Гистограммы и графики распределения в Python / Хабр
Построение графика одной переменной кажется простой задачей. Но насколько это просто в действительности — эффективно отобразить данные со всего одним измерением? Долгое время я обходился стандартной гистограммой, которая показывает расположение значений, разброс и форму распределения данных (нормальное, скошенное, двухпиковое и др). Но недавно я столкнулся со случаем, когда гистограмма не помогла. И тогда понял, что настало время узнать больше о построении графиков. Я нашёл в сети отличную бесплатную книгу о визуализации данных и попробовал некоторые методы. Я решил, что (и мне, и другим людям) будет полезно, если я поделюсь этими знаниями и составлю руководство по построению на Python гистограмм и их крайне полезной альтернативы — графиков распределения плотности (density plots). Подробности — к старту нашего курса по анализу данных.
Я подробно рассмотрю применение гистограмм и графиков распределения в Python при помощи библиотек matplotlib и seaborn.
Перед построением графика всегда полезно изучить данные. Считаем данные во фрейм данных pandas и отобразим первые 10 строк:
import pandas as pd
# Read in data and examine first 10 rows
flights = pd.read_csv('data/formatted_flights.csv')
flights.head(10)Задержки рейсов указаны в минутах. Отрицательные значения означают, что самолёт совершил посадку с опережением графика (они часто его опережают в те самые дни, когда мы никуда не летим!) Всего у нас более 300000 рейсов. Наименьшая задержка составляет минус шестьдесят минут, наибольшая — сто двадцать минут. В другом столбце — названия авиалиний для сравнения.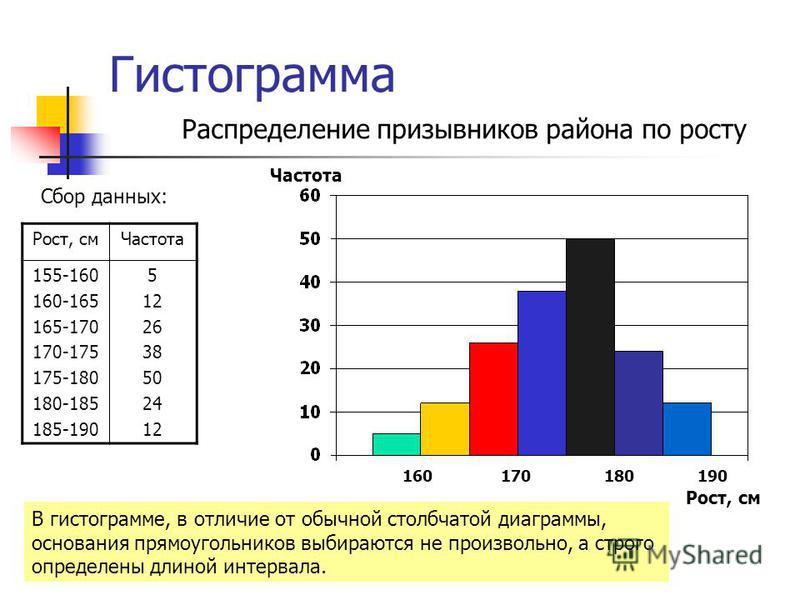
Разумно начать изучение данных с построения гистограммы. При построении гистограммы переменная делится на бины, точки данных подсчитываются в каждом бине, эти бины откладываются по оси x. По оси y откладывается число объектов. Здесь бины отражают диапазон времени задержки рейса, а по y откладывается число рейсов, попавшее в этот интервал. Важнейший параметр гистограммы — ширина бина (binwidth). Всегда стоит попробовать разную ширину и выбрать самую подходящую.
В Python базовую гистограмму может построить или matplotlib, или seaborn. В приведённом ниже коде показаны вызовы функций в обеих библиотеках, которые создают эквивалентные графики. При вызове функции plot мы указываем ширину бина, выраженную в числе бинов. Для этого графика я использую бины длиной 5 минут, что означает, что количество бинов будет равно диапазону данных (от -60 до 120 минут), делённому на ширину бина, 5 минут (
# Import the libraries import matplotlib.pyplot as plt import seaborn as sns # matplotlib histogram plt.hist(flights['arr_delay'], color = 'blue', edgecolor = 'black', bins = int(180/5)) # seaborn histogram sns.distplot(flights['arr_delay'], hist=True, kde=False, bins=int(180/5), color = 'blue', hist_kws={'edgecolor':'black'}) # Add labels plt.title('Histogram of Arrival Delays') plt.xlabel('Delay (min)') plt.ylabel('Flights')
Для базовых гистограмм я использовал бы код matplotlib, поскольку он проще. Но в нашем примере для создания разных распределений мы воспользуемся функцией seaborn distplot. Она хорошо подходит для знакомства с разными вариантами.
Почему я взял за ширину бина 5 минут? Чтобы найти оптимальное значение, нужно попробовать разные варианты! Ниже я привожу код для создания такого же графика в matplotlib с различными значениями ширины бина. В конечном счёте нет верного или неверного ответа на вопрос о его ширине. Я выбрал 5 минут, потому что считаю, что это значение лучше всего отражает распределение.
# Show 4 different binwidths
for i, binwidth in enumerate([1, 5, 10, 15]):
# Set up the plot
ax = plt. subplot(2, 2, i + 1)
# Draw the plot
ax.hist(flights['arr_delay'], bins = int(180/binwidth),
color = 'blue', edgecolor = 'black')
# Title and labels
ax.set_title('Histogram with Binwidth = %d' % binwidth, size = 30)
ax.set_xlabel('Delay (min)', size = 22)
ax.set_ylabel('Flights', size= 22)
plt.tight_layout()
plt.show()
subplot(2, 2, i + 1)
# Draw the plot
ax.hist(flights['arr_delay'], bins = int(180/binwidth),
color = 'blue', edgecolor = 'black')
# Title and labels
ax.set_title('Histogram with Binwidth = %d' % binwidth, size = 30)
ax.set_xlabel('Delay (min)', size = 22)
ax.set_ylabel('Flights', size= 22)
plt.tight_layout()
plt.show()Ширина бина существенно влияет на вид графика. Слишком узкие бины загромождают его, а слишком широкие скрывают нюансы данных. Matplotlib выбирает оптимальную ширину бина автоматически, однако я предпочитаю выбирать значение вручную, перебирая варианты. Поскольку здесь нет ни единственно верного, ни заведомо неправильного выбора, попробуйте разные варианты и посмотрите, какой из них лучше всего подходит к вашему набору данных.
Гистограммы отлично подходят для начала исследования одной переменной, взятой из одной категории. Тем не менее, когда мы хотим сравнить распределения одной переменной по нескольким категориям, гистограммы не всегда удобны для восприятия. Например, если мы хотим сравнить распределения задержек прибытия рейсов разных авиалиний, построение гистограмм на одном графике плохо подходит для этой цели:
Например, если мы хотим сравнить распределения задержек прибытия рейсов разных авиалиний, построение гистограмм на одном графике плохо подходит для этой цели:
(Заметим, что ось y нормализована с учётом различий в количестве рейсов разных авиалиний. Для этого мы используем аргумент norm_hist = True при вызове функции
sns.distplot).
Пользы от такого графика мало! Перекрытие линий делает сравнение авиалиний практически невыполнимой задачей. Рассмотрим варианты решения этой задачи.
Вариант 1. Сравнительные гистограммы (Side-by-Side Histograms)
Вместо наложения гистограмм друг на друга мы можем расположить их рядом. Для этого создадим списки (list) задержек рейсов по авиалиниям, а затем передадим вызываемой функции plt.hist список таких списков. Разным авиалиниям мы присвоим разные цвета (color) и наименования (name), чтобы их проще было отличить друг от друга. Всё это, начиная с создания списков, делает вот такой код:
# Make a separate list for each airline x1 = list(flights[flights['name'] == 'United Air Lines Inc.']['arr_delay']) x2 = list(flights[flights['name'] == 'JetBlue Airways']['arr_delay']) x3 = list(flights[flights['name'] == 'ExpressJet Airlines Inc.']['arr_delay']) x4 = list(flights[flights['name'] == 'Delta Air Lines Inc.']['arr_delay']) x5 = list(flights[flights['name'] == 'American Airlines Inc.']['arr_delay']) # Assign colors for each airline and the names colors = ['#E69F00', '#56B4E9', '#F0E442', '#009E73', '#D55E00'] names = ['United Air Lines Inc.', 'JetBlue Airways', 'ExpressJet Airlines Inc.'', 'Delta Air Lines Inc.', 'American Airlines Inc.'] # Make the histogram using a list of lists # Normalize the flights and assign colors and names plt.hist([x1, x2, x3, x4, x5], bins = int(180/15), normed=True, color = colors, label=names) # Plot formatting plt.legend() plt.xlabel('Delay (min)') plt.ylabel('Normalized Flights') plt.title('Side-by-Side Histogram with Multiple Airlines')
По умолчанию при передаче списка списков matplotlib размещает столбцы вплотную. В данном случае я изменил ширину бина до 15 минут, чтобы не перегружать график. Но даже с такой модификацией этот график неэффективен. Слишком много информации нужно обрабатывать одновременно, положение столбцов не совпадает с их метками, и сравнить распределения данных по авиалиниям всё равно сложно. Построение графика предполагает простоту интерпретации зрителем. Нам это не удалось! Давайте рассмотрим второй вариант решения.
В данном случае я изменил ширину бина до 15 минут, чтобы не перегружать график. Но даже с такой модификацией этот график неэффективен. Слишком много информации нужно обрабатывать одновременно, положение столбцов не совпадает с их метками, и сравнить распределения данных по авиалиниям всё равно сложно. Построение графика предполагает простоту интерпретации зрителем. Нам это не удалось! Давайте рассмотрим второй вариант решения.
Вариант 2. Столбчатые графики (Stacked Bars)
Вместо построения столбцов данных рядом мы можем расположить их друг над другом при помощи параметра stacked = True при вызове гистограммы:
# Stacked histogram with multiple airlines
plt.hist([x1, x2, x3, x4, x5], bins = int(180/15), stacked=True,
normed=True, color = colors, label=names)Этот вариант ничуть не лучше! В каждом бине представлены доли всех авиалиний, однако сравнить их всё ещё невозможно. Вот например, у кого больше доля в бине от -15 до 0 минут: у United Air Lines или же у JetBlue Airlines? Я этого пока не знаю и аудитория тоже.
Для начала — что это за графики? График распределения можно назвать непрерывным сглаженным аналогом гистограммы. Самый распространённый вариант построения такого графика — ядерная оценка плотности. В этом методе для каждой точки данных строится непрерывная кривая — ядро. Все эти кривые складываются вместе, чтобы получить единую гладкую оценку плотности. Чаще всего используется гауссово ядро (которое даёт колоколообразную кривую Гаусса в каждой точке данных). Если вы, как и я, находите это описание немного запутанным, взгляните на следующий график:
Ядерная оценка плотности (Источник)
Каждый чёрный вертикальный штрих у оси x представляет точку данных. Отдельные ядра (в данном случае — гауссовы) построены над каждой точкой красными пунктирными линиями. Их суммирование даёт общий график распределения, показанный сплошной синей линией.
Их суммирование даёт общий график распределения, показанный сплошной синей линией.
По оси x здесь, как и на гистограмме, откладывается значение переменной. Но что показывает ось y? Ось y на графике плотности — это функция плотности вероятности для ядерной оценки плотности. Нужно помнить, что это именно плотность вероятности, а не сама вероятность. Разница между ними заключается в том, что плотность вероятности — это вероятность на единицу по оси x. Для преобразования этих данных в обычную вероятность нам нужно найти площадь под кривой для определённого интервала на оси x. Несколько смущает то, что поскольку это плотность вероятности, а не вероятность, ось y может принимать значения больше единицы. Единственное требование к графику плотности — чтобы общая площадь под кривой интегрировалась в единицу. Я привык рассматривать ось y на графике распределения как величину, применимую только для относительных сравнений между категориями.
Графики распределения в Seaborn
При построении графиков распределения в seaborn можно использовать функцию distplot или kdeplot.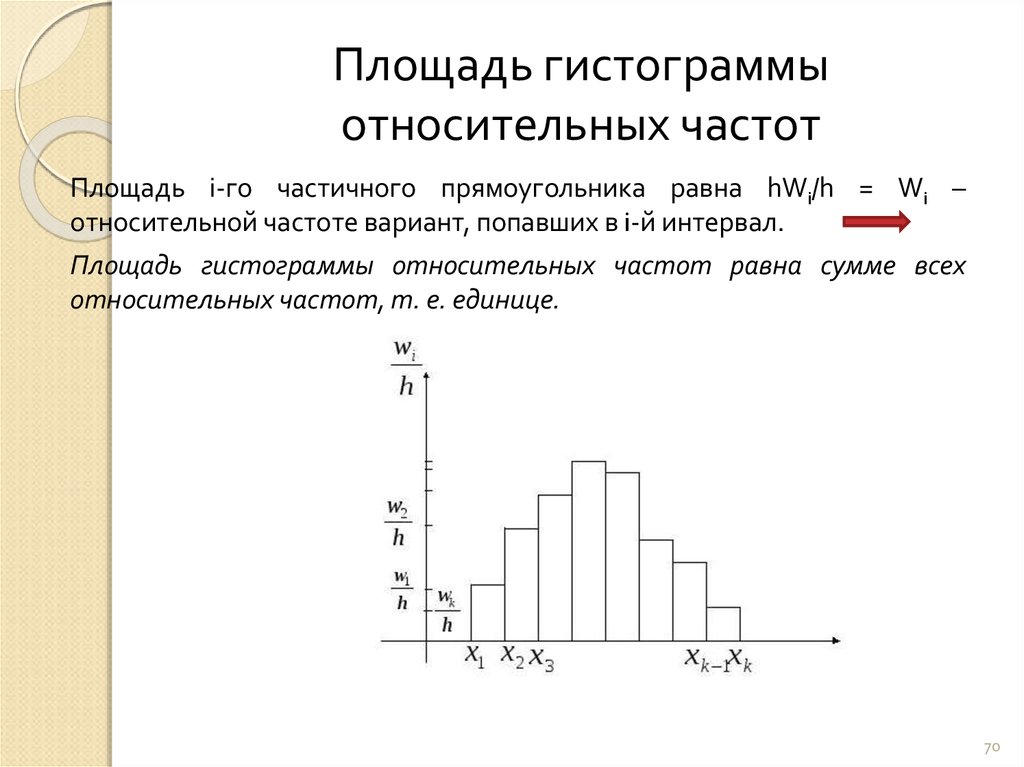 Я снова использую
Я снова использую distplot, ведь он строит несколько распределений одним вызовом функции. Например, можно построить график распределения задержек всех рейсов поверх соответствующей гистограммы:
# Density Plot and Histogram of all arrival delays
sns.distplot(flights['arr_delay'], hist=True, kde=True,
bins=int(180/5), color = 'darkblue',
hist_kws={'edgecolor':'black'},
kde_kws={'linewidth': 4})График распределения и гистограмма, построенные при помощи seaborn
Кривая — график распределения, который, по сути, является сглаженным аналогом гистограммы. По оси y откладывается плотность. Гистограмма по умолчанию нормализована. Поэтому её масштаб по оси y соответствует масштабу графика распределения.
У графика распределения есть величина, аналогичная ширине бина в гистограмме. Её называют шириной полосы пропускания (bandwidth). Эта величина позволяет изменить отдельные ядра и значительно влияет на общий вид графика. Библиотека построения графиков (plotting library) позволяет выбрать ширину полосы пропускания (по умолчанию используется «оценка по Скотту» (scott)). В отличие от гистограмм здесь я обычно полагаюсь на значение по умолчанию. Тем не менее ничто не мешает нам попробовать разную ширину полосы и выбрать оптимальную. Значение по умолчанию на этом графике, ‘scott’, действительно выглядит как наилучший вариант.
Библиотека построения графиков (plotting library) позволяет выбрать ширину полосы пропускания (по умолчанию используется «оценка по Скотту» (scott)). В отличие от гистограмм здесь я обычно полагаюсь на значение по умолчанию. Тем не менее ничто не мешает нам попробовать разную ширину полосы и выбрать оптимальную. Значение по умолчанию на этом графике, ‘scott’, действительно выглядит как наилучший вариант.
График распределения плотностей, показывающий различные полосы пропускания
Заметим, что с увеличением полосы пропускания распределение становится более сглаженным. Мы также видим, что, несмотря на ограничение данных от -60 до 120 минут, график плотности выходит за эти пределы. Это одна из возможных проблем графика плотности. Поскольку мы строим распределение в каждой точке данных, генерируемые данные могут выходить за рамки исходного диапазона. Таким образом, мы получаем на оси x нереалистичные значения, которых не было в исходном наборе данных! Мы также можем изменить ядро, что, в свою очередь, изменит распределение в каждой точке. Тем не менее в большинстве случаев ядро Гаусса по умолчанию и стандартная оценка полосы пропускания работают хорошо.
Тем не менее в большинстве случаев ядро Гаусса по умолчанию и стандартная оценка полосы пропускания работают хорошо.
Вариант 3. График распределения
Теперь мы знаем, что представляет собой график распределения плотностей. Посмотрим, поможет ли он визуализировать задержки рейсов разных авиалиний. Чтобы показать эти распределения на одном графике, мы можем перебрать все авиалинии, каждый раз вызывая distplot. При этом мы присвоим параметру kde (kernel density estimate, ядерная оценка плотности) значение True, а параметру hist (гистограмма) — значение False. Код для построения графика распределения для множества авиалиний приведён ниже:
# List of five airlines to plot
airlines = ['United Air Lines Inc.', 'JetBlue Airways', 'ExpressJet Airlines Inc.'',
'Delta Air Lines Inc.', 'American Airlines Inc.']
# Iterate through the five airlines
for airline in airlines:
# Subset to the airline
subset = flights[flights['name'] == airline]
# Draw the density plot
sns.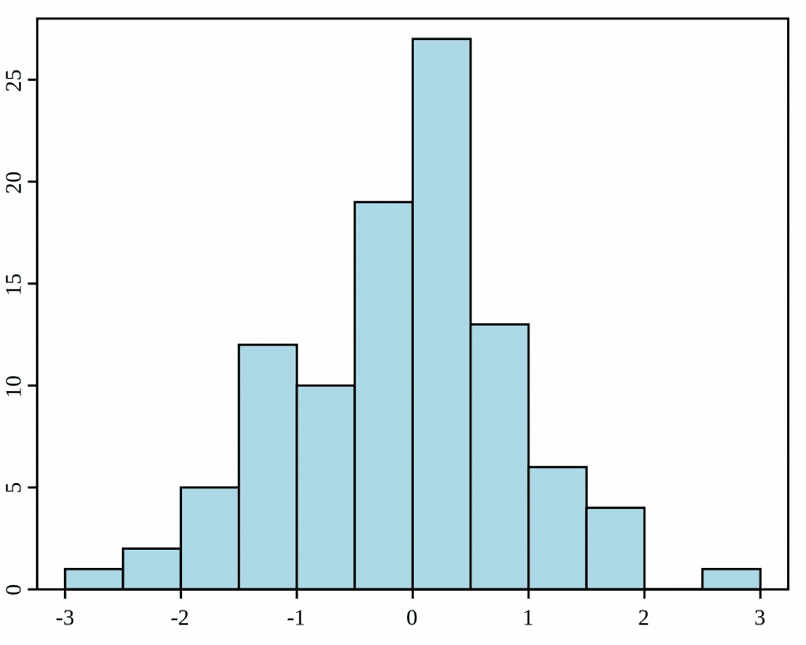 distplot(subset['arr_delay'], hist = False, kde = True,
kde_kws = {'linewidth': 3},
label = airline)
# Plot formatting
plt.legend(prop={'size': 16}, title = 'Airline')
plt.title('Density Plot with Multiple Airlines')
plt.xlabel('Delay (min)')
plt.ylabel('Density')
distplot(subset['arr_delay'], hist = False, kde = True,
kde_kws = {'linewidth': 3},
label = airline)
# Plot formatting
plt.legend(prop={'size': 16}, title = 'Airline')
plt.title('Density Plot with Multiple Airlines')
plt.xlabel('Delay (min)')
plt.ylabel('Density')Наконец-то мы нашли эффективное решение! Этот график в меньшей степени загромождён, что позволяет проводить сравнения. Получив желанный график, мы можем сделать вывод. Рейсы всех этих авиалиний задерживаются почти одинаково: нет в жизни счастья! Но в нашем наборе данных есть и другие авиалинии, и мы можем построить немного другой график, который покажет ещё один дополнительный параметр графиков распределения плотности — затенение графика (shading).
Графики распределения с затенением (Shaded Density Plots)
Заполнение графика распределения плотностей позволяет нам различать перекрывающиеся распределения. Этот подход не всегда оправдан, но он может подчеркнуть разницу распределений. Чтобы затенять графики плотности, мы передаём
Чтобы затенять графики плотности, мы передаём shade = True в аргументе kde_kws при вызове функции distplot.
sns.distplot(subset['arr_delay'], hist = False, kde = True,
kde_kws = {'shade': True, 'linewidth': 3},
label = airline)Затенять или не затенять — вот в чём вопрос… И ответ на него зависит от решаемой задачи! В нашем случае затенение не лишено смысла, поскольку помогает нам рассмотреть оба графика в области их перекрытия. Наконец, мы получили полезную информацию: рейсы Alaska Airlines показывают тенденцию к опережению графика чаще, чем United Airlines. Теперь вы знаете, чьи рейсы выбирать!
Штрих-диаграммы (Rug Plots)
Если вы хотите увидеть каждое значение в распределении, а не только сглаженный график плотности, вам также пригодится штрих-диаграмма.
В русском языке термин «штрих-диаграмма» обычно используется для графиков, которые строят при расшифровке рентгенограмм.Однако, по сути, там тот же принцип построения: штрихи проставляются вдоль оси абсцисс. Термин же «ковровая диаграмма», более близкий к англоязычной формулировке, в русском языке означает совершенно другой график в трёхмерном пространстве.
Она показывает каждую точку на оси x и визуализирует все исходные значения. Преимущество использования distplot в seaborn — возможность добавления штрих-диаграммы при вызове rug = True с одним параметром (и небольшим форматированием).
# Subset to Alaska Airlines
subset = flights[flights['name'] == 'Alaska Airlines Inc.']
# Density Plot with Rug Plot
sns.distplot(subset['arr_delay'], hist = False, kde = True, rug = True,
color = 'darkblue',
kde_kws={'linewidth': 3},
rug_kws={'color': 'black'})
# Plot formatting
plt.title('Density Plot with Rug Plot for Alaska Airlines')
plt.xlabel('Delay (min)')
plt.ylabel('Density')Если точек данных много, штрих-диаграмма становится слишком сложной, однако она полезна в некоторых проектах, так как позволяет увидеть каждую точку данных. Штрих-диаграмма также наглядно показывает, как график распределения «создаёт» данные там, где их нет. Это связано с распределением ядерной оценки плотности в каждой точке данных. Это распределение может выходить за рамки начального диапазона данных, создавая впечатление, что некоторые рейсы Alaska Airlines прибывают и раньше и позже, чем в действительности. Нужно помнить об этой иллюзии и информировать о ней аудиторию!
Штрих-диаграмма также наглядно показывает, как график распределения «создаёт» данные там, где их нет. Это связано с распределением ядерной оценки плотности в каждой точке данных. Это распределение может выходить за рамки начального диапазона данных, создавая впечатление, что некоторые рейсы Alaska Airlines прибывают и раньше и позже, чем в действительности. Нужно помнить об этой иллюзии и информировать о ней аудиторию!
Смею надеяться, что в этом посте я перечислил набор полезных для вас вариантов визуализации значений одной переменной для одной и более категорий. Мы могли бы построить и другие одномерные («однопеременные») графики: эмпирические графики кумулятивной плотности (empirical cumulative density plots) и графики квантиль-квантиль (quantile-quantile plots). Однако в этой статье остановимся на гистограммах и графиках распределения (со штрих-диаграммами!). Если даже эти варианты кажутся вам слишком сложными, не отчаивайтесь. После некоторой практики вам станет проще сделать правильный выбор. Если потребуется, вы всегда можете обратиться за помощью. Более того, часто оптимального выбора не существует, а «верное» решение зависит и от личных предпочтений, и от цели визуализации данных. Но, какой бы график вы ни выбрали, вы всегда сможете построить его же Python! Визуальная подача доходчива, а зная все возможные варианты, мы всегда сможем выбрать наилучший график для нашего набора данных.
Если потребуется, вы всегда можете обратиться за помощью. Более того, часто оптимального выбора не существует, а «верное» решение зависит и от личных предпочтений, и от цели визуализации данных. Но, какой бы график вы ни выбрали, вы всегда сможете построить его же Python! Визуальная подача доходчива, а зная все возможные варианты, мы всегда сможем выбрать наилучший график для нашего набора данных.
Любая обратная связь и конструктивная критика приветствуются. Меня можно найти в Twitter @koehrsen_will.
Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом:
- Профессия Data Analyst
- Профессия Data Scientist (24 месяца)
Краткий каталог курсов
Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
- Профессия iOS-разработчик
- Профессия Android-разработчик
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
- Курс «Алгоритмы и структуры данных»
- Профессия C++ разработчик
- Профессия «Белый хакер»
А также
- Курс по DevOps
- Все курсы
Новое в системе Wolfram Language 11
‹›Улучшенная геовизуализация
Для каждого из 50 самых загруженных аэропортов Европы взвесьте расположение аэропорта согласно количеству пассажиров, которое он обслуживает.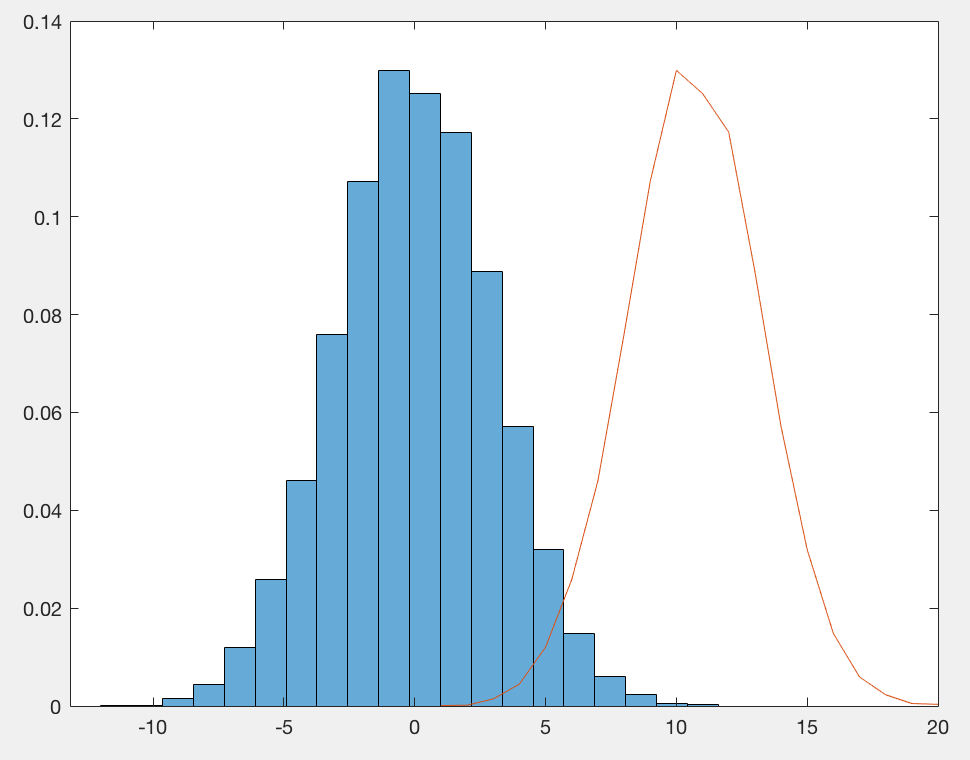
In[1]:=
data = {Entity[
"City", {"London", "GreaterLondon", "UnitedKingdom"}] ->
74985748,
Entity["City", {"Paris", "IleDeFrance", "France"}] -> 65766986,
Entity["City", {"Istanbul", "Istanbul", "Turkey"}] -> 61322729,
Entity["City", {"Frankfurt", "Hesse", "Germany"}] -> 61032022,
Entity["City", {"Amsterdam", "NoordHolland", "Netherlands"}] ->
58285118,
Entity["City", {"Madrid", "Madrid", "Spain"}] -> 46828279,
Entity["City", {"Munich", "Bavaria", "Germany"}] -> 40981522,
Entity["City", {"London", "GreaterLondon", "UnitedKingdom"}] ->
40269087, Entity["City", {"Rome", "Lazio", "Italy"}] -> 40233507,
Entity["City", {"Barcelona", "Barcelona", "Spain"}] -> 39711276,
Entity["City", {"Moscow", "Moscow", "Russia"}] -> 31279508,
Entity["City", {"Moscow", "Moscow", "Russia"}] -> 30504515,
Entity["City", {"Paris", "IleDeFrance", "France"}] -> 29664993,
Entity["City", {"Istanbul", "Istanbul", "Turkey"}] -> 28112438,
Entity["City", {"Antalya", "Antalya", "Turkey"}] -> 27724249,
Entity["City", {"Copenhagen", "Copenhagen", "Denmark"}] ->
26610332,
Entity["City", {"Zurich", "Zurich", "Switzerland"}] -> 26281228,
Entity["City", {"Dublin", "Dublin", "Ireland"}] -> 25049335,
Entity["City", {"Oslo", "Oslo", "Norway"}] -> 24678195,
Entity["City", {"Palma", "Balears", "Spain"}] -> 23745131,
Entity["City", {"Brussels", "Brussels", "Belgium"}] -> 23460018,
Entity["City", {"Stockholm", "Stockholm", "Sweden"}] -> 23142536,
Entity["City", {"Manchester", "Manchester", "UnitedKingdom"}] ->
23136047,
Entity["City", {"Vienna", "Vienna", "Austria"}] -> 22775054,
Entity["City", {"London", "GreaterLondon", "UnitedKingdom"}] ->
22519178,
Entity["City", {"Dusseldorf", "NorthRhineWestphalia",
"Germany"}] -> 22476685,
Entity["City", {"Berlin", "Berlin", "Germany"}] -> 21005196,
Entity["City", {"Lisbon", "Lisboa", "Portugal"}] -> 20090418,
Entity["City", {"Milan", "Lombardy", "Italy"}] -> 18582043,
Entity["City", {"Athens", "Attiki", "Greece"}] -> 18086894,
Entity["City", {"Helsinki", "Uusimaa", "Finland"}] -> 16422266,
Entity["City", {"Moscow", "Moscow", "Russia"}] -> 15815129,
Entity["City", {"Geneva", "Geneva", "Switzerland"}] -> 15772081,
Entity["City", {"Hamburg", "Hamburg", "Germany"}] -> 15610072,
Entity["City", {"Malaga", "Malaga", "Spain"}] -> 1440417,
Entity["City", {"SaintPetersburg", "SaintPetersburg", "Russia"}] ->
13501454,
Entity["City", {"Ankara", "Ankara", "Turkey"}] -> 12326869,
Entity["City", {"London", "GreaterLondon", "UnitedKingdom"}] ->
12263505,
Entity["City", {"Izmir", "Izmir", "Turkey"}] -> 12139788,
Entity["City", {"Prague", "Prague", "CzechRepublic"}] -> 12030928,
Entity["City", {"Nice", "ProvenceAlpesCoteDAzur", "France"}] ->
1201673,
Entity["City", {"Warsaw", "Mazowieckie", "Poland"}] -> 1120670,
Entity["City", {"Edinburgh", "Edinburgh", "UnitedKingdom"}] ->
11114587,
Entity["City", {"LasPalmas", "LasPalmas", "Spain"}] -> 10627182,
Entity["City", {"Alicante", "Alacant", "Spain"}] -> 10574484,
Entity["City", {"Stuttgart", "BadenWurttemberg", "Germany"}] ->
10512225,
Entity["City", {"Milan", "Lombardy", "Italy"}] -> 10404625,
Entity["City", {"Cologne", "NorthRhineWestphalia", "Germany"}] ->
10338375,
Entity["City", {"Budapest", "Budapest", "Hungary"}] -> 10298963,
Entity["City", {"Birmingham", "Birmingham", "UnitedKingdom"}] ->
10187122};Создайте гистограмму, сложив количество пассажиров всех аэропортов для каждой страны.
In[2]:=
GeoHistogram[data, "Country", ColorFunction -> "Rainbow",
PlotLegends -> Automatic, ImageSize -> 450, GeoZoomLevel -> 4,
GeoRange -> Entity["GeographicRegion", "Europe"]]Out[2]=
гистограмм
Гистограммы, частотные распределения и гистограммы
Частотные распределения, гистограммы и Круговые диаграммы
частота конкретного события — это количество раз что событие происходит. относительная частота является доля наблюдаемых ответов в категории.
Пример: Мы спросили учащихся, какой страны их машина.
из (или без машины) и подсчитайте ответы. Затем мы вычислили
частота и относительная частота каждой категории. Относительная
частота вычисляется путем деления частоты на общее количество
респонденты. Следующая таблица
резюмирует.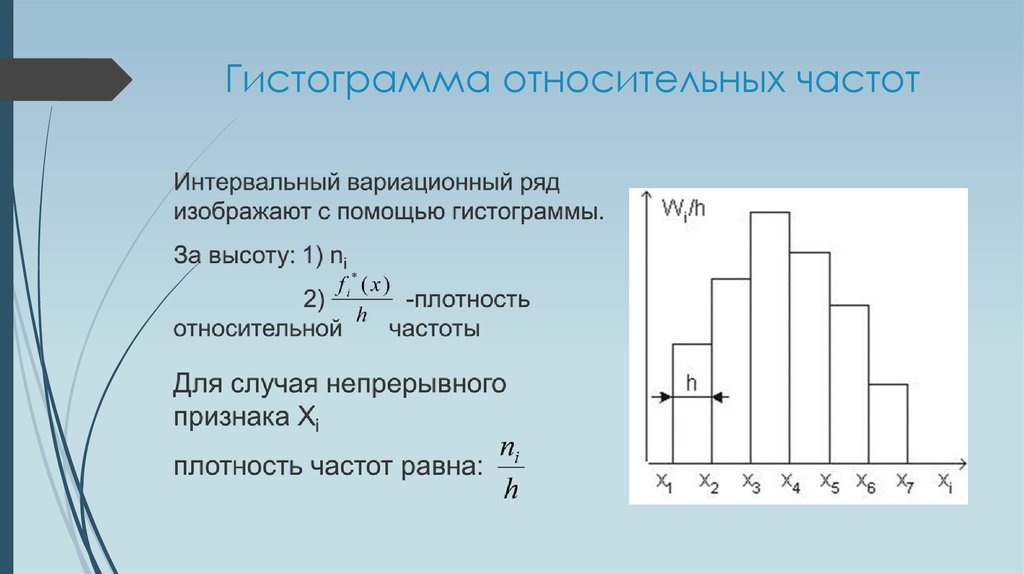
| Страна | Частота | Относительная частота |
| США | 6 | 0,3 |
| Япония | 7 | 0,35 |
| Европа | 2 | 0,1 |
| Корея | 1 | 0,05 |
| Нет | 4 | 0,2 |
| Итого | 20 | 1 |
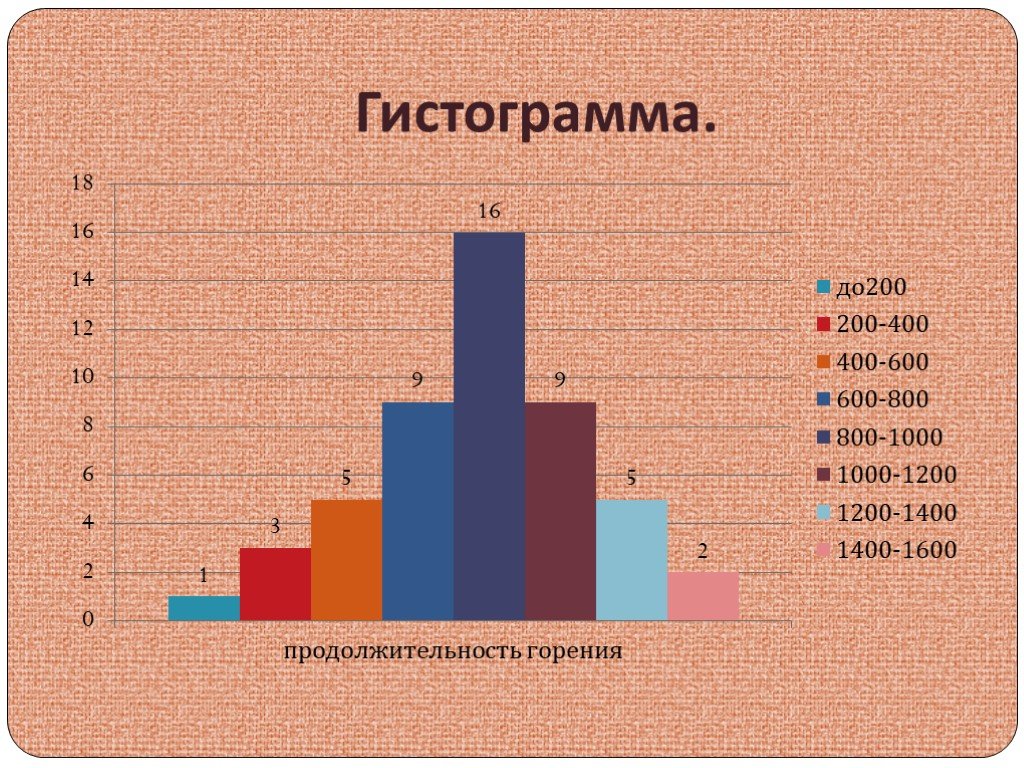
Ниже приведена гистограмма для данных автомобиля. Эта гистограмма называется Парето . диаграмма , так как высота представляет собой частоту. Обратите внимание, что ширина бары всегда одинаковые.
Мы делаем круговую диаграмму часто
назвал круговую диаграмму этих данных, поместив
клинья в круге пропорционального размера частотам.
Ниже представляет собой круговую диаграмму, показывающую эти данные.
чтобы найти углы каждого из срезов мы используем формулу
Частота
Угол
«=»
х 360
Всего
Например, чтобы найти угол для автомобилей США, у нас есть
6
Угол =
х 360 = 108 градусов
20
Гистограммы
Гистограммы столбчатые графики, вертикальной координатой которых является частота, а горизонтальной координата соответствует числовому интервалу.
Пример:
Глубина прозрачности озера Тахо была измерена в нескольких разных местах с результаты в дюймах следующие:
15,4, 16,7, 16,9, 17,0, 20,2, 25,3, 28,8, 29,1, 30,4, 34,5,
36,7, 39,1, 39,4, 39,6, 39,8, 40,1, 42,3, 43,5, 45,6,
45. 9,
9,
48.3, 48.5, 48.7, 49.0, 49.1, 49.3, 49.5, 50.1, 50.2, 52.3
Мы используем таблицу распределения частот с интервалами классов длиной 5,
| Интервал класса | Частота | Относительная частота | Суммарная относительная частота |
| 15 —<20 | 4 | 0,129 | 0,129 |
| 20 —<25 | 1 | 0,032 | 0,161 |
| 25 —< 30 | 3 | 0,097 | 0,258 |
| 30 —< 35 | 2 | 0,065 | 0,323 |
| 35 —< 40 | 6 | 0,194 | 0,516 |
| 40 —< 45 | 3 | 0,097 | 0,613 |
| 45 —< 50 | 9 | 0,290 | 0,903 |
| 50 —< 55 | 3 | 0,097 | 1.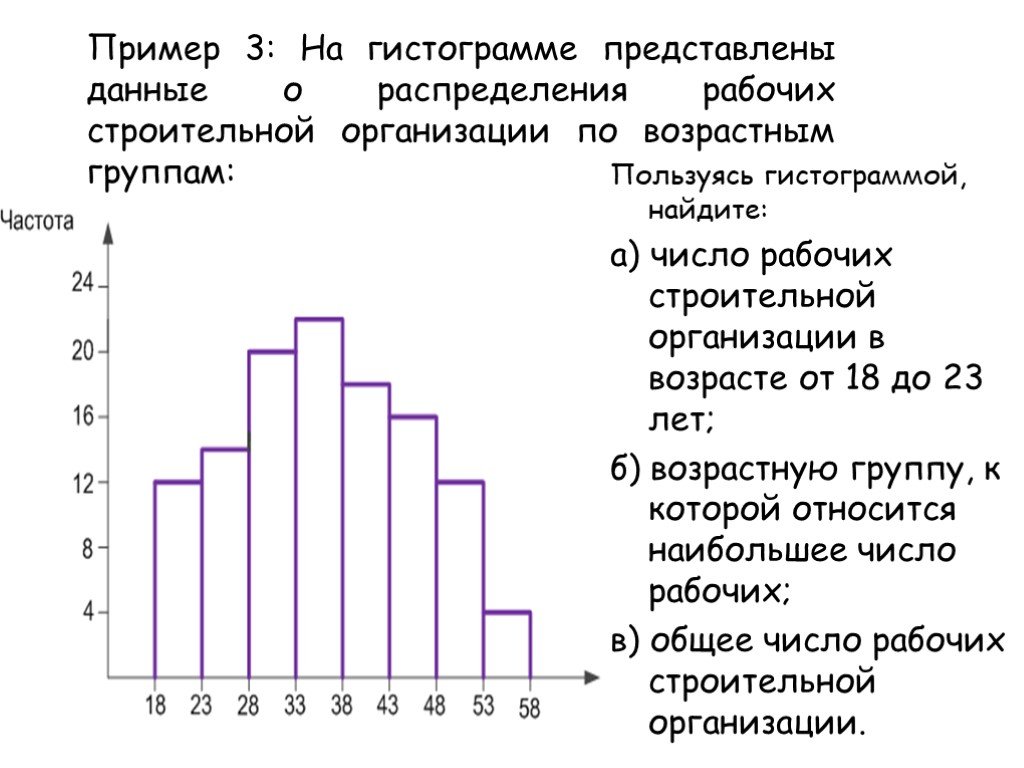 000 000 |
| Итого | 31 | 1.000 |
Ниже приведен график гистограммы
Форма гистограммы
Гистограмма унимодальная , если она есть горб, бимодальный если есть два горба и мультимодальные если есть много горбов. А несимметричная гистограмма называется перекошенной , если она несимметрична. Если верхний хвост длиннее нижнего хвоста, то это положительно перекос . Если верхний хвост короче отрицательно перекос .
Одномодальный, Симметричный, без перекоса
Несимметричный, Перекошено вправо
Бимодальный
Назад на главную страницу описательной статистики
Назад к элементарной статистике (Math 201) Домашняя страница
Назад к математике Домашняя страница отдела
электронная почта Вопросы и предложения
Построение гистограммы — Tableau
Применимо к: Tableau Desktop
Гистограмма — это диаграмма, отображающая форму распределения. Гистограмма выглядит как столбчатая диаграмма, но значения непрерывной меры группируются в диапазоны или интервалы.
Гистограмма выглядит как столбчатая диаграмма, но значения непрерывной меры группируются в диапазоны или интервалы.
Основные строительные блоки гистограммы следующие:
|
Маркировка типа : |
Автомат |
|
Полка рядов : |
Непрерывная мера (объединенная с помощью Count или Count Distinct) |
|
Полка для колонн : |
Бин (непрерывный или дискретный). Примечание : этот интервал должен быть создан из непрерывной меры на полке строк. Дополнительные сведения о том, как создать корзину из непрерывной меры, см. в разделе Создание корзин из непрерывной меры (ссылка открывается в новом окне). |
В Tableau вы можете создать гистограмму, используя Show Me.
-
Подключитесь к источнику данных Sample — Superstore .
-
Перетащите количество в столбцы.
-
Нажмите «Показать» на панели инструментов, затем выберите тип гистограммы.
Тип диаграммы гистограммы доступен в Show Me, если представление содержит одну меру и не содержит измерений.
После нажатия значка гистограммы в Show Me происходят три вещи:
-
Представление изменится, и на нем появятся вертикальные полосы с непрерывной осью X (1–14) и непрерывной осью Y (0–5000).
-
Мера количества, которую вы разместили на полке столбцов, которая была агрегирована как СУММА, заменена непрерывным измерением количества (бин). (Зеленый цвет поля на полке Столбцы указывает на то, что поле непрерывное.)
Чтобы отредактировать эту подборку: На панели данных щелкните правой кнопкой мыши подборку и выберите «Редактировать».
-
Мера Quantity перемещается на полку Rows, а агрегирование изменяется с SUM на CNT (Count).
Мера «Количество» фиксирует количество товаров в определенном заказе. Гистограмма показывает, что около 4800 заказов содержали два товара (второй столбец), около 2400 заказов содержали 4 товара (третий столбец) и так далее.
Давайте сделаем еще один шаг в этом представлении и добавим сегмент к цвету, чтобы увидеть, можем ли мы определить взаимосвязь между потребительским сегментом (потребительским, корпоративным или домашним офисом) и количеством товаров в заказе.
-
-
Перетащите сегмент в цвет.
Цвета не имеют четкой тенденции. Давайте покажем процент каждого бара, который принадлежит каждому сегменту.
-
Удерживая нажатой клавишу Ctrl, перетащите поле CNT (количество) с полки «Строки» на «Метка».

Удерживая нажатой клавишу Ctrl, поле копируется в новое место, не удаляя его из исходного положения.
-
Щелкните правой кнопкой мыши (удерживая клавишу Control на Mac) поле CNT (количество) на карточке «Метки» и выберите «Быстрый расчет таблицы» > «Процент от общего».
Теперь каждая цветная часть каждой полосы показывает соответствующий процент от общего количества:
Но мы хотим, чтобы проценты были для каждого бара.
-
Еще раз щелкните правой кнопкой мыши поле CNT (количество) в карточке Marks и выберите Edit Table Calculation.
-
В диалоговом окне «Вычисление таблицы» измените значение поля «Вычислить с помощью» на «Ячейка».
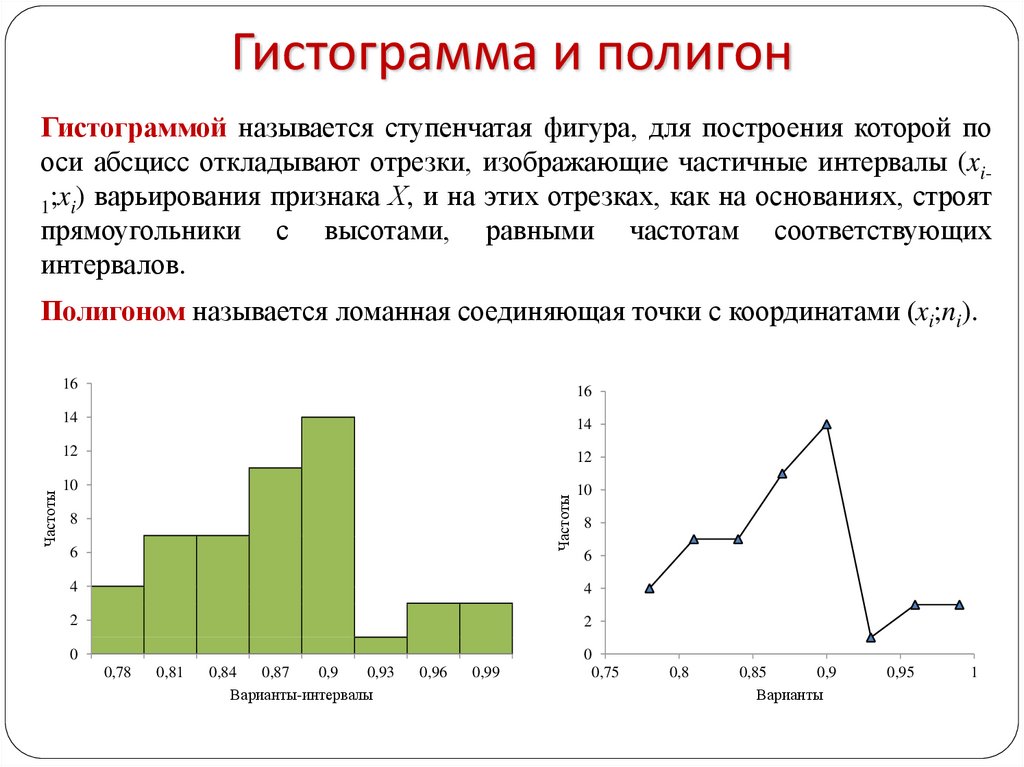
 Гистограмм: Что такое гистограмма и как построить этот график: когда используется, какие есть виды и типы
Гистограмм: Что такое гистограмма и как построить этот график: когда используется, какие есть виды и типы