сжатия данных, получивший распространение благодаря своей простоте и гибкости. Этот алгоритм назван по имени его создателей (Lempel-Ziv-Welch encoding — сжатие данных методом Лемпела-Зива-Велча). Исходный метод сжатия Lempel-Ziv был впервые заявлен в 1977 г. , а усовершенствованный Велчем вариант — в 1984 г. Метод позволяет сжимать текст, исполняемый код и схожие файлы данных примерно вполовину. LZW также хорошо работает с избыточными данными, например табличными числами, компьютерным исходным текстом и принятыми сигналами. В этих случаях типичными значениями коэффициента сжатия являются 5:1. LZW-сжатие всегда используется для обработки файлов изображения в формате GIF и предлагается в качестве опции для форматов TIFF и PostScript.
, а усовершенствованный Велчем вариант — в 1984 г. Метод позволяет сжимать текст, исполняемый код и схожие файлы данных примерно вполовину. LZW также хорошо работает с избыточными данными, например табличными числами, компьютерным исходным текстом и принятыми сигналами. В этих случаях типичными значениями коэффициента сжатия являются 5:1. LZW-сжатие всегда используется для обработки файлов изображения в формате GIF и предлагается в качестве опции для форматов TIFF и PostScript.
Алгоритм LZW использует кодовую таблицу, пример которой представлен на рисунке 6. Как правило, в таблице указываются 4096 элементов. При этом кодированные LZW-данные полностью состоят из 12-битных кодов, каждый из которых соответствует одному табличному элементу. Распаковка выполняется путем извлечения каждого кода из сжатого файла и его преобразования с помощью таблицы. Табличные коды 0—255 всегда назначаются единичным байтам входного файла (стандартному набору символов). Например, если используются только эти первые 256 кодов, каждый байт исходного файла преобразуется в 12 бит сжатого LZW-файла, который на 50% больше исходного. При распаковке этот 12-битный код преобразуется с помощью кодовой таблицы в единичные байты.
При распаковке этот 12-битный код преобразуется с помощью кодовой таблицы в единичные байты.
|
Пример кодовой таблицы
|
|||||||||||||||||||||||
|
Рис. 6. Пример сжатия в соответствии с таблицей кодирования |
Метод LZW сжимает данные с помощью кодов 256—4095, представляя последовательности байтов. Например, код 523 может представлять последовательность из трех байтов: 231 124 234. Всякий раз, когда алгоритм сжатия обнаруживает последовательность во входном файле, в кодируемый файл ставится код 523. При распаковке код 523 преобразуется с помощью таблицы в исходную последовательность из трех байтов. Чем длиннее последовательность, назначаемая единичному коду и чем чаще она повторяется, тем больше коэффициент сжатия.
Например, код 523 может представлять последовательность из трех байтов: 231 124 234. Всякий раз, когда алгоритм сжатия обнаруживает последовательность во входном файле, в кодируемый файл ставится код 523. При распаковке код 523 преобразуется с помощью таблицы в исходную последовательность из трех байтов. Чем длиннее последовательность, назначаемая единичному коду и чем чаще она повторяется, тем больше коэффициент сжатия.
Существуют два основных препятствия при использовании этого метода сжатия: 1) как определить, какие последовательности должны указываться в кодовой таблице и 2) как обеспечить программу распаковки той же таблицей, которую использует программа сжатия. Алгоритм LZW позволяет решить эти задачи.
Когда программа LZW начинает кодировать файл, таблица содержит лишь первые 256 элементов — остальная ее часть пуста. Это значит, что первые коды, поступающие в сжимаемый файл, представляют собой единичные байты исходного файла, преобразуемые в 12-бит группы. По мере продолжения кодирования LZW-алгоритм определяет повторяющиеся последовательности данных и добавляет их в кодовую таблицу.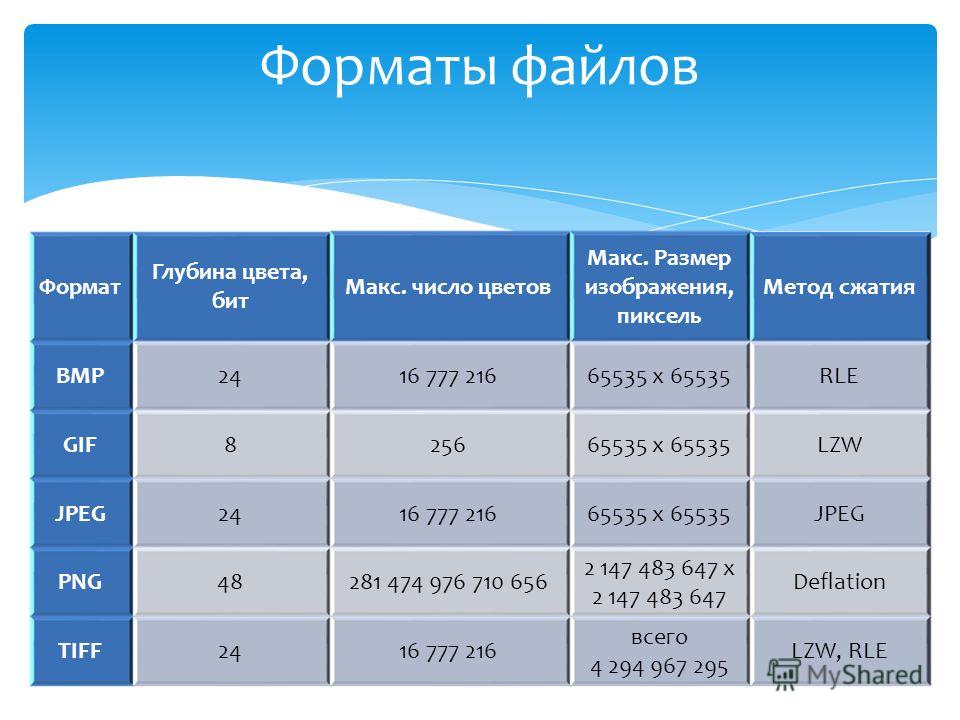 Сжатие начинается, когда последовательность обнаруживается вторично. Суть метода в том, что последовательность из входящего файла не добавляется в кодовую таблицу, если она уже была помещена в сжатый файл как отдельный символ (коды 0—255). Это важное условие, поскольку оно позволяет программе распаковки восстановить кодовую таблицу непосредственно из сжатых данных, не нуждаясь в ее отдельной передаче.
Сжатие начинается, когда последовательность обнаруживается вторично. Суть метода в том, что последовательность из входящего файла не добавляется в кодовую таблицу, если она уже была помещена в сжатый файл как отдельный символ (коды 0—255). Это важное условие, поскольку оно позволяет программе распаковки восстановить кодовую таблицу непосредственно из сжатых данных, не нуждаясь в ее отдельной передаче.
JPEG
Из множества алгоритмов сжатия с потерями кодирование с преобразованием оказалось наиболее востребованным. Наилучший пример такого метода — популярный стандарт JPEG (Joint Photographers Experts Group — Объединенная группа экспертов по машинной обработке фотографических изображений). Рассмотрим на примере JPEG работу алгоритма сжатия с потерями.
Мы уже обсудили простейший метод сжатия с потерями CS&Q, в котором уменьшается количество битов на выборку или полностью отбрасываются некоторые выборки. Оба этих приема позволяют достичь желаемого результата — файл становится меньше за счет ухудшения качества сигнала. Понятно, что эти простые методы работают не самым лучшим образом.
Понятно, что эти простые методы работают не самым лучшим образом.
Сжатие с преобразованием основано на простом условии: в трансформированном сигнале (например, с помощью преобразования Фурье) полученные значения данных не несут прежней информационной нагрузки. В частности, низкочастотные компоненты сигнала начинают играть более важную роль, чем высокочастотные компоненты. Удаление 50% битов из высокочастотных компонентов может привести, например, к удалению лишь 5% закодированной информации.
Из рисунка 7 видно, что JPEG-сжатие начинается путем разбиения изображения на группы размером 8×8 пикселов. Полный алгоритм JPEG работате с широким рядом битов на пиксел, включая информацию о цвете. В этом примере каждый пиксел является единичным байтом, градацией серого в диапазоне 0—255. Эти группы 8×8 пикселов обрабатываются при сжатии независимо друг от друга. Это значит, что каждая группа сначала представляется 64 байтами. Вслед за преобразованием и удалением данных каждая группа представляется, например, 2—20 байтами.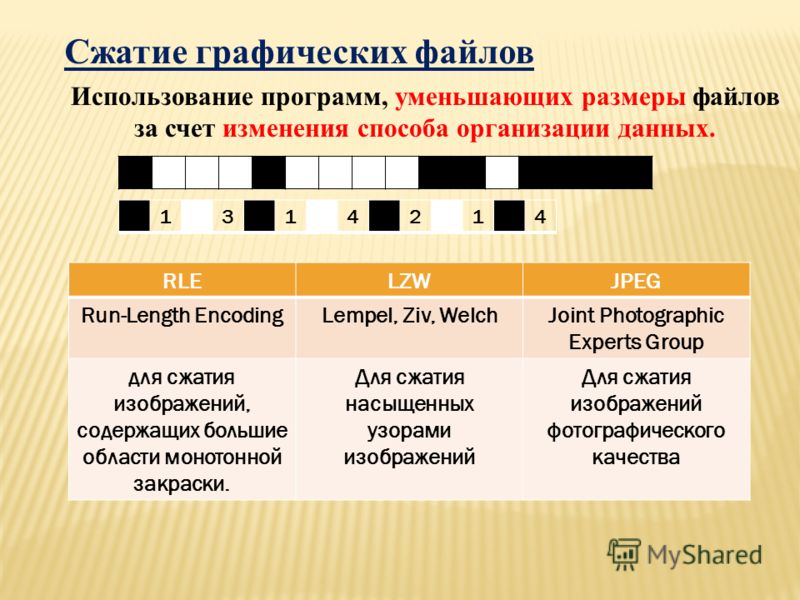 При распаковке сжатого файла требуется такое же количество байтов для аппроксимации исходной группы 8×8. Эти аппроксимированные группы затем объединяются, воссоздавая несжатое изображение. Почему используются группы размерами 8×8, а не 16×16? Такое группирование было основано исходя из максимального возможного размера, с которым работали микросхемы на момент разработки стандарта.
При распаковке сжатого файла требуется такое же количество байтов для аппроксимации исходной группы 8×8. Эти аппроксимированные группы затем объединяются, воссоздавая несжатое изображение. Почему используются группы размерами 8×8, а не 16×16? Такое группирование было основано исходя из максимального возможного размера, с которым работали микросхемы на момент разработки стандарта.
|
Рис. 7. Пример применения метода сжатия JPEG. Три группы 8?8, показанные в увеличенном виде, представляют значения отдельных пикселов |
Для реализации методов сжатия было исследовано множество различных преобразований. Например, преобразование Karhunen-Loeve обеспечивает наиболее высокий коэффициент сжатия, но оно трудно осуществляется. Метод преобразования Фурье реализуется гораздо проще, но он не обеспечивает достаточно хорошего сжатия. В конце концов, выбор был сделан в пользу разновидности метода Фурье — дискретного косинусного преобразования (Discrete Cosine Transform — DCT).
На примере работы алгоритма JPEG видно, как несколько схем сжатия объединяются, обеспечивая большую эффективность. Вся процедура сжатия JPEG состоит из следующих этапов:
– изображение разбивается на группы 8×8;
– каждая группа преобразуется с помощью преобразования DCT;
– каждый спектральный элемент 8×8 сжимается путем сокращения числа битов и удаления некоторых компонентов с помощью таблицы квантования;
– видоизмененный спектр преобразуется из массива 8×8 в линейную последовательность, все высокочастотные компоненты которой помещаются в ее конец;
– серии нулей сжимаются с помощью метода RLE;
– последовательность кодируется либо методом Хаффмана, либо арифметическим методом для получения сжатого файла.
MPEG
MPEG (Moving Pictures Experts Group — Экспертная группа по кинематографии) — стандарт сжатия цифровых видеоданных. Этот алгоритм обеспечивает также сжатие звуковой дорожки к видеофильму. MPEG представляет собой еще более сложный, чем JPEG, стандарт с огромным потенциалом. Можно сказать, это ключевая технология XXI века.
Можно сказать, это ключевая технология XXI века.
У MPEG имеется несколько очень важных особенностей. Так например, он позволяет воспроизводить видеофильм в прямом и обратном направлениях, в режиме нормальной и повышенной скорости. К кодированной информации имеется прямой доступ, т.е. каждый отдельный кадр последовательности отображается как неподвижное изображение. Таким образом, фильм редактируется — можно кодировать его короткие фрагменты, не используя всю последовательность в качестве опорной. MPEG также устойчив к ошибкам, что позволяет избегать цифровых ошибок, приводящих к нежелательному прерыванию воспроизведения.
Используемый в этом стандарте метод можно классифицировать по двум типам сжатия: внутрикадровое и межкадровое. При сжатии по первому типу отдельные кадры, составляющие видеопоследовательность, кодируются так, как если бы они были неподвижными изображениями. Такое сжатие выполняется с помощью JPEG-стандарта с несколькими вариациями. В терминологии MPEG кадр, закодированный таким образом, называется внутрикодированным, или I-picture.
В терминологии MPEG кадр, закодированный таким образом, называется внутрикодированным, или I-picture.
Наибольшая часть пикселов в видеопоследовательности изменяется незначительно от кадра к кадру. Если камера не движется, наибольшая часть изображения состоит из фона, который не меняется на протяжении некоторого количества кадров. MPEG использует это обстоятельство, сжимая избыточную информацию между кадрами с помощью дельта-кодирования. После сжатия одного из кадров в виде I-picture последующие кадры кодируются как изображения с предсказанием, или P-pictures, т.е. кодируются только изменившиеся пикселы, т.к. кадры I-picture включены в P-picture.
Эти две схемы сжатия составляют основу MPEG, тогда как практическая реализация данного метода намного сложнее описанной. Например, кадры P-picture могут использовать изображение I-picture как опорное, которое претерпело изменение при перемещении объектов в последовательности изображений. Существуют также двунаправленные предиктивно-кодированные изображения, или B-pictures. Эти видеокадры формируются способом предсказания «вперед» и «назад» на основе I-picture. При этом обрабатываются участки изображения, которые постепенно меняются на протяжении множества кадров. Отдельные кадры также хранятся без соблюдения последовательности в сжатых данных, чтобы облегчить упорядочение изображений I-, P- и B-pictures. Наличие цвета и звука еще больше усложняет реализацию этого алгоритма.
Эти видеокадры формируются способом предсказания «вперед» и «назад» на основе I-picture. При этом обрабатываются участки изображения, которые постепенно меняются на протяжении множества кадров. Отдельные кадры также хранятся без соблюдения последовательности в сжатых данных, чтобы облегчить упорядочение изображений I-, P- и B-pictures. Наличие цвета и звука еще больше усложняет реализацию этого алгоритма.
Наибольшее искажение при использовании формата MPEG наблюдается при быстром изменении больших частей изображения. Для поддержания воспроизведения с быстро меняющимися сценами на должном уровне требуется значительный объем информации. Если скорость передачи данных ограничена, зритель в этом случае видит ступенчатообразные искажения при смене сцен. Эти искажения сводятся к минимуму в сетях с одновременной передачей данных по нескольким видеоканалам, например в сети кабельного телевидения. Внезапное увеличение объема данных, требуемое для поддержки быстро меняющейся сцены в видеоканале, компенсируется относительно статическими изображениями, передаваемыми по другим каналам.
Литература
1. Steven W. Smith, Data compression tutorial Part 1, Part 2, and Part 3.
Форматы сжатия: самые популярные и какой из них стоит использовать
Когда мы говорим о формате ZIP, все мы сразу понимаем, о чем говорим. Формат впервые появился в 1989 году, и мы все знаем его отчасти потому, что это система сжатия по умолчанию в Windows, и многие из нас начали делать свои первые шаги в вычислениях с системой Microsoft. Позже появилось больше форматы сжатия, а в этой статье мы поговорим о самых популярных, среди которых у нас будет RAR или 7z.
Когда мы хотим сжать файлы, а эта статья посвящена именно этому типу сжатия, а не другим, таким как сжатие видео или аудио, вполне вероятно, что нам понадобится подать их. Следовательно, по крайней мере один из форматов сжатия, включенных в эту статью, будет просто делать это, то есть мы включили тот, который не сжимает, но позже вы поймете, почему.
Индекс
- 1 Самые популярные форматы сжатия
- 1.1 ZIP, быстрый и легкий
- 1.2 ZIPX, эволюция ZIP
- 1.3 TAR в файл …
- 1.4 … И ГЗ сжать
- 1.5 7z, открытый исходный код и мощный
- 1.6 RAR, лучший вариант, если вам не нужны лицензии
- 1.7 ACE, старая слава
- 2 Какой из этих форматов сжатия лучший?
 schema.org/SiteNavigationElement»>
schema.org/SiteNavigationElement»>Самые популярные форматы сжатия
ZIP, быстрый и легкий
Как мы уже упоминали, ЗИП — очень известный формат сжатия, отчасти потому, что он «Единственная на всю жизнь» в системах Microsoft. Будучи одним из первых, со временем его обогнали другие форматы, такие как 7z или RAR, но у него все еще есть свои сильные стороны:
- Сжатие в ZIP очень быстрое и не требует много ресурсов, по крайней мере, если мы сравним его со сжатием в 7z или RAR. Он основан на сжатии Deflate Lossless, что делает его идеальным для архивирования больших объемов комбинированных данных, например резервных копий.

- ZIP везде. Формат ZIP доступен практически в любой операционной системе, такой как Linux, или даже в гораздо более закрытых системах, таких как iOS от Apple.
- В последних версиях введено шифрование AES.
Причины выбора ZIP в качестве формата сжатия: скорость и он отлично работает в любой операционной системе. Другие форматы, хотя и доступны, могут вызывать проблемы в некоторых операционных системах, и это то, что случилось со мной при сжатии файлов в 7z в разных местах, начиная с Ark.
ZIPX, эволюция ZIP
Если мы говорили о ZIP, мы должны поговорить о эволюция того же самого. Это ZIPX, и среди его возможностей мы можем сжимать больше, чем ZIP, что сравнимо с форматом RAR. Проблема в том, что при использовании ZIPX мы теряем сильные стороны ZIP: компьютер потребляет больше ресурсов, а сжатие / распаковка происходит медленнее.
Я бы порекомендовал использовать ZIPX только в том случае, если вы не хотите использовать RAR, то есть по экономическим и лицензионным вопросам.
TAR в файл …
Как мы объясняли ранее, мы собирались упомянуть формат сжатия, который не сжимается. Это TAR, и мы упоминаем его, потому что он часто используется в Linux. Sобеспечивает только архивирование (объединить входные данные и метаданные в один выходной файл), делегируя такие функции, как сжатие, шифрование, проверка четности / целостности, внешнему программному обеспечению, которое работает в конвейере с выходными данными команды TAR.
… И ГЗ сжать
Многие из файлов, которые мы загружаем для Linux, имеют формат tar.gz. Расширение GZ обозначает формат сжатия одного файла, созданный для проекта GZip (GNU Zip или «бесплатный Zip»), начатого в 1992 году Жан-Лу Гейли и Марком Адлером, чтобы предоставить бесплатную замену решениям сжатия. коммерческие данные. Сжатие основано на Алгоритм DEFLATE (также используется как алгоритм по умолчанию в формате PKZip / WinZip .ZIP), комбинация кодирования Lempel-Ziv (LZ77) и кодирования Хаффмана.
Его можно использовать вместо ZIP и, как и в случае с ZIPX, для решения проблемы лицензирования, так как это совершенно бесплатно.
7z, открытый исходный код и мощный
7z — это современный формат сжатия и с открытым исходным кодом. Он предлагает шифрование AES и высокий уровень сжатия, один из лучших, в большинстве случаев выше, чем RAR или ZIPX. Он был представлен в Windows как 7-Zip и перенесен командой p7zip на платформы Unix. Поддерживаемые алгоритмы сжатия (LZMA / LZMA2, PPMd, BZip2) могут выиграть от параллельных вычислений на современных многоядерных процессорах.
Основная причина использования 7z — это его высокий уровень сжатия, но это не стоит того, если мы собираемся сжимать большие файлы во время работы, потому что мы будем тратить много времени / ресурсов нашего оборудования. С другой стороны, как я уже упоминал, я не смог выполнить сжатие с помощью Ark, поэтому лично у меня есть эта шип в бок, и я не могу ему полностью доверять. Другими словами, 7z может представляют больше проблем, чем другие форматы, такие как ZIP.
Другими словами, 7z может представляют больше проблем, чем другие форматы, такие как ZIP.
RAR, лучший вариант, если вам не нужны лицензии
Формат RAR является одним из самых известных, как и ZIP, отчасти потому, что он также широко используется в системах Microsoft. Это проприетарный формат, представленный WinRAR в Windows и его распаковывающая часть была перенесена на Linux (Унрар). Среди его функций мы имеем:
- Сжимает больше, чем ZIP.
- Предлагает надежное шифрование.
- Возможность восстановления в случае ошибок.
Как и у 7z и ZIPX, одной из его сильных сторон является степень сжатия, но ценой времени и потребления ресурсов. Я всегда использовал формат RAR в Windows как для сжатия, так и для разделения файлов и защиты паролем. Конечно, за это нужно платить или делать то, что знаешь.
ACE, старая слава
Как и RAR, ACE — это проприетарный формат, представленный в Windows WinACE, но в данном случае это была та же компания, которая перенесла его на Linux, а точнее — его возможности извлечения (UNACE). В последние годы он потерял популярность, но предлагает лучший уровень сжатия, чем у ZIP, без достижения RAR, ZIPX или 7z.
В последние годы он потерял популярность, но предлагает лучший уровень сжатия, чем у ZIP, без достижения RAR, ZIPX или 7z.
Поскольку нет бесплатной или бесплатной версии для создания файлов ACE, Я бы не рекомендовал его использовать если у нас нет доступа к недорогой лицензии. Если нужно выбирать, лучше RAR.
Какой из этих форматов сжатия лучший?
Как мы объясняли, это будет зависеть от многих факторов, среди которых у нас есть совместимость, уровень сжатия и лицензии. Для Linux я бы порекомендовал формат 7z, но не раньше, чем провести тесты, чтобы убедиться, что мы не обнаружили никаких ошибок, подобных той, которую я обнаружил в Kubuntu с помощью Ark.
В Windows или macOS это будет зависеть от того, что мы хотим «найти жизнь» и тема лицензирования. Формат 7z также может быть хорошим вариантом как с точки зрения уровня сжатия и безопасности, так и с точки зрения открытого исходного кода.
Что касается распаковки, мы можем распаковать форматы ZIP «из коробки» во многих операционных системах, в то время как другие, такие как RAR или ACE, могут распаковывать их бесплатно с помощью UNRAR или UNACE.
Как вы думаете, стоит ли добавить в этот список форматов сжатия еще какие-то параметры?
Теме статьи:
Как распаковать файлы в Ubuntu
Узнайте о форматах файлов сжатия и API, которые могут открывать и создавать архивные файлы
Узнайте, что такое файл CIT и API, которые могут создавать и открывать файлы CIT. Подробнее »
Узнайте, что такое файл APZ и API, которые могут создавать и открывать файлы APZ. Подробнее »
Узнайте о формате файлов ZST и API-интерфейсах, которые могут создавать и открывать файлы ZST. Подробнее »
Узнайте о формате файлов ECS и API-интерфейсах, которые могут создавать и открывать файлы ECS. Подробнее »
Узнайте о формате файлов B1 и API-интерфейсах, которые могут создавать и открывать файлы B1. Подробнее »
Узнайте о формате файлов WHL и API-интерфейсах, которые могут создавать и открывать файлы WHL. Подробнее »
Узнайте о формате файлов BNDL и API-интерфейсах, которые могут создавать и открывать файлы BNDL. Подробнее »
Подробнее »
Узнайте о формате файлов S00 и API, которые могут создавать и открывать файлы S00. Подробнее »
Узнайте, что такое файл GZIP и API, которые могут создавать и открывать файлы GZIP. Подробнее »
Узнайте о формате файлов SY_ и API, которые могут создавать и открывать файлы SY_. Подробнее »
Узнайте о формате файлов PET и API-интерфейсах, которые могут создавать и открывать файлы PET. Подробнее »
Узнайте о формате файлов PF и API-интерфейсах, которые могут создавать и открывать файлы PF. Подробнее »
Узнайте о формате файлов PUP и API-интерфейсах, которые могут создавать и открывать файлы PUP. Подробнее »
Узнайте о формате файлов NPK и API-интерфейсах, которые могут создавать и открывать файлы NPK. Подробнее »
Узнайте, что такое файл FZPZ и API, которые могут создавать и открывать файлы FZPZ. Подробнее »
Узнайте о формате файлов MINT и API, которые могут создавать и открывать файлы MINT. Подробнее »
Узнайте о формате файлов XPI и API, которые могут создавать и открывать файлы XPI. Подробнее »
Подробнее »
Узнайте о формате файла TPSR и API-интерфейсах, которые могут создавать и открывать файлы TPSR. Подробнее »
Что такое ZIPX-файл и API, которые могут создавать и открывать ZIPX-файлы. Подробнее »
Узнайте, что такое файл P7Z и API, которые могут создавать и открывать файлы P7Z. Подробнее »
Узнайте, что такое файл APPAGESK и API, которые могут создавать и открывать файлы PAGES. Подробнее »
Узнайте, что такое файл TZ и API, которые могут создавать и открывать файлы TZ. Подробнее »
Узнайте о формате файлов TGZ и API-интерфейсах, которые могут создавать и открывать файлы TGZ. Подробнее »
Узнайте о формате файла VPK и API-интерфейсах, которые могут создавать и открывать файлы VPK. Подробнее »
Узнайте о формате файлов WUX и API-интерфейсах, которые могут создавать и открывать файлы WUX. Подробнее »
Узнайте о формате файлов XZ и API-интерфейсах, которые могут создавать и открывать файлы XZ. Подробнее »
Узнайте о формате файлов Z и API-интерфейсах, которые могут создавать и открывать файлы Z. Подробнее »
Подробнее »
Узнайте о формате файла LZH и API-интерфейсах, которые могут создавать и открывать файлы LZH. Подробнее »
Узнайте о формате файлов LZO и API-интерфейсах, которые могут создавать и открывать файлы LZO. Подробнее »
Узнайте о формате файла MBW и API-интерфейсах, которые могут создавать и открывать файлы MBW. Подробнее »
Узнайте о формате файлов MPQ и API-интерфейсах, которые могут создавать и открывать файлы MPQ. Подробнее »
Узнайте о формате файлов ALZ и API-интерфейсах, которые могут создавать и открывать файлы ALZ. Подробнее »
Узнайте о формате файлов BKF и API-интерфейсах, которые могут создавать и открывать файлы BKF. Подробнее »
Узнайте о формате файлов DMG и API, которые могут создавать и открывать файлы DMG. Подробнее »
Узнайте о формате файлов LQR и API-интерфейсах, которые могут создавать и открывать файлы LQR. Подробнее »
Узнайте о формате файлов LZX и API-интерфейсах, которые могут создавать и открывать файлы LZX. Подробнее »
Подробнее »
Узнайте о формате файлов PTK и API-интерфейсах, которые могут создавать и открывать файлы PTK. Подробнее »
Узнайте о формате файла SFG и API-интерфейсах, которые могут создавать и открывать файлы SFG. Подробнее »
Узнайте о формате файлов SIFZ и API-интерфейсах, которые могут создавать и открывать файлы SIFZ. Подробнее »
Узнайте о формате файлов SIT и API-интерфейсах, которые могут создавать и открывать файлы SIT. Подробнее »
Узнайте о формате файлов SITX и API-интерфейсах, которые могут создавать и открывать файлы SITX. Подробнее »
Узнайте о формате файлов ACE и API-интерфейсах, которые могут создавать и открывать файлы ACE. Подробнее »
Узнайте о формате файла PEA и API-интерфейсах, которые могут создавать и открывать файлы PEA. Подробнее »
Узнайте о формате файлов XAPK и API-интерфейсах, которые могут создавать и открывать файлы XAPK. Подробнее »
Узнайте о формате файла DAR и API-интерфейсах, которые могут создавать и открывать файлы DAR. Подробнее »
Подробнее »
Узнайте о формате файла DEB и API-интерфейсах, которые могут создавать и открывать файлы DEB. Подробнее »
Узнайте о формате файла DZ и API-интерфейсах, которые могут создавать и открывать файлы DZ. Подробнее »
Узнайте о формате файлов ICE и API, которые могут создавать и открывать файлы ICE. Подробнее »
Что такое файл ISO и API, которые могут создавать и открывать файлы ISO. Подробнее »
Узнайте о формате файлов KGB и API-интерфейсах, которые могут создавать и открывать файлы KGB. Подробнее »
Узнайте о формате файлов LBR и API, которые могут создавать и открывать файлы LBR. Подробнее »
Узнайте о формате файлов LZ и API-интерфейсах, которые могут создавать и открывать файлы LZ. Подробнее »
Узнайте о формате файлов LBR и API, которые могут создавать и открывать файлы LZ4. Подробнее »
Что такое файл LZMA и API, которые могут создавать и открывать файлы LZMA. Подробнее »
Узнайте о формате файла OAR и API-интерфейсах, которые могут создавать и открывать файлы OAR. Подробнее »
Подробнее »
Узнайте о формате файлов PKG и API-интерфейсах, которые могут создавать и открывать файлы PKG. Подробнее »
Узнайте о формате файлов RPM и API, которые могут создавать и открывать файлы RPM. Подробнее »
Узнайте о формате файлов RTE и API-интерфейсах, которые могут создавать и открывать файлы RTE. Подробнее »
Узнайте о формате файлов XAR и API-интерфейсах, которые могут создавать и открывать файлы XAR. Подробнее »
Узнайте о формате файла ARC и API-интерфейсах, которые могут создавать и открывать файлы ARC. Подробнее »
Узнайте о формате файлов ARJ и API-интерфейсах, которые могут создавать и открывать файлы ARJ. Подробнее »
Узнайте о формате файлов DAA и API-интерфейсах, которые могут создавать и открывать файлы DAA. Подробнее »
Узнайте о формате файлов ZIM и API-интерфейсах, которые могут создавать и открывать файлы ZIM. Подробнее »
Что такое ZIP-файл и API, которые могут создавать и открывать ZIP-файлы. Подробнее »
Подробнее »
Узнайте о формате файлов ZL и API-интерфейсах, которые могут создавать и открывать файлы ZL. Подробнее »
Что такое файл 7Z и API, которые могут создавать и открывать файлы 7Z. Подробнее »
Узнайте, что такое файл APK и API, которые могут создавать и открывать файлы APK. Подробнее »
Узнайте о формате файлов B6Z и API-интерфейсах, которые могут создавать и открывать файлы B6Z. Подробнее »
Узнайте, что такое файл BZ2 и API, которые могут создавать и открывать файлы BZ2. Подробнее »
Узнайте, что такое файл GZ и API, которые могут создавать и открывать файлы GZ. Подробнее »
Узнайте о формате файлов MPKG и API-интерфейсах, которые могут создавать и открывать файлы MPKG. Подробнее »
Что такое расширение файла RAR и API, которые могут создавать и открывать файлы RAR. Подробнее »
Узнайте, что такое файл TAR и API, которые могут создавать и открывать файлы TAR. Подробнее »
Узнайте о формате файлов TBZ и API-интерфейсах, которые могут создавать и открывать файлы TBZ. Подробнее »
Подробнее »
Узнайте о формате файлов TGS и API-интерфейсах, которые могут создавать и открывать файлы TGS. Подробнее »
Форматы сжатия: самые популярные и какой из них следует использовать
Когда мы говорим о формате ZIP, мы все сразу понимаем, о чем говорим. Этот формат впервые появился в 1989 году, и мы все знаем его отчасти потому, что это система сжатия по умолчанию в Windows, и многие из нас начали делать свои первые шаги в области вычислений с помощью системы Microsoft. Позже появилось еще форматы сжатия , и в этой статье мы поговорим о самых популярных, среди которых у нас будет RAR или 7z.
Когда мы хотим сжимать файлы, а эта статья посвящена именно этому типу сжатия, а не другим, таким как сжатие видео или аудио, вполне вероятно, что нам понадобится для их файлов . Поэтому, по крайней мере, один из форматов сжатия, включенных в эту статью, будет просто делать это, то есть мы включили тот, который не сжимает, но вы поймете, почему позже.
Содержание
- 1 Самые популярные форматы сжатия
- 1.1 ZIP, быстрый и легкий
- 1.2 ZIPX, эволюция ZIP
- 1.3 TAR в файл …
- 7 6 17 9.4 … И G1Z для сжатия 9.4 … , открытый исходный код и мощный
- 1.6 RAR, лучший, если вам не нужны лицензии
- 1.7 ACE, старая слава
- 2 Какой из этих форматов сжатия является лучшим?
Самые популярные форматы сжатия
ZIP, быстрый и легкий
Как мы уже упоминали, ZIP является очень известным форматом сжатия, отчасти потому, что он является «единственным на всю жизнь» в системах Microsoft . Будучи одним из первых, его со временем обогнали другие форматы, такие как 7z или RAR, но он по-прежнему имеет свои сильные стороны:
- Сжатие в ZIP очень быстрое и не требует много ресурсов, по крайней мере, если сравнивать со сжатием в 7z или RAR.
 Он основан на сжатии Deflate Lossless, что делает его идеальным для архивирования больших объемов комбинированных данных, таких как резервная копия.
Он основан на сжатии Deflate Lossless, что делает его идеальным для архивирования больших объемов комбинированных данных, таких как резервная копия. - ZIP везде. Формат ZIP доступен практически в любой операционной системе, такой как Linux или даже в гораздо более закрытых системах, таких как Apple iOS.
- В последних версиях появилось шифрование AES.
Причинами выбора ZIP в качестве формата сжатия являются скорость , и он отлично работает в любой операционной системе. Другие форматы, хотя и доступны, могут создавать проблемы в некоторых операционных системах, и это случилось со мной при сжатии файлов в 7z в разных местах, начиная с Ark. 9.0003
ZIPX, эволюция ZIP
Если мы говорили о ZIP, мы должны говорить о эволюции того же самого. Это ZIPX, и среди его возможностей у нас есть то, что он сжимает больше, чем ZIP, что-то сравнимое с форматом RAR. Проблема в том, что при использовании ZIPX мы теряем сильные стороны ZIP: компьютер потребляет больше ресурсов и сжатие/распаковка происходит медленнее.
Я бы рекомендовал использовать ZIPX только тогда, когда вы не хотите использовать RAR, то есть по экономическим и лицензионным вопросам.
TAR в файл …
Как мы объясняли ранее, мы собирались упомянуть формат сжатия, который не сжимал. Это TAR, и мы упоминаем его, потому что он часто используется в Linux. S обеспечивает только архивирование (объединение входных данных и метаданных в один выходной файл), делегирование таких функций, как сжатие, шифрование, проверка четности/целостности, внешнему программному обеспечению, которое работает в конвейере с выводом команды TAR.
… И ГЗ сжать
Многие файлы, которые мы загружаем для Linux, имеют формат tar.gz. Расширение GZ обозначает формат сжатия одного файла, созданный для проекта GZip (GNU Zip или «бесплатный Zip»), запущенного в 1992 году Жаном-Лу Гайи и Марком Адлером, чтобы предоставить бесплатную замену решениям для сжатия. проприетарных/коммерческих данных. Сжатие основано на алгоритме DEFLATE (также используется в качестве алгоритма по умолчанию в формате PKZip/WinZip .ZIP), комбинации кодирования Lempel-Ziv (LZ77) и кодирования Хаффмана.
Сжатие основано на алгоритме DEFLATE (также используется в качестве алгоритма по умолчанию в формате PKZip/WinZip .ZIP), комбинации кодирования Lempel-Ziv (LZ77) и кодирования Хаффмана.
Его можно использовать вместо ZIP и, как в случае с ZIPX, для решения проблемы лицензирования, это совершенно бесплатно .
7z, с открытым исходным кодом и мощным
7z — это современный формат сжатия и с открытым исходным кодом . Он предлагает шифрование AES и высокий уровень сжатия, один из лучших, в большинстве случаев выше, чем RAR или ZIPX. Он был представлен в Windows как 7-Zip и портирован командой p7zip на платформы Unix. Поддерживаемые алгоритмы сжатия (LZMA/LZMA2, PPMd, BZip2) могут выиграть от параллельных вычислений на современных многоядерных процессорах.
Основной причиной использования 7z является его высокий уровень сжатия , но это того не стоит, если мы собираемся сжимать большие файлы во время работы, потому что мы будем тратить много времени / ресурсов нашего оборудования. С другой стороны, как я уже говорил, мне не удалось сжать с помощью Ark, так что лично у меня есть заноза в боку, и я не могу ему полностью доверять. Другими словами, 7z может представлять больше проблем, чем другие форматы, такие как ZIP.
С другой стороны, как я уже говорил, мне не удалось сжать с помощью Ark, так что лично у меня есть заноза в боку, и я не могу ему полностью доверять. Другими словами, 7z может представлять больше проблем, чем другие форматы, такие как ZIP.
RAR, лучший вариант, если вам плевать на лицензии
Формат RAR является одним из самых известных, таких как ZIP, отчасти потому, что он также широко используется в системах Microsoft. Это проприетарный формат, представленный WinRAR в Windows, и его извлекающая часть была перенесена в Linux (Unrar). Среди его функций у нас есть:
- Сжимает больше, чем ZIP.
- Предлагает надежное шифрование.
- Возможность восстановления в случае ошибок .
Как и у 7z и ZIPX, одной из его сильных сторон является уровень сжатия, но за это приходится платить затратами времени и ресурсов. Я бы всегда использовал формат RAR в Windows, как для сжатия, так и для разделения и защиты файлов паролем. Конечно, вы должны заплатить за это или делать то, что вы знаете.
Конечно, вы должны заплатить за это или делать то, что вы знаете.
ACE, старая слава
Как и RAR, ACE является проприетарным форматом, представленным в Windows компанией WinACE, но в данном случае это была та же компания, которая перенесла его в Linux, а точнее его возможности извлечения (UNACE). В последние годы он потерял популярность, но предлагает на 90 157 уровней сжатия лучше, чем ZIP, не достигая уровня RAR 90 158, ZIPX или 7z.
Поскольку нет бесплатной или бесплатной версии для создания файлов ACE, Я бы не рекомендовал ее использовать , если у нас нет доступа к лицензии, которая не стоит нам дорого. Если вам нужно выбирать, RAR лучше.
Какой из этих форматов сжатия является лучшим?
Как мы объясняли, это будет зависеть от многих факторов , среди которых совместимость, уровень сжатия и лицензии. Для Linux я бы порекомендовал формат 7z, но не раньше, чем проведем тесты, чтобы убедиться, что мы не нашли какой-либо тип ошибки, подобной той, которую я нашел в Kubuntu с помощью Ark.